Linux内核笔记005 - 越界访问内存,Linux内核处理过程
发布者:jmpcall
发布于:2020-06-06 13:08
1. 几个重要的数据结构和函数
- 内存管理本质
在Linux内核笔记004中,已经引出了"分配"的概念,它本质上就是在保护模式下,做两件事:
① 隔离同一进程已使用和未使用虚拟内存空间,以及整个系统的已使用和未使用物理内存空间
具体实现:记录已每个进程已使用的虚拟地址,和整个系统已使用的物理地址,分配时使用未使用的。
②
隔离不同进程的用户空间
具体实现:为每个进程0-3G范围的虚拟地址,建立独立的映射,映射不同的物理地址(内存共享除外)。
现实生活中,所有的管理都依赖一道"关卡",同样的,软件层"内存管理"的实现,依赖CPU硬件层的"地址映射"特性。比如,在实模式状态下,每个程序,都可以用指令中的地址,直接访问到物理地址(比如Linux内核笔记004中记录的"ljmp 0x100000"跳转指令),就没有这道"关卡"。
- 物理地址管理
之前的笔记,已经详细描述了映射过程,包括CPU内部执行"段式/页式地址映射"的过程,以及Linux内核为"0xC0000000 - 0xC0000000+8MB"这块虚拟空间建立映射的过程,紧接着的学习,就是关于内核对"已使用/未使用"地址的管理,以下为物理地址管理相关的结构:
① struct page
typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct list_head lru;
unsigned long age;
wait_queue_head_t wait;
struct page **pprev_hash;
struct buffer_head * buffers;
void *virtual; /* non-NULL if kmapped */
struct zone_struct *zone;
} mem_map_t; 这个结构,跟记录"已使用/未使用"有什么关系呢?
Linux内核,利用的是80386的页式管理,所以分配释放的最小单位必须是"页",每个4K倍数的地址,都是一页内存的开始,如果只是记录"已使用/未使用",使用一个位图即可,每个位的0/1值代表相应页的"已使用/未使用"状态,然而,内存管理还需要记录其它很多信息,从而定义了以上结构,里面的成员,随着后续的学习,都会接触到,暂时不用关心。
此外,内核在启动时,根据实际内存的大小,创建了一个mem_map[]数组,数组的每个成员都是一个struct page"对象",0下标对应"0地址页"信息,1下标对应"4K地址页"信息..,所以struct page中没有表示页地址的成员,另外,"已使用/未使用"状态,是通过list成员挂在"已使用区/未使用区"区分。
start_kernel() |- setup_arch() |- paging_init() |- free_area_init() |- free_area_init_core() | // 根据实际的物理内存大小,创建mem_map[]数组(*gmap == mem_map) |- *gmap = alloc_bootmem_node()
一定要注意,struct page"对象",跟页面本身不是同一个东西,它只是用于记录一块4K大小的物理内存的使用情况而已,它们在位置上也没有任何联系。
② struct zone_struct
Linux内核将所有物理页面,划分成三个管理区:ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM。
为什么要划分一个ZONE_DMA管理区?
