sqlmap源码通读(二)
三、源码阅读
基本上比较常用的参数都在上面列了一下,当个速查表吧,然后就开始学习sqlmap源码之路吧。
本次学习的源码版本为 1.3.6.50#dev
目录结构
首先看一下目录结构,我们将文档类的文件排除掉,只看系统类的:
主目录
文件/文件夹 说明
data/ 数据库注入检测载荷、用户自定义攻击载荷、字典、shell命令、数据库触发顺序等
extra/ 一些额外功能,例如发出声响(beep)、运行cmd、安全执行、shellcode等
lib/ 包含了sqlmap的多种连接库,如五种注入类型请求的参数、提权操作等。
plugins/ 数据库信息和数据库通用事项
tamper/ 绕过脚本
thirdparty/ sqlmap使用的第三方的插件
sqlmap.conf sqlmap的配置文件,如各种默认参数(默认是没有设置参数、可设置默认参数进行批量或者自动化检测)
sqlmap.py sqlmap主程序文件
sqlmapapi.py sqlmap的api文件,可以将sqlmap集成到其他平台上
swagger.yaml api文档
程序初始化
main()函数首先是执行5个函数,我们先依次看下每个函数的作用。
补丁包:dirtyPatches()
对于程序的一些问题及修复,写成了补丁函数,优先执行。
首先设定了 httplib 的最大行长度,接下来导入第三方的 windows 下的 ip地址转换函数模块,然后对编码进行了一些替换,把 cp65001 替换为 utf8 避免出现一些交互上的错误,这些操作对于 sqlmap 的实际功能影响并不是特别大,属于保证起用户体验和系统设置的正常选项,不需要进行过多关心

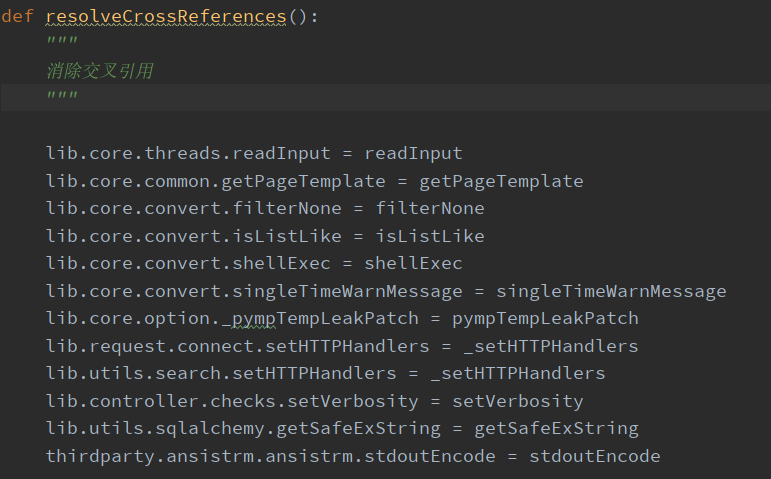
解决交叉引用:resolveCrossReferences()
