Linux内核笔记004 - 从内存管理开始,认识Linux内核
发布者:jmpcall
发布于:2020-05-28 16:31
1. 系统初始化
Linux内核笔记001、Linux内核笔记002、Linux内核笔记003,对应的是《Linux内核源代码情景分析》第一章内容,在进入第二章学习之前,本篇笔记先跳跃到第10.1节——系统初始化(第一阶段):
- 实模式
内存是挥发性的存储介质,断电后,数据就没有了,相应的,开机时,是通过"烧"在不挥发存储介质上的初始引导程序(比如BIOS程序),将内核程序从磁盘引导区读入内存的。在内核被加载到内存后,指令就会从BIOS跳转到内核代码开始执行,这时CPU还是实模式状态,内核代码做好一些基础准备后,再通过设置相关寄存器,将CPU切换到保护模式状态。
这个过程后续会详细学习,本篇笔记暂不记录,目前只需要知道一个gdt_table变量:
ENTRY(gdt_table) .quad 0x0000000000000000 /* NULL descriptor */ .quad 0x0000000000000000 /* not used */ .quad 0x00cf9a000000ffff /* 0x10 kernel 4GB code at 0x00000000 */ .quad 0x00cf92000000ffff /* 0x18 kernel 4GB data at 0x00000000 */ .quad 0x00cffa000000ffff /* 0x23 user 4GB code at 0x00000000 */ .quad 0x00cff2000000ffff /* 0x2b user 4GB data at 0x00000000 */ .quad 0x0000000000000000 /* not used */ .quad 0x0000000000000000 /* not used */ /* * The APM segments have byte granularity and their bases * and limits are set at run time. */ .quad 0x0040920000000000 /* 0x40 APM set up for bad BIOS's */ .quad 0x00409a0000000000 /* 0x48 APM CS code */ .quad 0x00009a0000000000 /* 0x50 APM CS 16 code (16 bit) */ .quad 0x0040920000000000 /* 0x58 APM DS data */ .fill NR_CPUS*4,8,0 /* space for TSS's and LDT's */
以上代码,就是内核对这个变量的初始化内容,编译后,这个内容会存入内核镜像文件的数据段,跟镜像文件的指令段内容一样,也会在开机时,被加载到内存的指定位置。书中1.2节,介绍过GDTR/LDTR寄存器,通过gdt_table变量名,应该已经可以猜出,它就是GDTR指向的全局描述符表,用于CPU切换到保护模式时进行段式寻址。
另外,在实模式阶段,内核会将CS寄存器设置为__KERNEL_CS,即0x10(二进制:10|0|00),按照保护模式下段寄存器的含义,即:index=2、TI=0、RPL=0。
"TI=0"表示使用全局描述符表,即gdt_table,则"index=2"索引到的描述符为0x00cf9a000000ffff,转换为二进制:
0000 0000 1100 1111 1001 1010 0000 0000 0000 0000 0000 0000 1111 1111 1111 1111
再结合段描述符的结构定义,得到:
① B0-B15、B16-B31都为0,即段基址为0
② L0-L15、L16-L19都为1,G位为1,即段长度为4G
也就是说,CS寄存器"指向"的段,是从0地址开始,4G长度的整个内存。其实,"3、4、5"索引处的描述符,同样是这种情况:"3"与"2"的区别,仅在于type字段,分别表示代码段、数据段,用于赋值给CS和DS、ES、SS;"4、5"与"2、3"相比,又仅仅是RPL字段有区别,表示权限级别分别为0、3。
这是因为,Linux内核紧接着就会跳转到startup_32代码处,开启CPU的页式管理功能,它根本没打算使用段式映射的方式,进行内存管理,只是由于80386寻址逻辑,总是会先经过段式映射过程,Linux内核这样设置,一方面保证不会遇到CPU内部的检查错误(越权、越界),另一方面,映射后逻辑地址也能保持不变,在软件层,对于后续的页式映射过程,让段式映射过程变得"透明"了;
- 保护模式
跳转到startup_32时,CPU已经切换到保护模式状态了,同进入保护模式前,要设置好段寄存器、段描述符表的道理一样,在开启页式映射功能前,也要准备好一定量的目录表、页面表内容。
我当初就有过一个疑问:开启页式管理时访问内存,要事先由分配函数建立了映射关系才行,那么刚开启页式管理时,分配函数本身需要访问的内存,又是什么时候建立映射关系的呢?