DMA设计的用意是:磁盘数据往内存的读写,不用CPU参与。那么,DMA本身就有访问内存的能力,同实模式/保护模式类似,DMA访问的地址,可以直接是物理地址,也可以是需要经过映射的虚拟地址,取决于内存管理单元(MMU)是单独实现,还是集成在CPU内部实现。80386就没有设计单独的MMU,所在DMA直接访问物理内存。
首先,由于有些外设,不能访问过高的地址,所以要在低地址区,划分一块ZONE_DMA管理区,专门用于DMA,避免被其它程序占用。
其次,如果某个外设希望通过DMA访问连续8K的内存,那就需要两个连续的物理页面,而不能像经过MMU那样,只要保证虚拟地址连续即可,前4K映射到一个物理页面,后4K映射到另一个相隔很远的物理页面都没关系,所以也要单独划分一块ZONE_DMA管理区,方便保证这一点。
最后,整个内存也有被用完的时候,单独划分一块ZONE_DMA管理区,也能保证DMA始终有内存可用。
除了ZONE_DMA管理区,在实际内存大于1G时,还会划分一个ZONE_HIGHMEM管理区(暂不关心,后期学习),其余部分则为ZONE_NORMAL管理区。
每个管理区信息对应的结构如下:
typedef struct zone_struct {
/*
* Commonly accessed fields:
*/
spinlock_t lock;
unsigned long offset;
unsigned long free_pages;
unsigned long inactive_clean_pages;
unsigned long inactive_dirty_pages;
unsigned long pages_min, pages_low, pages_high;
/*
* free areas of different sizes
*/
struct list_head inactive_clean_list;
free_area_t free_area[MAX_ORDER];
/*
* rarely used fields:
*/
char *name;
unsigned long size;
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
struct page *zone_mem_map;
} zone_t; ③ struct pglist_data
如下图所示,CPU访问不同内存条,代价是不一样的,有的需要跨总线,有的不需要,这种情况叫做"非均匀存储结构(NUMA)"。
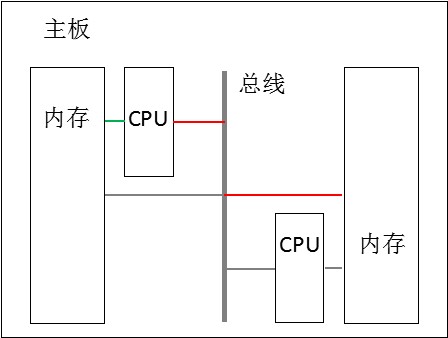
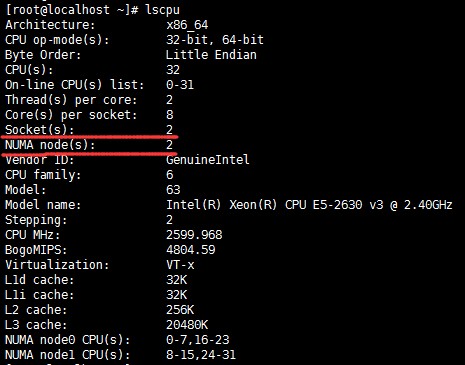
比如下面是一台机器的CPU信息,"Socket(s)"表示实际插在主板上的CPU个数为2,"Core(s) per socket"表示每个CPU上的物理核数为8,"Thread(s) per core"表示每个物理核开了2个超线程,所以总共有32个核,这些核就分别靠近两个不同的NUMA节点。
Linux内核,会对不同NUMA节点中的内存,进行独立管理。假设有2块属于不同NUMA节点的内存条,大小都是2G,将整个4G内存看作一个整体也是没问题的,但是Linux内核是将这2个2G内存,分别划分成3个管理区,从而在代码中定义了struct
pglist_data结构,用于记录一个NUMA节点的信息。
typedef struct pglist_data {
zone_t node_zones[MAX_NR_ZONES];
zonelist_t node_zonelists[NR_GFPINDEX];
struct page *node_mem_map;
unsigned long *valid_addr_bitmap;
struct bootmem_data *bdata;
unsigned long node_start_paddr;
unsigned long node_start_mapnr;
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
} pg_data_t; 到此为止,可以得出一个结论:利用struct pglist_data结构,可以表达系统中有多少个NUMA节点,利用struct zone_struct结构,可以表达每个NUMA节点中有哪些管理区,利用struct page结构,可以表达每个管理区包含的物理页面,最终相当于描述了一个物理页面"仓库",物理页面的管理,也正是对这个"仓库"的管理。
④ 伙伴算法
struct zone_struct有一个数组成员:
free_area_t free_area[MAX_ORDER]; // MAX_ORDER为10
数组的每个成员,又是一个struct free_area_struct"对象":
typedef struct free_area_struct {
struct list_head free_list;
unsigned int *map;