为了消除交叉引用的问题,一些子程序中的函数会被重写,在这个位置进行赋值
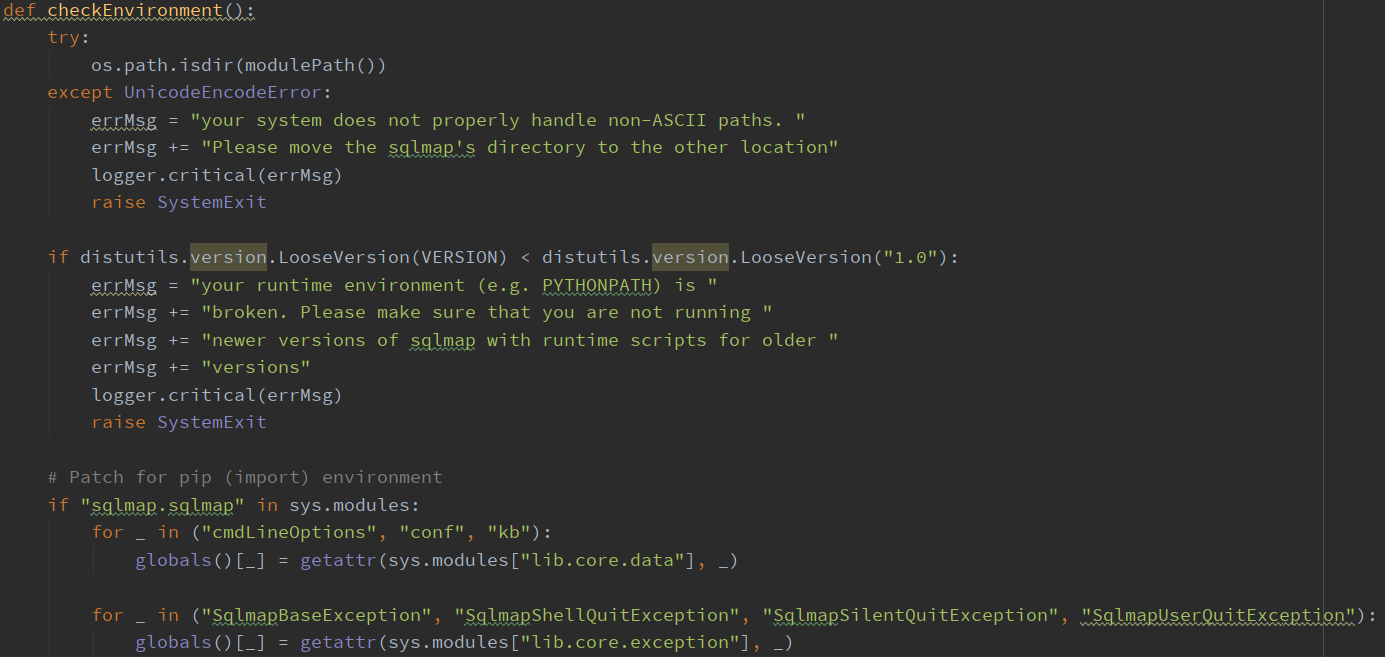
检查环境:checkEnvironment()
如名,函数的主要作用是检查环境
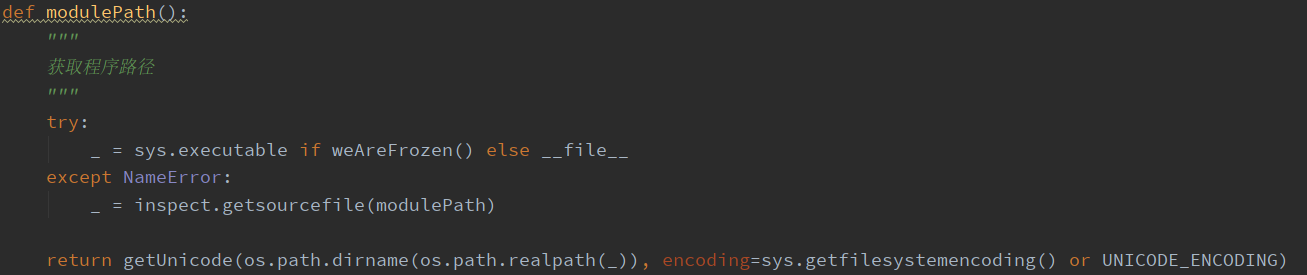
首先调用modulePath(),获取程序路径,判断程序是否由 py2exe 打包成 exe ,因为打包后无法使用 file 获得路径,为了防止乱码,使用getUnicode返回unicode编码的路径
然后使用LooseVersion判断python版本号,版本号小于1.0则报错并退出
接下来是对pip安装环境的补丁,可以看到是一些系统环境变量的设置

这里面定义个贯穿sqlmap全局的三个全局变量,cmdLineOptions,conf ,kb
绝对路径设置:setPaths()
配置程序文件的路径,并且判断.txt, .xml, .zip为扩展名的文件是否存在并且是否可读,这部分将预设的程序全部使用的信息都加载进来了,在后续的调用中就去各个变量、字典里取就可以了
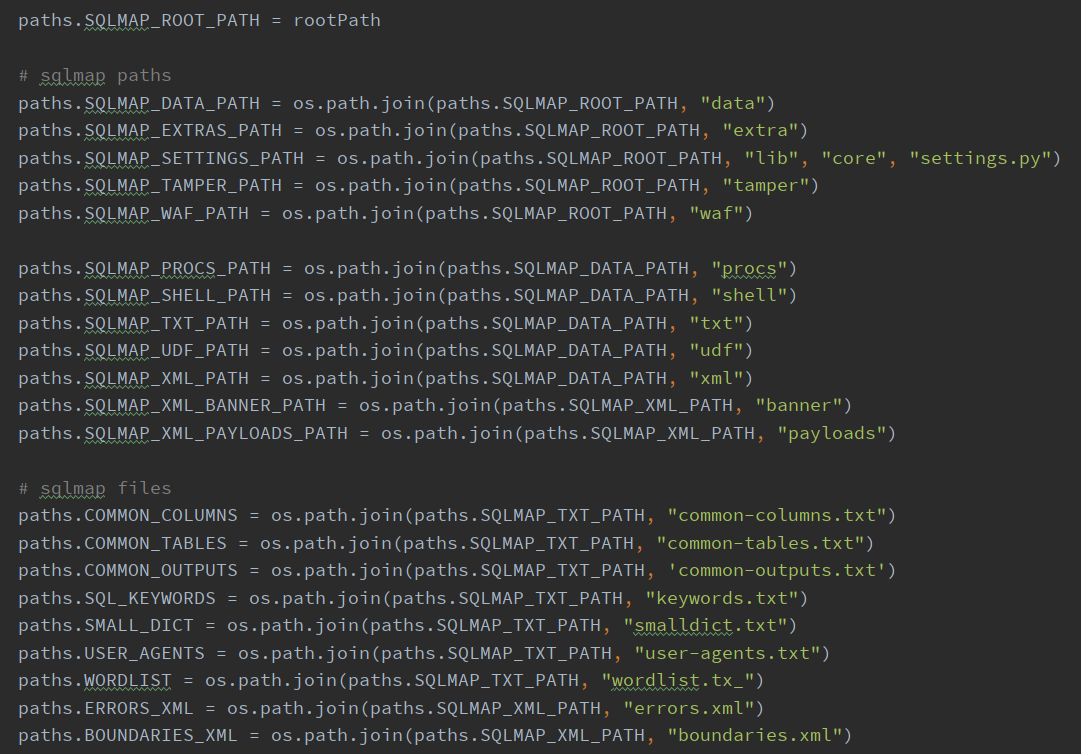
paths值为一个sqlmap自己封装的字典类型 AttribDict
为什么作者要自己封装一个字典类型呢?首先能看到的就是,可以直接使用访问属性的方式访问键值
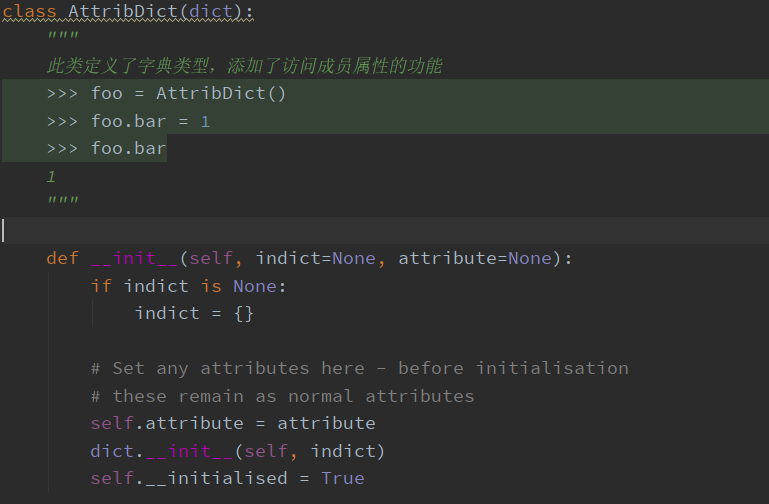
其次是作者定义了deepcopy,为了解决字典赋值传递后浅copy会修改原数据的问题
BANNER展示:banner()
函数判断执行参数中是否包含 --version 或 --api参数,或者在配置中是否将disableBanner中设置为True,如果都没有,那就将BANNER字符串赋值给 "_"
