Linux内核笔记007 - 内存管理的进一步封装
内存管理学习到现在这个阶段,虽然内容又长又抽象,但其实仅仅才是整个高楼大厦中埋在地里的那部分,包括:
Linux内核笔记001、Linux内核笔记002,说明了Intel 80386 CPU为内存管理提供的硬件特性;Linux内核笔记004、Linux内核笔记005、Linux内核笔记006,说明了Linux内核按"页面"为单位,对各个进程的虚拟内存空间、对整个系统的物理内存空间和交换分区的基础管理。而实际应用场景,需要利用这些最基础的方式,封装更多的内存管理方式。
根据我个人的总结,实际应用一般包括两种场景:
- 批发型
基于以"页"为单位的已有管理接口,向系统"批发"内存,再以更灵活粒度的实现一层分配接口。
比如libc库中的malloc()函数,分配粒度完全自由。
malloc(100); /* 如果独占1个页面,浪费3996字节空间 */ malloc(5000); /* 如果独占2个页面,浪费3192字节空间 */

除了这两个例子,应用层根据不同的业务需要,还有很多其它的内存管理思路,内核层本身也封装了各种基于"页"管理之上的内存使用接口,比如: kmalloc()、vmalloc()、slab等。
- 映射型
映射指的是内存空间和IO空间之间的映射,通过内存访问的方式,读写磁盘和各种其它外设。
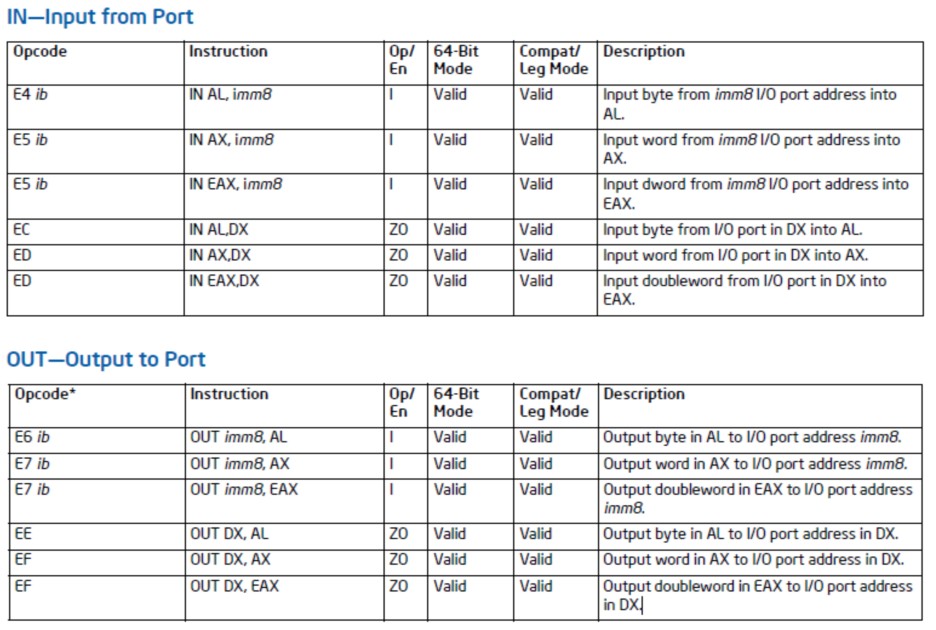
一方面为了突破硬件的限制:Intel x86系统CPU虽然提供了IN、OUT指令,用于访问I/O空间,但是通过查询Intel手册可以知道,用于传递IO地址的参数,是8位的立即数或16位的DX寄存器,即最多可以寻址64K的I/O空间,随着电脑同时能接的外设越来越多,以及各种新型外设的功能越来越丰富,即对外的寄存器越来越多,64K的I/O寻址能力已经远远不够用了,针对这种情况,内核实现了ioremap()函数,可以将I/O空间映射到内存空间,对外设进行操作。
另一方面就是为了丰富功能:比如文件映射,应用层使用mmap()系统调用,内核层相应实现了sys_mmap2()函数。
1. 内核缓冲区的管理
- slab特点
① 需要某种对象时,并不直接分配这种对象,而是先分配slab对象,然后将slab对象的对象区,用于最终对象,并且整个所需的对象,可以由多个slab承载,slab之间用链表相连。这样便于扩充和回收,比如流量处理程序,在上网高峰期,启动时默认分配的100万个session就不够用了,就需要扩充session缓冲池的大小,上网低峰期,可能20万个session就足够了,剩余空闲的,就可以释放给系统;
② mem_zone的道理相同,为了可以方便的合并连续页面,每个slab占用2^n个连续页面块,最多也不超过32个页面;
③ 每个slab有一个空闲对象链数组,它和对象区数组的大小一致,free成员为第一个空闲对象的下标,同时空闲对象链数组的该下标处,为对象区中下一个空闲对象的下标,直接为BUFCTL_END,slab分配/释放对象时,空闲对象链数组也会相应更新;
④ 为了加快空闲对象的查找速度,slab的实现始终保持:同一个kmem_cache_s结构上挂的slab,根据使用情况划为三截,第一截中的slab,包含的对象为全部使用,第二截中的slab,包含的对象为部分使用,第三截中的slab,包含的对象为全部空闲。