} free_area_t; 每个struct free_area_struct"对象"包含一个链表头,用于挂接连续的"空闲页面块"(通过页面块中首个页面对应的struct page"对象"的list成员),并且free_area[0]、free_area[1]..、free_area[9]的free_list,分别用于挂接大小为2、4..、1024(2^10)的连续页面块(所以可以分配的最大连续页面块为1024*4K=4M)。
虽然保护模式下,程序使用的是虚拟地址,即使分配超大块的内存时,只要保证虚拟地址是连续的即可,映射到的物理页面是不是连续,对于程序是"透明"的,但是"分配"发生频率超高,并且经常需要映射到多个物理页面,那么付出少量的代价,维持尽量多的连续物理页面,能在"分配"这一面获取非常大的效率收益。
伙伴算法就是用于快速将小页面块,合并为大页面块:

上图是我绞尽脑汁想到一种理解的方法:假设实际内存最开始16个页面的状态如上图,蓝色表示已分配、白色表示未分配,然后先别管抽象,无脑的跟着以下步骤去做:
将第一行(2n, 2n+1)下标处的内容(即(0,1)、(2,3)..伙伴算法不会将(1,2)、(3,4)..当成伙伴),两两圈在一起,它们各自属于一对伙伴。伙伴都忙(蓝色数字),表示其中一个释放,不可以合并成块,在下一行中用蓝色的0表示;伙伴都闲(黑色数字),表示已经成块,不需要再次合并,在下一行中用黑色的0表示;否则等正在忙的那个伙伴被释放时,就可以合并成块,在下一行中用蓝色的1表示(总之下一行的值,是由上一行中两个伙伴的颜色决定,而不是值)。
然后依次对第二行、第三行..做同样的操作,直到只剩一个数字,无法组成伙伴的那一行。此时再去验证每一个0、1,比如:
order(0)中的第3个1:page4已分配,page5空闲,当page5释放后就可以和page4合并;
order(1)中的第2个0:page4-7有3个已分配页面,只释放其中一个,不能进行合并;
order(2)中的第2个1:page8-15,只有page11已分配,当它释放后,就可以合并成一个8页面的空闲块;
...
然后,是不是就理解伙伴算法了?
伙伴算法用于释放时,将小块合并成大块,并将其移动到更高下标的free_area[]中,直到最大支持的1024个。而分配时,可能会将大块切分成小块:比如分配连续2个物理页面,程序会优先到free_area[0]中找,如果为空,就到free_area[1]中找,假设还为空,就到free_area[2]中找,假设不再为空了,此时就找到一个8页面空闲块,程序会将它切分成两个4页面块,其中一个挂接到free_area[1],另一个继续切分成2个2页面块,其中一个挂接到free_area[0],剩余一个就可以作为分配到的2个连续物理页面了。
⑤ 页表项(PTE)低12位
页表项用于指向最终映射到的物理页面,而物理页面的地址,都是按4K对齐(因为第一个页面的地址为0,每个页面的大小为4K),所以CPU只把PTE的高20位当作地址(左移12位即可),低12位用于PTE所指页面的属性,在后续的换入换出管理中,就可以看到对这些属性的利用。
另外,每个目录项指向的也是页面,并且,它指向的页面都被内核当作页表使用。
- 虚拟地址管理
虚拟地址也是资源,每个进程可以独立使用的有只有3G个地址,即使在64位系统中,数量就目前来讲已经不成问题了,那也得避免逻辑上的歧义,不能用同一个逻辑地址指向两个不同"对象",所以至少要对正在使用的虚拟地址,做记录管理,以下为虚拟地址管理相关的结构和函数:
① struct vm_area_struct
虚拟地址的分配,依赖程序本身,每个程序编译后,就有一部分要使用的虚拟地址是确定的了,比如代码段、数据段占用的虚拟地址,对于动态分配,要分配的连续大小也是由程序指定的,根据这样理解,虚拟地址管理的逻辑,本身就已经很固定了,所以整个逻辑,比对物理页面的管理要简单的多,struct vm_area_struct结构,就是程序指定要分配多大的内存时,内核分配这样一个"对象",将该虚拟地址区域记录下来,各个成员的含义在书中有详细的说明,笔记中不再重复。
struct vm_area_struct {
struct mm_struct * vm_mm; /* VM area parameters */
unsigned long vm_start;
unsigned long vm_end;
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
/* AVL tree of VM areas per task, sorted by address */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* For areas with an address space and backing store,
* one of the address_space->i_mmap{,shared} lists,
* for shm areas, the list of attaches, otherwise unused.