跨终端显示颜色则使用了第三方插件: colorama 库。跟一下变量BANNER

使用random.sample随机选择,然后使用正则替换,再跟一下BANNER,最后我们看到的就是SQLMAP的字符画了
实际上这部分看出来SQLMAP中间红色部分是随机的。。用了这么久竟然不知道。。

五个函数执行之后进入之后的流程,在 banner 打印之后,就是对命令行参数的操作了

cmdLineOptions 同样是一个 AttribDict,跟进 cmdLineParser
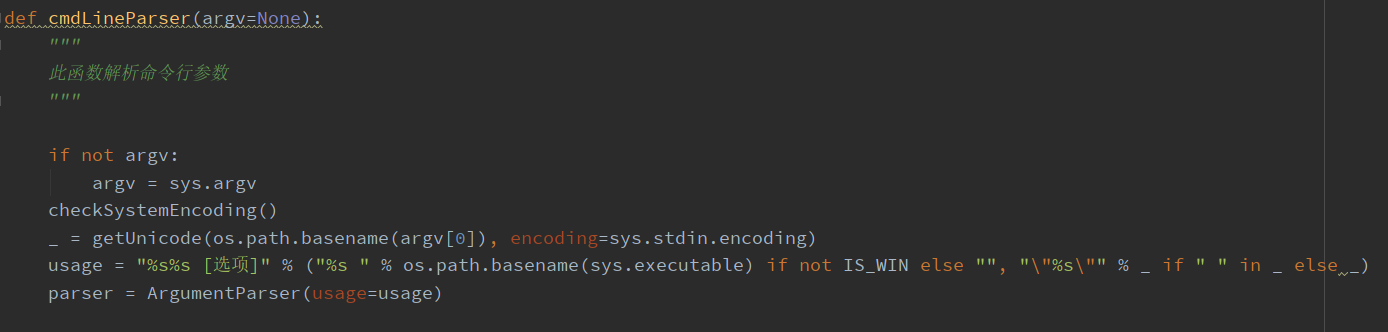
可以看到,对命令行参数的处理使用了 optparse,首先将获取到的命令行参数选项进行判断和拆分以后转变成dict键值对的形式存入到cmdLineOptions,然后传入initOption进行下一步操作

_setConfAttributes() 函数初始化了一些重要的属性值为空
_setKnowledgeBaseAttributes() 函数同样的初始化了一些重要的属性值到“知识库”中
_mergeOptions(inputOptions, overrideOptions) 函数主要的作用是将配置项中的参数和命令行获得的参数选项以及缺省选项进行合并,函数执行完毕将会将字典 mergedOptions 的值进行更新
检查是否通过中间进行标准输入:

检查是否调用api,如果是将会引入新的包,并重写sys.stdout和sys.stderr
判断过后打印法律声明和时间

然后就是执行 init() 函数进行程序的初始化,对用户定义参数进行配置和初始化。这部分后面再说。
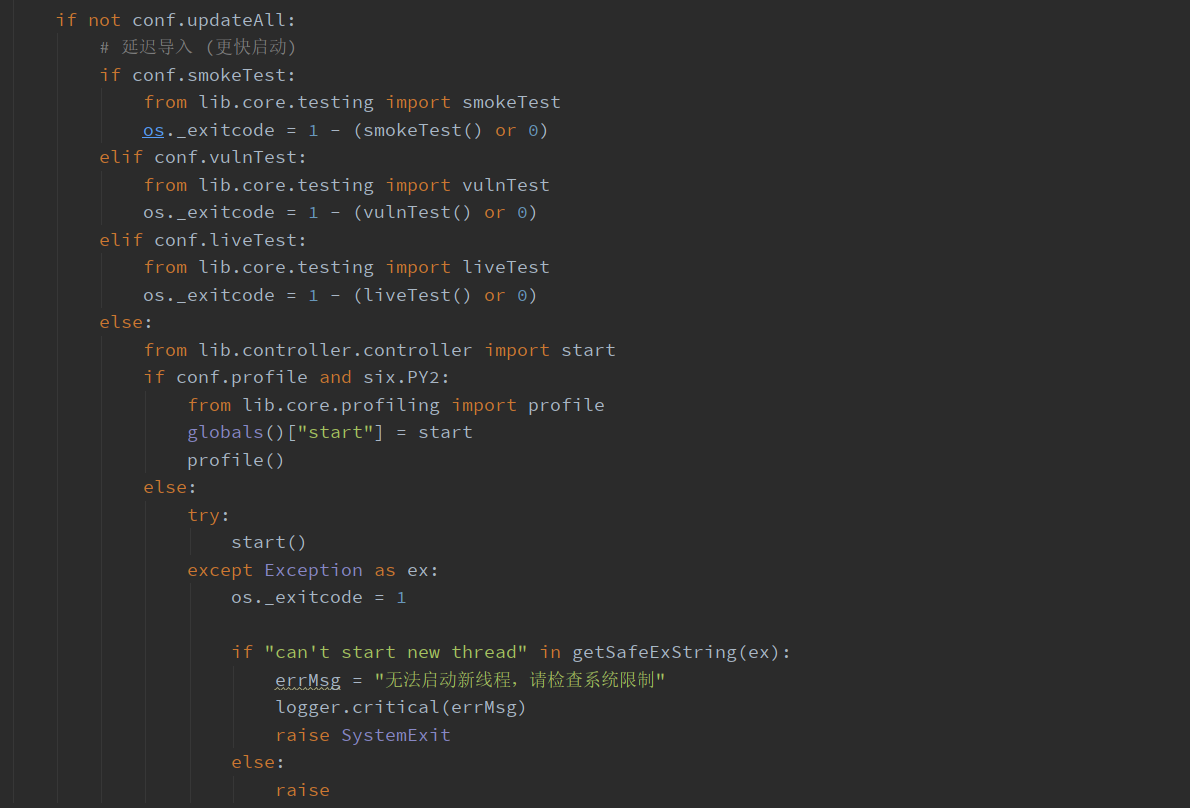
init() 函数执行过后就是执行测试以及start函数的执行了,我们看到了三个测试函数 smokeTest、vulnTest 和 liveTest 用于测试。