这些特点,相比malloc(),在性能和缓解内存碎片方面是有优势的,不过malloc()侧重的是灵活的分配粒度,所以在这两点上有些牺牲,完全是情有可原的。
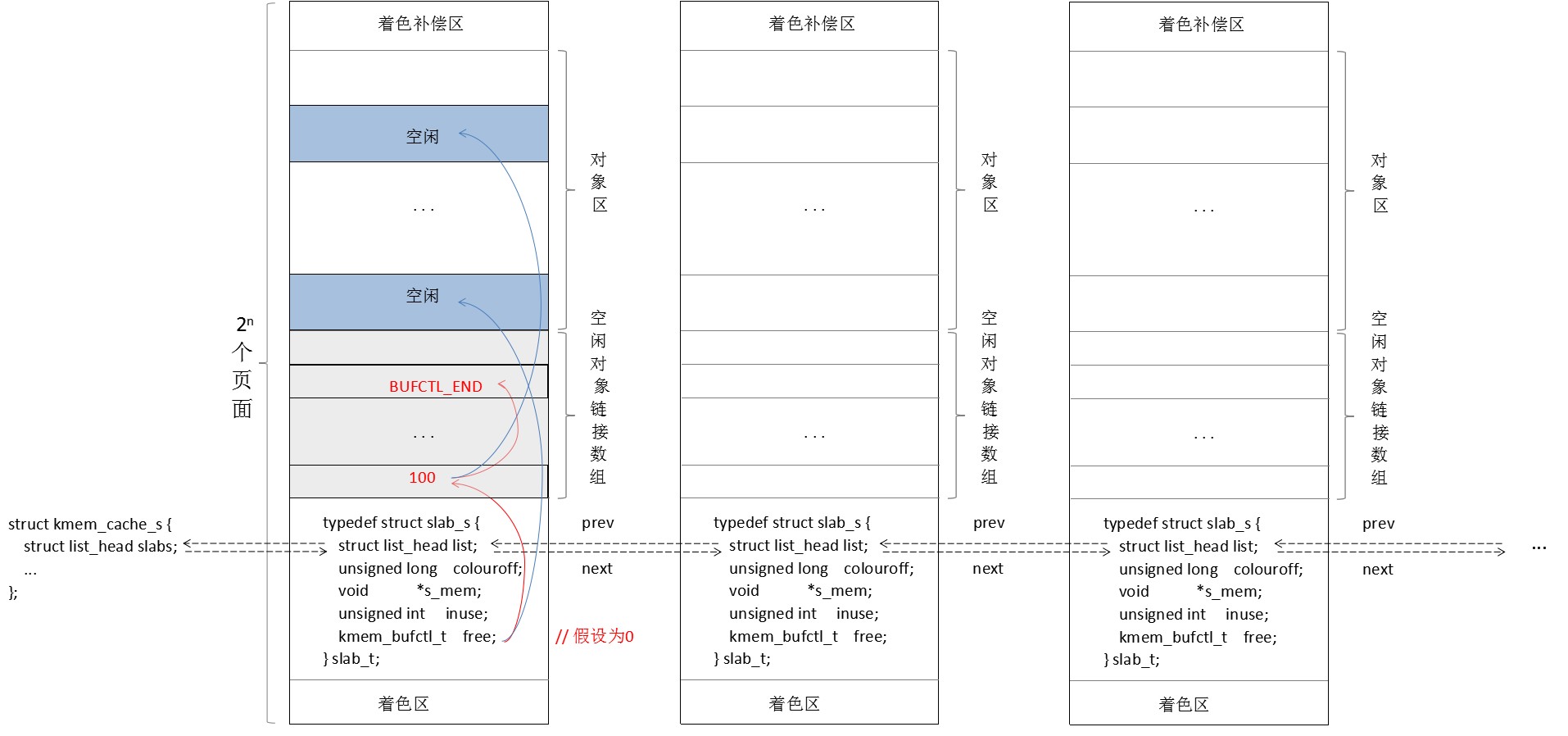
- 着色区
书上简单提了一下,着色区可以提高缓冲行命中,但没有过多解释为什么可以提高命中,所以仍然是写点我个人的理解:
我记不清就是这本书,还是内核代码的某个注释提到过,通过slab管理的数据结构,访问频率越高的成员,建议放在结构体的越前面。同时我又查了一下高级缓存的命中原理,它包括全相联映射、直接相联映射、组相联映射三种方式,总之就是很多不同的内存页,会映射到相同的高级缓存块,比如下图所示,两个slab都是以页边界开始,第一个着色区为0,第二个着色区为一个缓冲行大小,这样,两个slab中的所有对象,前面部分的高频访问成员,映射的缓冲行就是错开的,从而访问对象1、对象2的前n个成员时,都不会覆盖对方前n个成员对应的缓冲行,从而降低了不同对象中高频访问成员在高级缓存中的冲突率。

- slab整体组织
单个slab,由slab_t结构管理,描述包含的实际对象的情况,包含同种对象的多个slab,由kmem_cache_t结构(即struct kmem_cache_s)管理,而每个kmem_cache_t对象本身,又是从挂在一个总根kmem_cache_t对象(变量名为cache_cache)上的slab分配的。
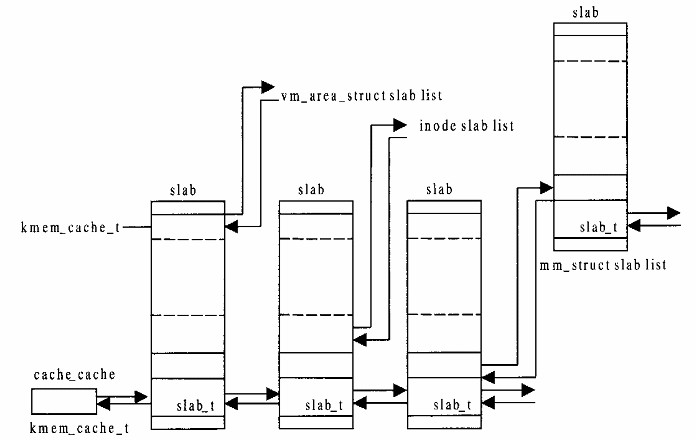
比如,现在需要预先分配100万个session对象,那么最终得到的就是一个kmem_cache_t对象,这个kmem_cache_t对象可能挂了10个新创建的slab,每个slab包含10万个session,而这个kmem_cache_t对象本身,又是从挂在cache_cache上的某个slab中分配的。
梳理一下,就是这样:
kmem_cache_t *kmem_cache_create() |- 从cache_cache分配一个kmem_cache_t对象 |- 创建10个新slab_t对象,每个slab包含10万个session,并且全部链入kmem_cache_t对象
/* internal cache of cache description objs */
static kmem_cache_t cache_cache = {
slabs: LIST_HEAD_INIT(cache_cache.slabs),
firstnotfull: &cache_cache.slabs,
objsize: sizeof(kmem_cache_t),
flags: SLAB_NO_REAP,
spinlock: SPIN_LOCK_UNLOCKED,
colour_off: L1_CACHE_BYTES,
name: "kmem_cache",
};- 接口
2. 外部设备存储空间的地址映射
