Linux内核笔记003 - Linux内核代码里面的C语言和汇编语言
发布者:jmpcall
发布于:2020-05-14 14:34
1. Linux内核中的C语言
Linux内核是用GNU C编写,从而必须用gcc编译,另外gcc编译器在发展过程中,在不断的扩展和舍弃一些东西,所以就会出现一种情况:高版本gcc编译不了低版本内核、低版本gcc也编译不了高版本内核。所以在编译内核时,一定要使用跟内核版本差不多时期的gcc版本。
- 带返回值的宏函数
#include <stdio.h>
#define FUN() ({ \
int ret = 100; \
printf("do something ..\n"); \
ret; \
})
int main()
{
int m = FUN();
printf("%d\n", m);
return 0;
} 执行结果:
do something .. 100
- do {} while (0)
宏函数DUMP_WRITE(),在如下情况被调用时:
if (addr) DUMP_WRITE(addr,nr); else do_something_else();
按照如下两种方式定义,在被调用处展开后,都有问题:
#define DUMP_WRITE(addr,nr) memcpy(bufp,addr,nr); bufp += nr;
#define DUMP_WRITE(addr,nr) { memcpy(bufp,addr,nr); bufp += nr; } 而利用"do {} while (0)"将多条语句包在一起,无论怎么调用,都不会有问题:
#define DUMP_WRITE(addr, nr) do { \
memcpy(bufp, addr, nr); \
bufp += nr; \
} while (0)- [first ... last] = value
这是GUN C相对于ANSI C的一个扩展,用于将数组某个区间,初始化为非0值,比如:
int array[100] = { [0 ... 9] = 1, [10 ... 98] = 2, 3 };- include/linux/list.h
GUN C相对于ANSI C的扩展还有很多,书上已经列举了一小部分,更具体的,可以到后期学习代码时遇到了,再逐个了解。相对的,我认为include/linux/list.h这个头文件里面的代码,必须要在一开始就看懂,因为这里面的接口,大量用于内核的代码中,同时我觉得这种设计的思维也很精妙。
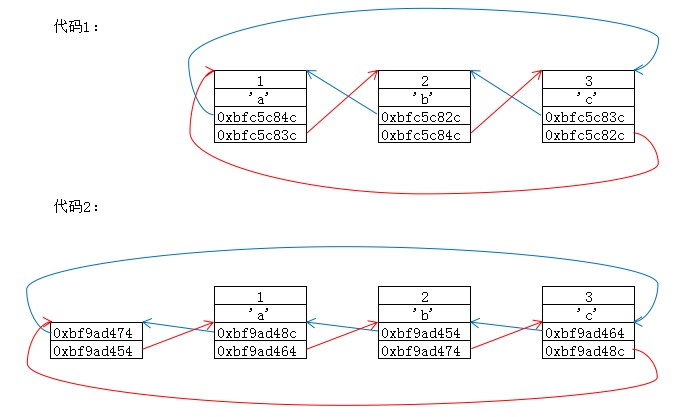
它用于构造双向循环链表, 从如下两份代码的对比中,应该就可以感受到它的好处:
代码1:
#include <stdio.h>
struct data_node {
int n;
char c;
struct data_node *prev;
struct data_node *next;
};
int main()
{
struct data_node datas[4] = {
{ 1, 'a', NULL, NULL },
{ 2, 'b', NULL, NULL },
{ 3, 'c', NULL, NULL }
};
struct data_node *head = &datas[0];
// 添加节点、遍历链表,需要业务层本身实现
datas[0].prev = &datas[2];
datas[0].next = &datas[1];
datas[1].prev = &datas[0];
datas[1].next = &datas[2];
datas[2].prev = &datas[1];
datas[2].next = &datas[0];
while (1) {
printf("datas[%d]: n=%d, c=%c, prev=%p, next=%p\n",
head->n - 1, head->n, head->c, head->prev, head->next);
if (head->n == 3)
break;
head = head->next;
};
return 0;
}运行结果:
datas[0]: n=1, c=a, prev=0xbfc5c84c, next=0xbfc5c83c datas[1]: n=2, c=b, prev=0xbfc5c82c, next=0xbfc5c84c datas[2]: n=3, c=c, prev=0xbfc5c83c, next=0xbfc5c82c
代码2:
#include <stdio.h>
#include "list.h"
struct data_node {
int n;
char c;
struct list_head list;
};
int main()
{
struct data_node datas[4] = {
{ 1, 'a', { NULL, NULL } },
{ 2, 'b', { NULL, NULL } },
{ 3, 'c', { NULL, NULL } }
};
struct list_head head = LIST_HEAD_INIT(head);
struct list_head *pos;
// 添加节点、遍历链表,业务层直接调用接口
list_add_tail(&datas[0].list, &head);
list_add_tail(&datas[1].list, &head);
list_add_tail(&datas[2].list, &head);
printf("head: %p, prev=%p, next=%p\n", &head, head.prev, head.next);
list_for_each(pos, &head) {
struct data_node *data = list_entry(pos, struct data_node, list);
printf("datas[%d]: n=%d, c=%c, prev=%p, next=%p\n",
data->n - 1, data->n, data->c, data->list.prev, data->list.next);
}
return 0;
}运行结果:
head: 0xbf9ad48c, prev=0xbf9ad474, next=0xbf9ad454 datas[0]: n=1, c=a, prev=0xbf9ad48c, next=0xbf9ad464 datas[1]: n=2, c=b, prev=0xbf9ad454, next=0xbf9ad474 datas[2]: n=3, c=c, prev=0xbf9ad464, next=0xbf9ad48c
- list_entry()
include/linux/list.h这份代码整体不难,但是如果是刚开始学习,可能会对宏函数list_entry()有些疑惑:
#define list_entry(ptr, type, member) \ ((type *)((char *)(ptr)-(unsigned long)(&((type *)0)->member)))
① 首先要明白的是:为什么需要这个宏函数?