在不进行测试的情况下,导入包文件,在这一步才导入包,会使程序的启动更快。
然后判断 conf.profile ,这个程序调用的图形处理,暂时没弄明白是干嘛的。默认为空,程序直接走到else,启用start() 程序,也在后面说。
接下来是一大长串的 except 和最终的 finally
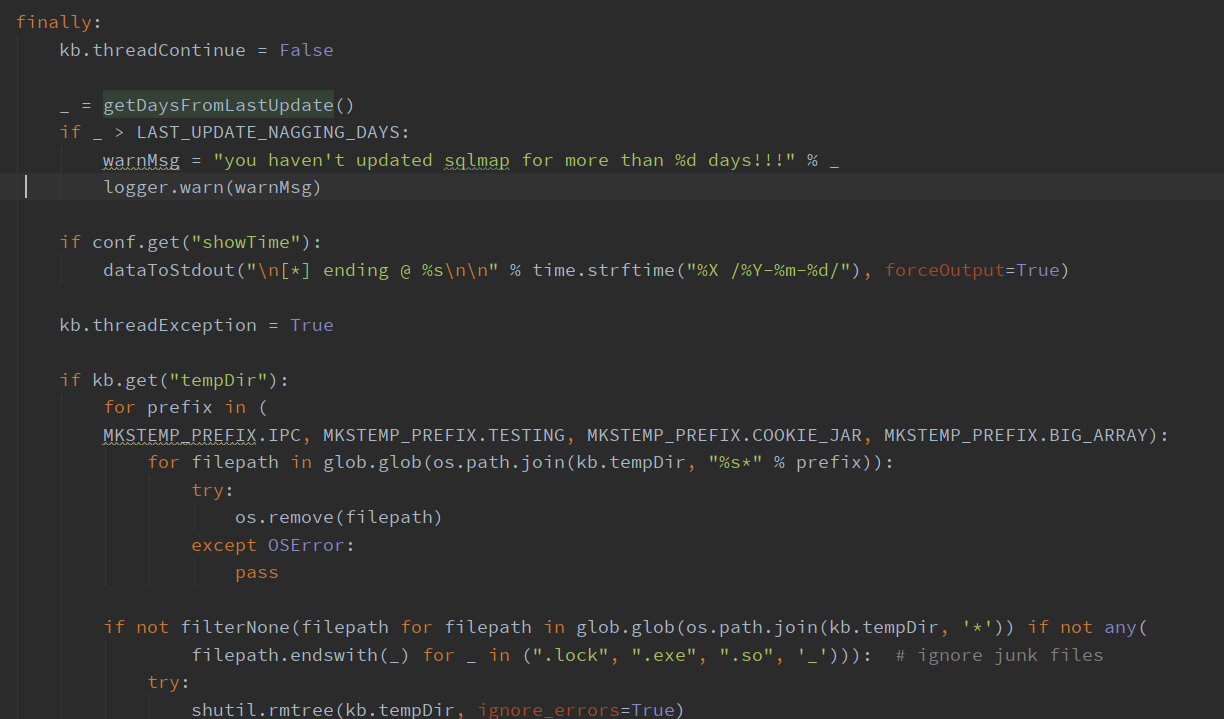
finally中包括了一些提示信息、清除临时目录文件、清除线程、清除配置等等一些文件
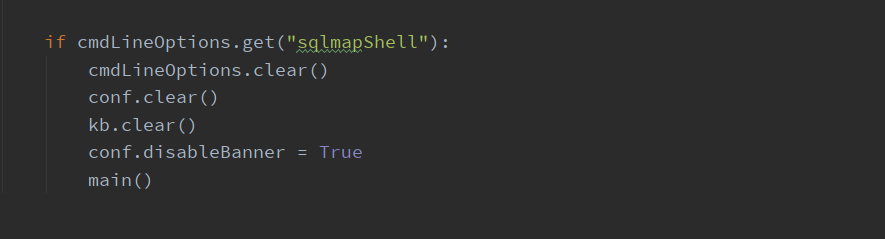
程序的最终结尾又是一个 if 判断,如果命令行参数里有sqlmapShell的话重新执行main函数,这实际上用一个死循环来完成的类似长连接的效果
命令行参数处理
文件位置:/lib/core/option.py
init() 函数将命令行参数和配置文件的选项值同时设置为程序配置
具体做了什么如下:
def init():
_useWizardInterface() # --wizard 用户向导程序,为了给初学者一个友好的界面
setVerbosity() # -v 设置debug等级
_saveConfig() # --save 将命令行选项保存到sqlmap配置INI文件中
_setRequestFromFile() # -r 从文件中设置http请求
_cleanupOptions() # 清理配置选项
_cleanupEnvironment() # 清理环境
_purge() # 安全删除(清除)sqlmap数据目录
_checkDependencies() # 检测丢失的依赖
_createHomeDirectories() # 在sqlmap的主目录中创建目录