ioremap() |- // 0xA0000-0x100000,用于VGA、BIOS |- // 0~virt_to_phys(high_memory),用于内存 |- 总线/物理地址区间检查 |- __ioremap() |- get_vm_area() // 从内核空间分配一块空闲的虚拟区间,内核空间由vmlist管理 | // 内核不是进程,所以没有task_struct结构,使用init_mm记录内存管理信息 |- remap_area_pages() // 建立虚拟页面与物理页面映射(设置目录表、页表)
① "超大程序"执行初期,一直顺着内核的代码执行,直到执行到idle进程创建的逻辑,以及根据系统启动配置创建init进程,和更多的用户进程,使得"超大程序"又动态增多了一部分指令, 所以进程的本质,就是"动态增加指令,并分配相应资源,然后跳转到增加的指令执行";
// idle进程目录项,由全局变量初始值指定为swapper_pg_dir init_idle() -> &init_task -> init_task_union -> INIT_TASK() -> INIT_MM() -> pgd=swapper_pg_dir // 其它进程目录项,768索引之后的部分,从父进程复制 sys_fork() |-> do_fork() |-> copy_mm() |-> mm_init() |-> pgd_alloc() |-> get_pgd_fast() |-> get_pgd_slow() |-> 复制:swapper_pg_dir+768偏移 -> 新目录表+768偏移
3. 系统调用brk()
内核代码的逻辑,决定了对各个进程虚拟空间的布局,Linux系统中,各个进程虚拟空间的低地址区,依次为代码段、初始化数据段、未初始化数据段,再往上是堆和栈,其中,栈靠近内核空间,向下增长,堆靠近数据段,向上增长。
堆的底端,在进程创建完成时就确定了,大小只能从顶端的边界开始调整,增长时要延着边界向上,分配虚拟区间和物理页面,并建立映射,减小时要延着边界向下,撤消虚拟区间与物理页面的映射。brk()函数是一个系统调用,就是用于动态调整进程堆区的大小。系统调用需要通过"门"进行调用,跟调用应用程序中的函数相比,除了会让CPU跳转到特定的指令块执行,还会让CPU从用户态切换到内核态,等到学习第三章"中断、异常和系统调用",就能详细的了解,先明白brk()函数用于增加/减小进程的堆即可。libc库,在堆之上,又实现了一层管理,从而可以利用malloc()/free()函数,执行更灵活粒度的分配/释放。
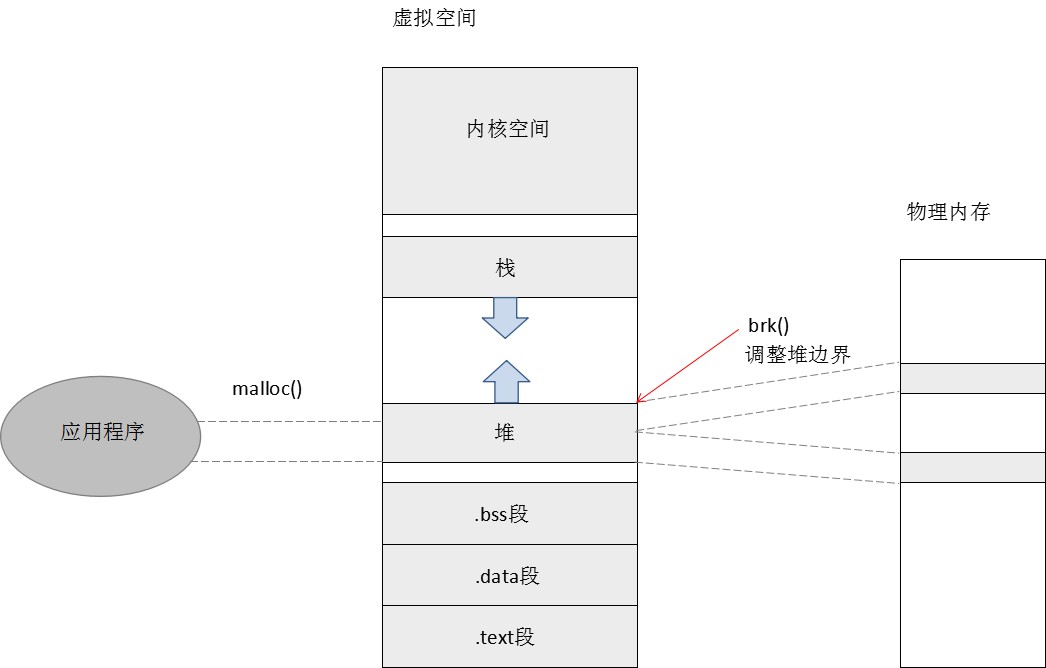
通过brk()函数进入内核态后,执行的是sys_brk()内核函数:
sys_brk() |- if (期望边界 < 当前边界) | |- do_munmap() | | | // 从当前进程已使用虚拟区间中,查找第一个结束地址高于期望边界的区间 | | |- find_vma_prev() | | |- do_munmap()还会在其它情景中被调用,所以要考虑释放某个区间当中的区域,将原区间一分为二的情况 | | |- 也要考虑释放区间,跨越已存在的多个区间的情况 | | |- /* 以下部分,涉及到文件系统,可以先不深究 */ | | | /* | | | * fs/namei.c,202,i_writecount含义注释: | | | * 0: no writers, no