代码1中,datas[1].prev,直接就是&datas[0],而代码2中,datas[1].list->prev,只是&datas[0].list而已,想知道&datas[0]的话,还需要减去list成员相对于结构体开始的偏移,知道目的后,再去理解这个宏函数就不难了。
但是,还有值得注意的地方:"&((type *)0)->member",按照平时开发程序的经验,可能觉得这里会coredump!
直接举例:
#include <stdio.h>
struct test {
int n;
char c;
};
int main()
{
struct test *p = NULL;
//printf("%d, %c\n", p->n, p->c); // coredump
printf("%p, %p\n", &p->n, &p->c); // 不coredump
printf("%p, %p\n", &((struct test*)0)->n, &((struct test*)0)->c); // 不coredump
return 0;
}这样,就可以推测出来一个过程,我们平常在C程序中写的"p->n",其实等价于"*(&p->n)","&p->n"前面有个显式的&,则只是根据p的地址,计算成员n的地址,哪怕"p=NULL"也没关系,coredump只是发生在访问这个错误地址的时候而已。
2. Linux内核中的汇编代码
- Linux内核使用汇编的场合
① 有些操作硬件的专用指令,在C语言没有对应的语言成分,比如给GDTR/LDTR寄存器赋值的特权指令:LGDT/LLDT
② 某些场合,对效率要求极高,或者对执行时间有精准的要求
③ 某些场合,对程序的体积也有极端的要求,如引导程序
- Linux内核使用汇编的形式
① 纯汇编代码。比如学习到第10章"系统的引导和初始化"时,就会遇到纯汇编文件bootsect.S、sctup.S,另外,后缀如果是大S,里面可能会包含一些C语言中的预处理语句,后缀为小s,就没有任何其它语言的影子;
② 嵌入式汇编。在C函数中,可以按照__asm__ __volatile__ (“指令部:输出部:输入部:损坏部”)格式,嵌入一块汇编语言(稍后举例)。
- AT&T格式与intel格式比较
从网上可以查到很详细的资料,我觉得刚开始学,只需要对一些符号(比如:$、%)有印象即可,在看代码时遇到了,再去确认具体的含义。
- 嵌入式汇编/内联汇编
书1.5.2节,最后举了内核中2个使用了内联汇编的函数:__memcpy()、strncmp()。

(这个图我在chinaunix发过,所以不是抄袭)
汇编代码块前后,是可以有C语句的。
① 所有用双引号包围的内容,为"指令部",从紧接着指令部的冒号开始,依次标记为0、1、2、..
指令部后面第一个冒号开始,为“输出部”,用于指定C的各个变量,由哪些寄存代替。例子中,用ecx作d0,用edi作d1,用esi作d2;
指令部后面第二个冒号开始,为“输入部”,用于初始化变量。例子中,"0"标号对应的"ecx/d0"=n/4,"q"让编译器从eax/ebx/ecx/edx选择一个进行使用,并且初始化为n,"1"标号对应的"edi/d1"=to,"2"标号对应的"esi/d2"=from;
指令部后面第三个冒号开始,为“损坏部”,指令部和输出部中的寄存器,在执行过程中,都有可能被修改掉,如果希望某些寄存器的值保持不变,就可以在损坏部指定,编译器就会在入口添加压栈保存、在出口添加出栈恢复的指令。
指令部后面第二个冒号开始,为“输入部”,用于初始化变量。例子中,"0"标号对应的"ecx/d0"=n/4,"q"让编译器从eax/ebx/ecx/edx选择一个进行使用,并且初始化为n,"1"标号对应的"edi/d1"=to,"2"标号对应的"esi/d2"=from;
指令部后面第三个冒号开始,为“损坏部”,指令部和输出部中的寄存器,在执行过程中,都有可能被修改掉,如果希望某些寄存器的值保持不变,就可以在损坏部指定,编译器就会在入口添加压栈保存、在出口添加出栈恢复的指令。
② "指令部"分析:
"输入部"已经完成了初始化:ecx = n/4,eax = n,eid = to,esi = from;
第一条指令"rep; movsl\n\t":重复执行movsl n/4(ecx)次,每次从from(esi)拷由4byte到to(edi),执行完可能还剩1~3字节没有拷贝;
第二条指令"testb $2,%b4\n\t":AT&T格式中,"$数字"表示立即数,"%数字"表示输入/输出部相应标号处的内容,所以这条指令就是判断%4(拷贝长度n)的低第二位是否为1(代码中为"%b4",不确实是不是告诉编译器尽量用ebx的意思),如果为1,则至少还剩2字节,所以执行第四条指令"movsw",再拷贝2字节,否则执行第三条指令"je 1f\n\t"("f"表示forward,往前方最近的1标号处跳转),直接跳转到"1:\ttestb $1,%b4\n\t";
第五条指令,同样的道理,判断是否还剩1字节没的拷贝,如果是,则会执行"movsb"指令,再拷贝1字节。
③ 执行效率
由于这个函数的使用频率极高,所以内核直接使用汇编实现,让函数简洁到了极限,没有任何一条多余的指令。感兴趣的话,可以用C语言写一个__memcpy(),用不同的优化级别编译,然后反编译和内核中的这个函数对比,感受一下。
声明:该文观点仅代表作者本人,转载请注明来自看雪