_createTemporaryDirectory() # 创建运行的临时目录
_basicOptionValidation() # 检测选项是否有效
_setProxyList() # --proxy 设置代理列表
_setTorProxySettings() # --tor/--tor-type 设置Tor代理
_setDNSServer() # --dns-domain 设置DNS服务器
_adjustLoggingFormatter() # 调整日志格式
_setMultipleTargets() # 如果在多个目标中运行,只定义一种参数
_listTamperingFunctions()
_setTamperingFunctions() # --tamper 设置tamper脚本
_setPreprocessFunctions() # --preprocess 从给定的脚本加载预处理函数
_setTrafficOutputFP() # 设置记录http日志文件
_setupHTTPCollector() # 清理http收集
_setHttpChunked()
_checkWebSocket() # 检测websocket-client模块调用
parseTargetDirect() # 解析目标DBMS
if any((conf.url, conf.logFile, conf.bulkFile, conf.sitemapUrl, conf.requestFile, conf.googleDork, conf.liveTest)):
# 如果设置了上述选项,配置相关http
_setHostname() # 设置hostname
_setHTTPTimeout() # 设置超时时间
_setHTTPExtraHeaders() # 设置Headers
_setHTTPCookies() # 设置Cookies
_setHTTPReferer() # 设置Referer
_setHTTPHost() # 设置Host
_setHTTPUserAgent() # 设置UserAgent
_setHTTPAuthentication() # 设置HTTPAuthentication
_setHTTPHandlers() # 检查并设置所有HTTP请求的 HTTP/SOCKS代理。
_setDNSCache() # 设置DNS缓存
_setSocketPreConnect()
_setSafeVisit() # 检查并设置安全访问选项。
_doSearch() # 使用搜索平台搜索结果并存储
_setBulkMultipleTargets()
_setSitemapTargets() # 解析SitemapTargets中的目标
_checkTor() # 检测Tor
_setCrawler() # 设置爬虫
_findPageForms() # 寻找网页的表单
_setDBMS() # 强制DBMS选项
_setTechnique()
_setThreads() # 设置线程
_setOS() # 强制OS
_setWriteFile() # 写入文件
_setMetasploit() # Metasploit相关设置
_setDBMSAuthentication() # 设置数据库身份认证,来使用另一个身份执行
loadBoundaries() # 载入Boundaries
loadPayloads() # 载入Payloads
_setPrefixSuffix() # 设置前后缀
update() # 更新sqlmap
_loadQueries() # 加载查询的xml /查询
初始和解析HTTP相关内容
文件位置:/lib/controller/controller.py