其实,这里就是源头。可以理解成,页式管理开启前,指令中包含什么地址,实际访问到的也是这个地址,没有"分配"的概念,页式管理开启后,指令中直接包含的地址,都要利用"分配"操作事先建立的页式映射关系,才能得到物理地址。这里就相当于,在为开启页式映射后紧接着的一些操作"分配"内存,跟应用程序开发中,执行一个算法前,先调用malloc()分配一块内存,是一样的道理。
/* * swapper_pg_dir is the main page directory, address 0x00101000 * * On entry, %esi points to the real-mode code as a 32-bit pointer. */ /* * 引导过程更之前的阶段,会将startup_32代码片段,复制到0x100000物理地址处,并且跳转语句为"ljmp 0x100000",而不是"ljmp startup_32": * 如果在程序里,将跳转语句写成"ljmp startup_32",编译后会生成形似"ff 2d XX XX XX CX"的二进制指令,"XXXXXXX"部分,表示startup_32指令块在二进制文件中的偏移,它受整个程序中定义变量的多少,以及其它函数的情况影响,增删一个函数,或者在某个函数增删一行代码,都有可能会影响startup_32的位置,另外,为了保证内核基本逻辑,访问的都是内核空间,内核程序中所有符号的地址,都会加上链接脚本中指定的偏移0xC0000000,从而最终生成到跳转指令中的地址为0xCXXXXXXX * 而此时已经是保护模式,再加上Linux内核的设计,使得段式映射前后的地址保持不变,所以"ljmp startup_32"指令就会跳转到真实内存的0xCXXXXXXX处,而不是startup_32真正所在的0x100000处 */ ENTRY(stext) ENTRY(_stext) startup_32: /* * Set segments to known values */ /* * DS、ES、FS、GS都设置为__KERNEL_DS * Linux内核真正希望使用的只有页式管理,但由于80386硬件设计的原因,进入页式映射前,要保证段式映射也能顺利完成 */ cld ; DF标志位清0 movl $(__KERNEL_DS),%eax movl %eax,%ds movl %eax,%es movl %eax,%fs movl %eax,%gs #ifdef CONFIG_SMP /* * BX在本段代码中,表示"是否为次cpu" * bx与自己相或,结果作为跳转条件,如果bx为0,即主cpu执行到这,会跳转到紧接着的第一个"1"标号处 */ orw %bx,%bx jz 1f /* * New page tables may be in 4Mbyte page mode and may * be using the global pages. * * NOTE! If we are on a 486 we may have no cr4 at all! * So we do not try to touch it unless we really have * some bits in it to set. This won't work if the BSP * implements cr4 but this AP does not -- very unlikely * but be warned! The same applies to the pse feature * if not equally supported. --macro * * NOTE! We have to correct for the fact that we're * not yet offset PAGE_OFFSET.. */ /* * 次cpu进入startup_32前,bx被设置为1,执行这段代码,最关键的逻辑是,直接跳转到"3"标号处,使用主cpu设置好的页表,自己不再设置 */ #define cr4_bits mmu_cr4_features-__PAGE_OFFSET cmpl $0,cr4_bits je 3f /* 如果支持PSE/PAE,设置CR4寄存器 */ movl %cr4,%eax # Turn on paging options (PSE,PAE,..) orl cr4_bits,%eax movl %eax,%cr4 jmp 3f 1: #endif /* * Initialize page tables */ /* * 