*/
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops;
unsigned long vm_pgoff; /* offset in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
struct file * vm_file;
unsigned long vm_raend;
void * vm_private_data; /* was vm_pte (shared mem) */
}; ② find_vma()函数
查找某个虚拟地址所在的虚拟区间。
2. 越界访问堆区
接下来,书中设定了一个情景:某个应用程序存在bug,它执行时,先通过mmap()函数获取一块内存,但会在munmap()之后,继续访问这块内存中的地址,从而发生"段错误"。
刚开始学习内核的时候,我始终想不明白内核为什么比应用程序"有权"(Linus写的代码可以执行CPU特权指令,我写的却不可以),以及它是如何将"权力"控制在自己手里。其实之前的笔记已经举了一些例子,用于感性的体会,这里再相对完整的理一遍:
内核对"权力"的把握,其实就是对CPU状态和内核空间控制权的把握:
① 开机时,CPU执行的入口是内核代码,所以说"权力"一开始就给了内核;
② 内核在为应用程序的执行,创造好准备条件之后,是先将CPU切换到低权限状态,才跳转,所以用户态的代码就不能执行特权指令;
③ 应用程序的代码在低权限状态执行,如果希望CPU回到高权限状态,必须穿过一道内核设置的"门"(详细内容在书中第三章——中断、异常和系统调用),权限提高的同时,指令也必须回到内核代码执行;
④ 应用程序的代码在低权限状态执行,就无法利用特权指令,建立/修改虚拟地址到物理地址的映射状态,再加上虚拟地址到物理地址映射的过程,CPU会进行权限检查,从而内核又掌握了对内核空间的"控制权",虽然每个进程都可以访问内核空间,但同样必须是穿过一道"门"进入内核态,调用内核的接口访问;
⑤ 内核除了将内核空间设置为"高权限才能访问"外,同时也保证将每一个内核空间中的虚拟地址,映射到的相同的物理地址,让内核空间成为所有进程的"公共空间"。
综上五点,最终的效果就是,任何进程都必须穿过"门",回到内核态,调用内核接口,进入到公共的内核空间,才能修改/获取整个系统中某个全局的管理信息,应用程序如果有bug,也只能影响到自己用户空间映射的那块独立的物理内存。
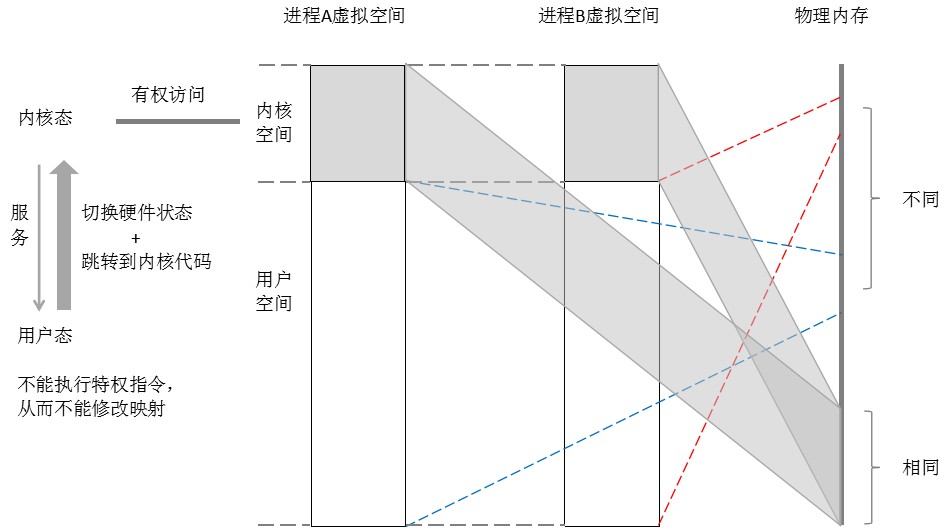
关于"门",仍然可以先感性的体会一下:进程如何才可以进入"门"?