start() 函数将调用函数,检查URL的连接稳定性,以及对所有的 GET/POST/Cookie/User-Agent 参数进行检查,检查他们是否为动态的,以及是否收到SQL注入的影响

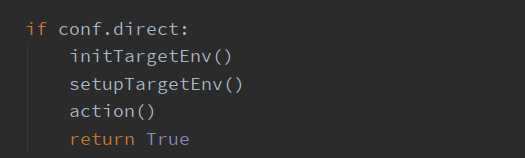
接下来是检测目标点是否存在SQL注入,conf.direct 参数为True,则用户配置直连数据库,将绕过下方的流程,直接检测:
initTargetEnv() 用于初始化目标环境
setupTargetEnv() 用于设置目标环境
action() 函数用于在受影响的URL参数上执行SQL注入攻击,并尝试提取 DBMS 或 操作系统相关信息
正常流程是将配置 conf 字典中的目标URL、方法、data、cookie中添加到 kb.targets 中,然后进一步判断,如果没有就报错,然后打印出目标个数
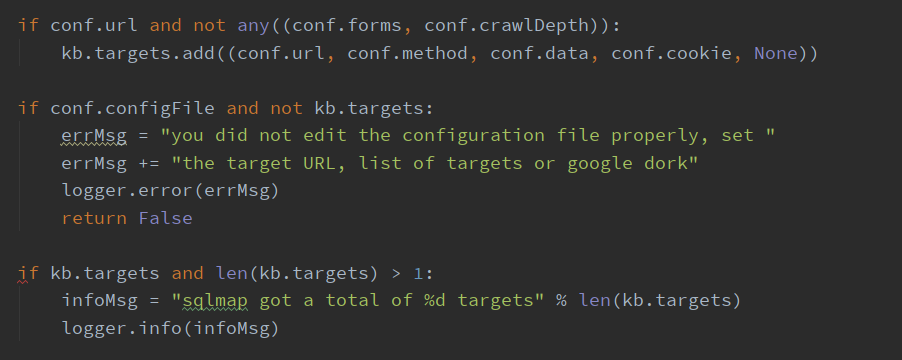
然后是判断网络连接数
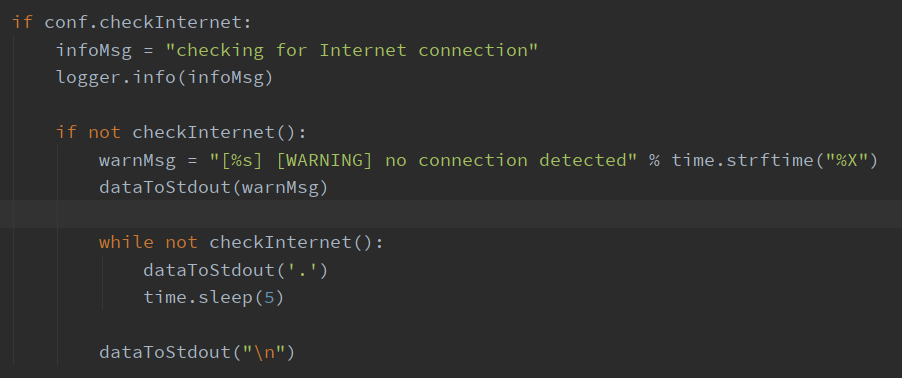
设置HTTP连接的一些参数,都是python数据类型转换,没什么好说的
initTargetEnv() 函数主要就是完成全局变量 conf 和 kb 的初始化工作
parseTargetUrl() 函数主要通过正则完成针对目标网址的解析工作,如获取协议名、路径、端口、请求参数等信息

测试过的 url 参数信息会保存到 kb.testedParams 中,所以在进行test之前,会先判断当前的url是否已经test过,如果没test过的话,则 testSqlInj = True,否则 testSqlInj = False,如果值为False ,到后续就不会再执行注入攻击了,因此接下来这段代码就是在判断目前要测试的点是否测试过,测试过是否为注入点等,并修改 testSqlInj 的值,最后进行判断是否要跳过这个点