汇编代码中,可以通过.org让编译器将变量安排在指定偏移处,比如pg0、empty_zero_page,分别被安排在二进制文件中的0x2000、0x4000处,加上链接脚本指定的偏移,编译地址分别为0xC0002000、0xC0004000 * "Linux内核笔记002"已经说明过,0-3G范围的虚拟地址,在不同进程中,会映射到不同的物理地址,而3G-4G的虚拟地址为内核空间,映射关系不能因进程不同而不同,否则就跟用户空间一样属于各个进程的私有空间了,从而,对于3G-3G+896MB范围的所有虚拟地址,都是按照"减0xC0000000偏移"的规则,建立一个固定的映射关系(剩余128MB内核空间属于高端内存,后期学习) * 那么,对于虚拟地址0xC0002000、0xC0004000,经过映射后,对应的物理地址就应该分别为0x2000、0x4000,然而代码执行到此处,还没开启页式管理,也还没有建立这样的映射,所以通过指令本身减掉了0xC0000000(__PAGE_OFFSET)偏移,它跟开启页式管理后,cpu通过映射找到的物理地址是一样的 * "1"、"2"标号处代码结合一起,正是用于建立0xC0000000-0xC0800000这部分内核空间(开头8MB)的映射,从0x2000开始,依次写入页表项0x007、0x1007、0x2007..,直到0x4000处结束,从而建立了2个PT(页表),后续再指定好目录表,并设置好目录项,开启项式管理后,就可以正常访问0xC0000000-0xC0800000范围内的虚拟地址了 */ movl $pg0-__PAGE_OFFSET,%edi /* initialize page tables */ movl $007,%eax /* "007" doesn't mean with right to kill, but PRESENT+RW+USER */ 2: stosl ; 将EAX值,复制到ES:DI,此时为保护模式状态,扩展段为从0开始的整个4G空间,所以ES:DI从0x2000开始 add $0x1000,%eax ; 0x007、0x1007、0x2007 .. cmp $empty_zero_page-__PAGE_OFFSET,%edi jne 2b /* * Enable paging */ /* * swapper_pg_dir由.org指定偏移为0x1000,程序将它的地址设置到CR3寄存器中,即用它指向的一页内容,作为目录表 * "80386硬件API"会把CR3"参数"的值,直接当作物理地址,由于此时还没有开启页式管理,仍然需要指令本身从编译生成的虚拟地址中,减掉__PAGE_OFFSET偏移 * 然后,将CR0最高位(PG标志位)设置为1,开启页式管理 */ 3: movl $swapper_pg_dir-__PAGE_OFFSET,%eax movl %eax,%cr3 /* set the page table pointer.. */ movl %cr0,%eax orl $0x80000000,%eax movl %eax,%cr0 /* ..and set paging (PG) bit */ /* * 以下这条跳转指令,用于丢弃已经在"cpu的取指令流水线"中的内容(Intel在i386技术资料中的建议) * 另外,每执行一条指令,IP寄存器的值,就会加上这条指令的长度,指向下一条指令,到目前为止,IP寄存器都是在0x100000的基础上加,接下来这条指令的地址大概为0x100XXX,由于上一条指令已经开启页式映射,所以这个地址也需要有映射关系,cpu才能得到它的物理地址,其实,稍后就可以看到,目录表最开始2项,也有初始值,也指向上面建立的2个页表,从而使得0-8MB虚拟地址也有映射关系,并且可以保持映射前后的值不变,目的就是用于这种过渡期 */ jmp 1f /* flush the prefetch-queue */ 1: /* * 编译后,"1f"标号的地址为0xCXXXXXXX,按照如下指令跳转一下,IP寄存器的值就是内核空间的地址了,就不用依赖目录表中最开始的2个目录项了,另外,引用程序中的变量,也不用依赖指令本身减掉__PAGE_OFFSET,从而完全过渡到页式管理 */ movl $1f,%eax jmp *%eax /* make sure eip is relocated */ 1: /* Set up the stack pointer */ lss stack_start,%esp
pg0、pg1、empty_zero_page位置安排:
/* * The page tables are initialized to only 8MB here - the final page * tables are set up later depending on memory size. */ .org 0x2000 ENTRY(pg0) .org 0x3000 ENTRY(pg1) /* * empty_zero_page must immediately follow the page tables ! (The * initialization loop counts until empty_zero_page) */ .org 0x4000 ENTRY(empty_zero_page)
目录表初始化内容:
/* * This is initialized to create an identity-mapping at 0-8M (for bootup * purposes) and another mapping of the 0-8M area at virtual address * PAGE_OFFSET. */ .org 0x1000 ENTRY(swapper_pg_dir) /* 用于0-8MB虚拟地址映射(属于用户空间,与内核空间开头8MB映射到相同的物理地址,临时用于过渡,最终会被撤消) */ .long 0x00102007 .long 0x00103007 /* 接下来766个目录项初始化为0 */ .fill BOOT_USER_PGD_PTRS-2,4,0 /* default: 766 entries */ /* 用于 0xC0000000 - 0xC0000000+8MB 内核地址映射 */ .long 0x00102007 .long 0x00103007 /* 接下来254个目录项初始化为0 */ /* default: 254 entries */ .fill BOOT_KERNEL_PGD_PTRS-2,4,0
2. Linux内存管理的基本框架
通过Linux内核对待80386段式管理特性的方式,很容易可以理解,软件可以根据自己的需要,选择性的使用硬件特性,比如剪刀一般是用于剪东西,但有些人也会用它松螺丝。换句话说,只要最终能将"硬件API"的"参数"设置正确,保证硬件内部不出错,将"参数"设置成什么,以及如何"设置",都由软件自己决定。
对于页式管理特性的利用,Linux内核的做法如下:
- 虽然看起来有些"特别"
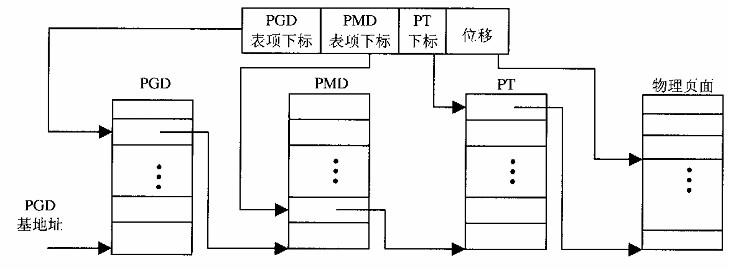
线性地址到物理地址的映射,80386的硬件逻辑是:线性地址前10位作为索引,到目录表中找到目录项,从而找到一张页表;再根据接着的10位,到页表中找到而表项,从而找到目标页;根据最后12位的偏移值,最终在目标页中映射到一个物理地址。
那么,Linux内核在建立映射关系时,也应该将线性地址看成3部分,只不过硬件是使用,软件是设置,比如线性地址"0x80000000",如果内核按8位、8位、4位、12位划分,建立映射时,它设置的就是0x80下标的目录项,而硬件执行映射时,找到的是0x200下标的目录项,显然就会是空的或者其它虚拟地址的目录项。
0x 1000000000 0000000000 000000000000 // 10,10,12 0x 10000000 00000000 0000 000000000000 // 8,8,4,12
- 但也很容易理解
首先,4层是逻辑划分,如果划分成10,0,10,12,那么实际划分仍然是3层,这是可行性;另外,Linux软件不光只运行在80386上,还要支持其它型号的cpu,包括Intel的其它系列,以及其它厂商的cpu,不光要考虑当下,还要考虑将来,因为cpu都已经从8位发展到32位了,将来势必会发展到更多位数,逻辑上支持4层,对于不同的cpu,简单指定下位数的分配就能适应了,这是软件设计的必要性。
3. 地址映射的全过程
前面已经学习了10.1节,那么这部分内容其实就非常好理解了,书里面拿了一个用户空间的地址举例,目前为止,初学者可能还是不能完全体会用户态和内核态的本质,为了保持节奏,可以先不用担心这一点,学习完第三章——中断、异常和系统调用,以及第四章——进程与进程调度,自然就能明白了。
目前为止,只是学习了映射过程,关于内存管理的内容还很多:
- 每个进程有4G虚拟空间,其中0-3G由各个进程独自使用,一方面数量有上限,也属于资源,另一方面映射关系还没有撤消,就不能拿来映射到另外一个物理地址,所以内核要对每个进程的虚拟空间进行管理,另外,物理地址更加需要管理;
- 虚拟空间又分为栈和堆,局部变量使用的是栈内存,malloc()分配的是堆内存,内核对它们的管理,也有区别;
- 换入换出技术,支持将内存的数据,临时存入交换分区,需要时再从磁盘读回内存,也涉及到复杂的管理逻辑。
所以不要松懈,继续加油!
声明:该文观点仅代表作者本人,转载请注明来自看雪