- 主动进入
#include <stdio.h>
int main()
{
printf("hello\n");
return 0;
} 这个程序中调用的printf()函数,叫libc函数,libc库封装了很多"系统调用"函数(内核提供给应用程序的接口),比如执行"gcc test.c -g -Wall"编译上面的程序,然后执行"strace ./a.out",就可以列出来printf()内部调用了哪些"系统调用"函数,其中就有一个是write()函数,它在执行的过程中,就会切换到内核态,write()函数也可以不经过libc的封装直接调用,不管哪种方式,都属于应用程序主动进入内核态。
- 被动进入
如果只依赖应用程序主动进入内核态,那么,当应用程序执行到while(1){}循环里面的时候,CPU就只能永远为这个进程执行指令了,因为其它进程的信息都在内核空间,无法回到内核态,当然也就没有机会切换到其它进程。
所以硬件设计了一个"时钟中断"的功能,每过一段时间,不管CPU目前在干什么,都把当前的状态保存下来,进入"内核态"执行一个"定时函数",这个函数是由内核设置。
除了"时钟中断",如果应用程序访问一个还未映射到物理地址的虚拟地址,或者执行"除以0"这些异常操作,CPU也会自动切换到内核态,并且执行内核事先设置的"异常/陷阱"函数,这些虽然触发的源头是应用程序,但往往是"不经意"的,比如"/0"一切是程序有bug,然后由于"段错误"而被迫停止运行。
到这里,就可以回到书中设定的情景了,由于地址的映射关系,已经被munmap()函数撤消了,再次访问时,CPU在执行映射过程中,必定会遇到值为0的目录项或页表项,这种情况下,CPU就会按照上面描述的,保存当前状态,切换到内核态,并且跳转到内核的do_page_fault()函数执行。
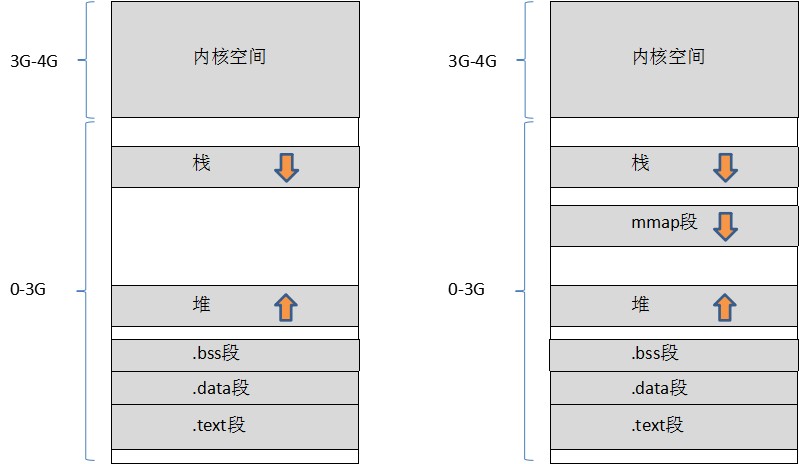
跳转到do_page_fault(),完整和正规的描述,书中第三章有详细的介绍,目前直接分析do_page_fault()的执行过程,在分析之前,可以先看一下Linux内核对进程虚拟空间的布局(按照书中对代码逻辑的解释,在Linux-2.4.0版本的时候,应该是如下左图):
do_page_fault()主要流程:
// 出现上述情景,CPU隐式跳转到do_page_fault()函数执行,并且自动把当时处于用户态/内核态、读/写访问信息,压栈作为error_code参数
do_page_fault()
| // CPU也会自动把访问出错的虚拟地址,存入CR2寄存器,这里取出,方便在C函数中使用
|- __asm__("movl %%cr2,%0":"=r" (address))
|- 获取内核为当前进程设置的进程管理结构,然后从该结构中获取虚拟地址管理结构
| // 暂时将上述隐式跳转到的函数,理解为中断函数,那么do_page_fault()本身就是中断函数,in_interrupt()表示跳转过来前,也是在中断函数
| // 所有应用程序,都有自己独立的虚拟空间,所以mm一定不为空,上述情景不满足以下判断条件