VM_DENYWRITE mappings | | | * <0: (-i_writecount) vm_area_structs with VM_DENYWRITE set exist | | | * >0: (i_writecount) users are writing to the file. | | | */ | | |- "<0"与">0"互斥,所以执行到此处的前提是"i_writecount<=0" | | |- 如果要撤消的虚拟区间,是通过mmap()遇到到文件的,执行740~750行的代码时,要避免其它进程对文件进行写操作 | | |- /* 以下是目前需要深刻理解的 */ | | |- // 解除虚拟页面和物理页面的映射 | | |- zap_page_range() | | |- zap_pmd_range() // 循环执行,直到最后一个映射对应的目录项 | | |- zap_pte_range() // 循环执行,直到最后一个映射对应的中级目录项 | | |- ptep_get_and_clear() // 清除相应范围的页表项 | | |- free_pte() | | |- if (pte_present(pte)) | | | |- free_page_and_swap_cache() | | | |- delete_from_swap_cache_nolock() | | | | |- lru_cache_del() // 从LRU队列移除,如果来自非交换文件,先将内容写进文件 | | | | |- __delete_from_swap_cache() // 从换入换出队列移除(在address_space结构中) | | | | |- page_cache_release() // 释放LRU占用的引用计数 | | | |- page_cache_release() // 释放分配时就分配的引用计数1 | | |- else | | |- swap_free() // 递减盘上页面使用计数 | |- unmap_fixup() // 处理虚拟区间一分为二等情况 | |- free_pgtables() // 撤消掉一些映射后,可能有些页表的页表项全部为0了,相应的的页表也要释放 |- else // 扩展堆的大小 |- 检查资源限制(ulimit命令可以查看/设置各个进程堆大小、栈大小,以及其它资源的限制) |- find_vma_intersection() // 检查是否与已有区间冲突,高端区间可能是与栈冲突,低端区间可能是与进程本身的数据段冲突 |- vm_enough_memory() // 检查是否有足够的内存用于扩展 |- do_brk() // 扩展 |- make_pages_present() |- handle_mm_fault() // 主动利用缺页异常处理函数,建立映射
4. 系统调用mmap()
- mmap()应用
mmap()函数用于将文件的指定区间,映射到内存,从而可以直接通过内存,读写文件内容。
原型:void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
flags参数包含很多标志位,个人觉得以下2个对mmap()函数的理解,影响较大:
MAP_ANONYMOUS:匿名映射,映射到的是dev/zero文件,可以用于父子进程间共享内存;
MAP_FIXED:flags不包含该标志时,addr参数只是一个参考值,包含该标志时,则要求mmap()一定使用addr地址处的虚拟区间进行映射,并且要求addr处的虚拟区间原本就已经映射,一般用于加载.so文件,.text段、.data段、.bss段属于不同,不可以位于同一个虚拟区间,但各自mmap(),又不能保证位置上连续,所以先映射出一块总的,然后分别MAP_FIXED覆盖。
- mmap()函数分析
// Linux-2.4.0往前一些的版本 old_mmap() |- copy_from_user() // 将参数拷贝到内核空间 |- do_mmap2() // Linux-2.4.0版本 sys_mmap2() |- do_mmap2() // old_mmap()和sys_mmap2()仅仅是传递参数的方式不一样,关键逻辑都调用do_mmap2()完成 do_mmap2() |- do_mmap_pgoff() |- 检查文件属性,是否满足flags参数指定的映射方式 |- kmem_cache_alloc() // 分配一个vm_area_struct对象,用于管理新增的虚拟区间 |- if (flags参数指定MAP_FIXED) | |- 用于覆盖已有虚拟区间,不需要重新分配 |- else | | // 从TASK_UNMAPPED_BASE即1G开始往上找一块可以容纳映射长度的空闲虚拟区间 | |- get_unmapped_area() |- kmem_cache_alloc() // 分配一个虚拟区间管理结构,并初始化成员 | // 记录映射在文件中的起点,这样虚拟区间的每个页面对应的"盘上页面"就已经确定了,不需要像swap文件那样依赖PTE |- vma->vm_pgoff = pgoff | // 先分配,再检查条件 | // 否则如果由于分配函数内部暂时分配不到物理页面,"礼让"其它进程先执行再回到这里,先前的检查就都失效了 |- if (do_munmap()撤消重叠区间失败 | || 进程虚拟区间个数已经达到上限 | || 本次为建立进程专用可写区间,但物理内存不够) | |- 释放新分配的虚拟区间管理结构 | // flags参数包含MAP_ANONYMOUS标志位,为匿名映射,file=NULL |- if (file) | |- if (flags参数指定MAP_DENYWRITE) | | |- deny_write_access() // 不允许通过常规操作访问文件 | |- get_file() // 递增file引用计数 | |- file->f_op->mmap() // 如果file是Ext2文件,mmap函数指针指向generic_file_mmap()函数 | | generic_file_mmap() | | | // file_private_mmap/file_shared_mmap又进一步提供了nopage函数指针:filemap_nopage() | | |- vma->vm_ops = &file_private_mmap/&file_shared_mmap // 根据flags参数是否指定VM_SHARED |- else if (flags参数指定MAP_SHARED) |- shmem_zero_setup() | // 书中6.7节"共享内存"详细介绍 |- shmem_file_setup() // 映射到dev/zero文件 |- vma->vm_ops = &shmem_shared_vm_ops
do_page_fault() |- handle_mm_fault() |- handle_pte_fault() |- if (!pte_present(entry)) |- if (pte_none(entry)) |- do_no_page() |- vma->vm_ops->nopage() // nopage函数指针,由mmap()函数设置
mmap()函数中执行的file->f_op->mmap(),和do_page_fault()函数中执行的vma->vm_ops->nopage(),都叫做VFS(虚拟文件系统)接口,对于Ext2文件,它们最终执行的分别是Ext2文件驱动中的do_mmap2()、filemap_nopage()。有一句话叫做"Linux一切皆文件",比如,socket()函数返回的就是文件描述符,读写该文件描述符,就可以收发网络报文,除此之外,键盘对应的是字符设备文件,硬盘对应的是块设备文件。。而不同文件的功能不同,是因为对应的硬件和驱动的实现逻辑不同,在各种不同的驱动之上,内核抽象了一套文件操作的统一接口,即VFS(相当于文件操作框架),内核本身只使用VFS接口操作文件,不关心不同文件系统的区别,VFS接口的功能由驱动层具体实现。所以书中建议,等到学完第五章"文件系统",可以回头再看一遍mmap()函数的实现。
- 对比
① mmap()文件映射 —— read()、write()
read()、write()函数会为文件在内核空间分配缓存,所以mmap()的性能优势在首次读写文件的时候,比如read()函数从硬盘读取文件内容,要先从内核空间分配一块缓存(不能直接读到用户态buffer映射的物理内存,因为读取文件也是以页为单位的,另外还有预读等情况,会覆盖buffer之外的内存,所以要另外找一块物理内存作为缓存),然后复制到用户空间,而mmap()用户态的buffer,天生就会映射到文件内容所在的物理页面,所以少了一次内核态与用户态之间的复制,write()函数同理。
② mmap()匿名映射 —— brk()
mmap()匿名映射和brk()一样,用于malloc()内部实现。使用brk()只能通过边界调整堆的大小,如果边界上的页面还在使用,即使free()掉再多的内存,仍然由libc层维持着,并没有真正释放给系统,但可以缓解虚拟空间的碎片;使用mmap()可以从1G虚拟地址之上,到栈顶之间,寻找空闲的虚拟区间,每个区间可以使用brk()单独释放。
malloc() |- if (分配大小 < 128K) | |- brk() |- else |- mmap()
5. malloc()
- Understanding glibc malloc,介绍了malloc()/free()的内部机制
- Linux (x86) Exploit Development Tutorial Series,介绍了各种二进制漏洞,其中包括堆溢出的利用原理