|- if (in_interrupt() || !mm)
| // 当前进程一定能在已使用的用户空间中,找出结束地址大于出错地址的第一个区间,因为至少也有个栈区在最上方
|- find_vma()
| // 当前情景找到的区间,会是从堆中动态分配的,并且起始地址也大于出错地址,因为出错地址所在的区间已经被munmap()函数撤消了
| // 从堆中分配的区间,增长方向向上,所以符合以下判断条件,goto到bad_area处执行
|- if (!(vma->vm_flags & VM_GROWSDOWN))
| // 以下判断出错时是否在用户态,上述情景符合判断
|- if (error_code & 4)
| // 设置软中断,让程序coredump(详细内容在书中第三章——中断、异常和系统调用)
|- info.si_signo = SIGSEGV 根据do_page_fault()的逻辑可以看出,访问没有映射的地址,必然会coredump,但按照平时的实际经验,又会发现,应用程序中越界访问堆区,有时候并不会coredump。那是因为应用程序使用的是libc中的malloc()/free(),调用free(),libc层并不一定立即调用内核的brk()函数,而是等到一定程度,才会真正撤消映射。
3. 越界访问栈区
上述说明了内核对堆区越界访问(分配范围以外)的处理过程,书中接着又设定了一个对栈区越界访问的情景:
Linux内核创建新进程时,会为新进程分配一块初始大小的栈区,当程序执行到某个状态,需要向栈中压入很多局部变量和函数参数时,初始分配的栈可能就不够用了,比如如同下图的状态,再向栈区存入一个变量,esp寄存器就要指向未分配区 了:
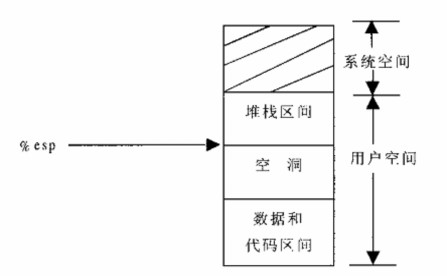
需要注意的是,这种情景跟安全领域中的"栈溢出"不是一个概念。这个情景针对的是分配,影响的是esp的指向,并且程序也不一定存在bug,而"栈溢出"针对的是对变量的写操作,影响的是已分配栈空间的内容,并且程序一定是存在bug,比如:
#include <stdio.h>
#include <string.h>
int main()
{
char buf[10] = { 0 };
// 会在buf[10]处写一个'\0'字符,超出了数组的范围
strcpy(buf, "0123456789");
printf("%s\n", buf);
return 0;
} 回到书中设定的情景,do_page_fault()主要执行流程如下:
do_page_fault() | // 到达这个判断条件之前,和munmap()的情景一样,但这时找到的虚拟区间,就会是栈区了 |- if (!(vma->vm_flags & VM_GROWSDOWN)) | // 这个情景也是在用户态访问地址的 |- if (error_code & 4) | | // 压栈数据最多的是pusha指令,可以一次性压入32字节 | | // 内核无法完全判断应用程序的逻辑错误,比如*(&局部变量-xx),也有可能访问到这个范围,那样程序一定会出现别的异常现象 | |- if (address + 32 < regs->esp) | // 栈是向下增长,正常的压栈操作,不符合以上判断,执行到这里对栈空间的大小进行扩展 |- expand_stack() | | // Linux对每个进程的栈空间,限制了大小,执行"ulimit -s"可以查看,超过就不能继续扩展了 | |- if (RLIMIT_STACK检查) | |- 扩展虚拟区间大小 |- 进入读写操作检查,产生异常时是写操作,而栈区肯定是可写的,所以通过检查 | // 为虚拟区间中刚才扩展的部分,分配物理地址并建立映射 |- handle_mm_fault() | // .org 0x1000 | // ENTRY(swapper_pg_dir) | // 整个系统只需要一个目录项,在系统初始化阶段就确定位置了(见"Linux内核笔记004") |- pgd_offset() | // 32位CPU上,不使用中间目录,所以还是返回目录页的地址,不影响映射过程 |- pmd_alloc() | // 一个页表可以容纳1024个页表项,第一个需要这个页表的分配操作,分配这个页表,其它的直接使用 |- pte_alloc() | // 以上获取的pte,可能是正在使用中的,它们它的低12位可以知道物理页面是否换出到交换分区了 | // 本次设定情景,由于访问的是之前没有分配过的内存,所以pte也一定是0 |- handle_pte_fault() |- if (!pte_present(entry)) |- if (pte_none(entry)) | | // 本次情景会执行到这里 | |- do_no_page() | | // mmap()、交换分区,都需要虚拟空间和文件有联系,vma->vm_ops就包含一些文件操作的函数指针 | |- if (!vma->vm_ops || !vma->vm_ops->nopage) | | | // 栈空间跟文件没有联系,所以本次情景会执行这里 | | |- do_anonymous_page() | | |- if (write_access) | | | | // 分配物理页面,如果是读访问,先映射到ZERO_PAGE,写的时候再分配(COW) | | | |- alloc_page() | | | |- pte_mkwrite() | | | // 让pte指令新分配的物理页面 | | |- set_pte() | |- vma->vm_ops->nopage() |- do_swap_page()
内核执行完do_page_fault(),会再回到应用程序中压栈的那条指令执行,这样,就是压栈的那条指令,在应用程序"感受"不到的情况下,导致进程进入内核走了一圈,扩展了栈的大小后,又回到了这条指令,这个过程叫做"缺页异常"。
最后顺便提一下,在以上的内容中,提到"中断",异常和中断,在从内核态返回用户态时,是有区别的:
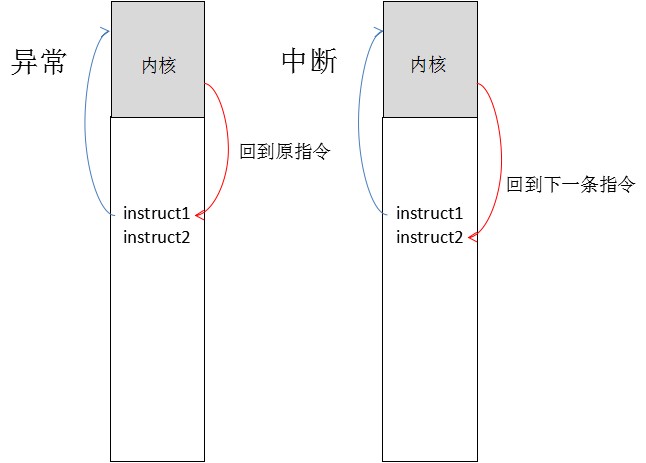
声明:该文观点仅代表作者本人,转载请注明来自看雪