接下来是判断是否存在多个目标,依次与用户交互确认是否进行测试
然后执行 setupTargetEnv() 函数,该函数主要包含3个子功能:
创建保存目标执行结果的目录和文件
将 get 或 post 发送的数据解析成字典形式,并保存到 conf.paramDict 中
读取session文件(如果存在的话),并读取文件中的数据,保存到 kb 变量中
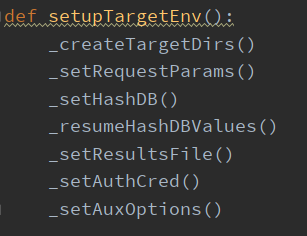
检查连接、是否有用户自定义的 String(字符)或 Regexp(正则):

然后是 checkWaf() 函数,检测是否有WAF,之后再说
检查空连接(nullConnection)、检查页面稳定性,以及对参数、测试列表进行排序
什么是 nullConnection?根据官方手册,是一种不用获取页面内容就可以知道页面大小的方法,这种方法在布尔盲注中有非常好的效果,可以很好的节省带宽。
如果启用 --null-connection,计算页面相似率就只是很简单的通过页面的长度来计算,这部分后面会提到
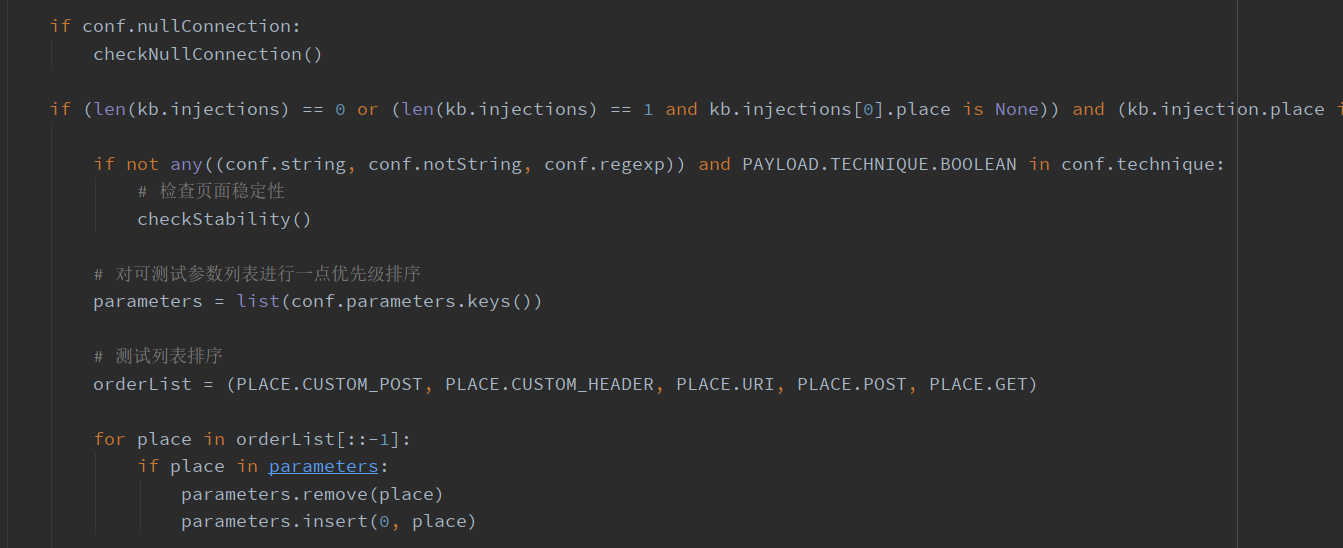
然后根据参数中的 level 级别判断是否进行 cookie 、referer、ua的注入
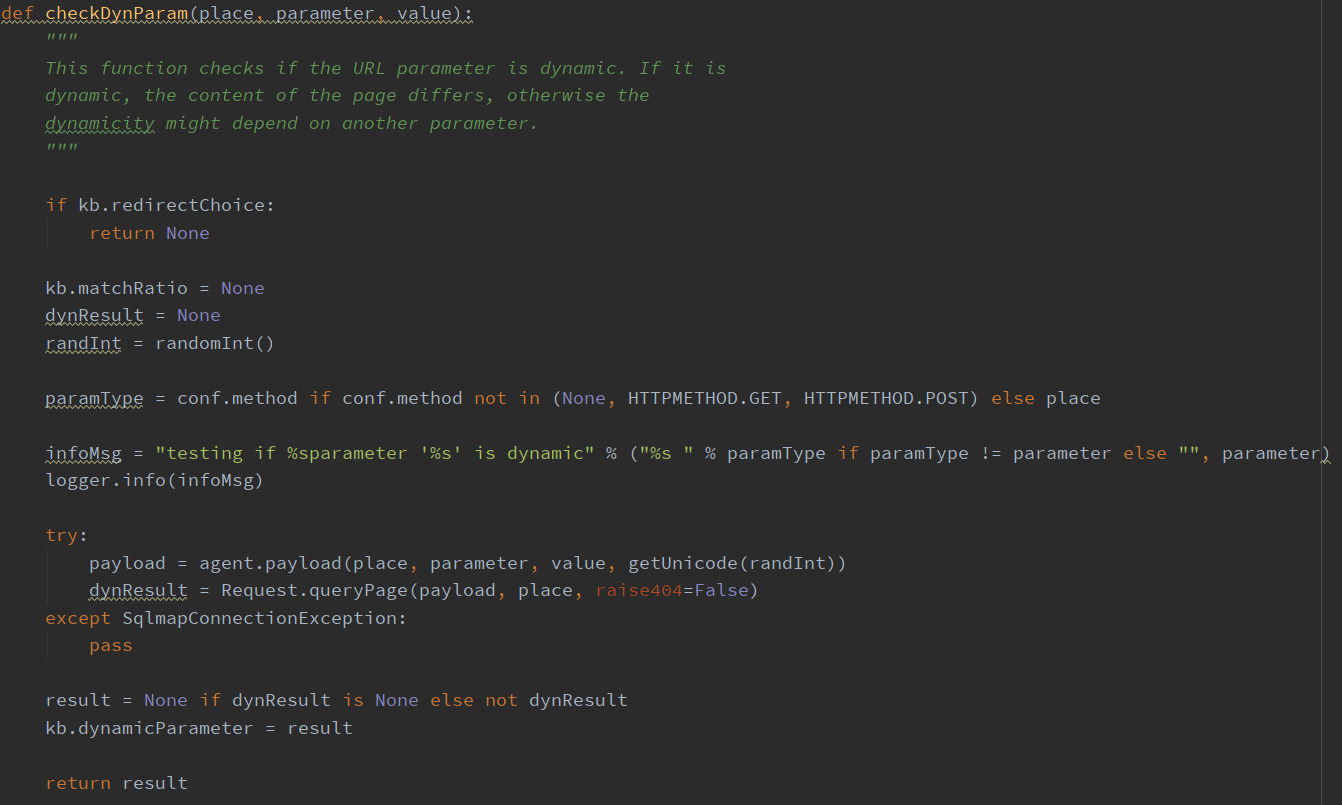
使用函数 checkDynParam() 判断参数是否是动态,如果不是动态则需要选取其他参数。其核心是给参数另外一个随机值,然后通过选择参数及对于页面的各种规则的判断,计算出两个页面的相似比率,来判定是否为动态。
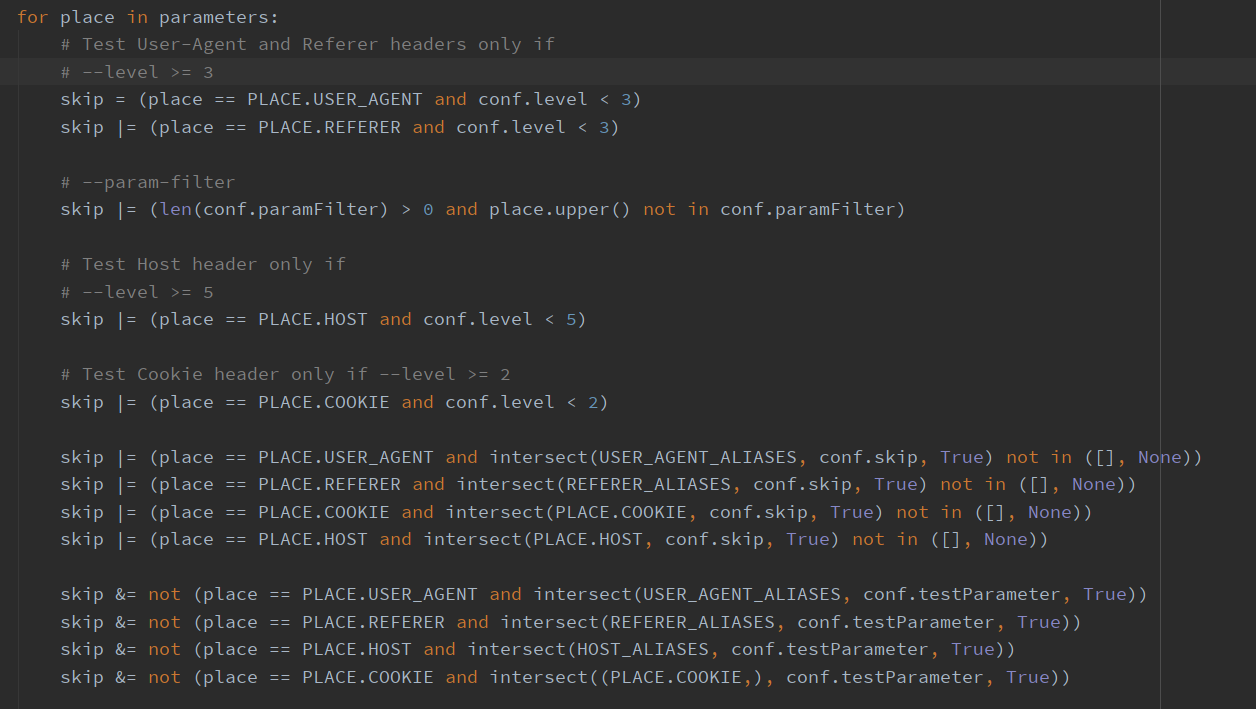
根据level等级不同的情况判断是否应该跳过参数
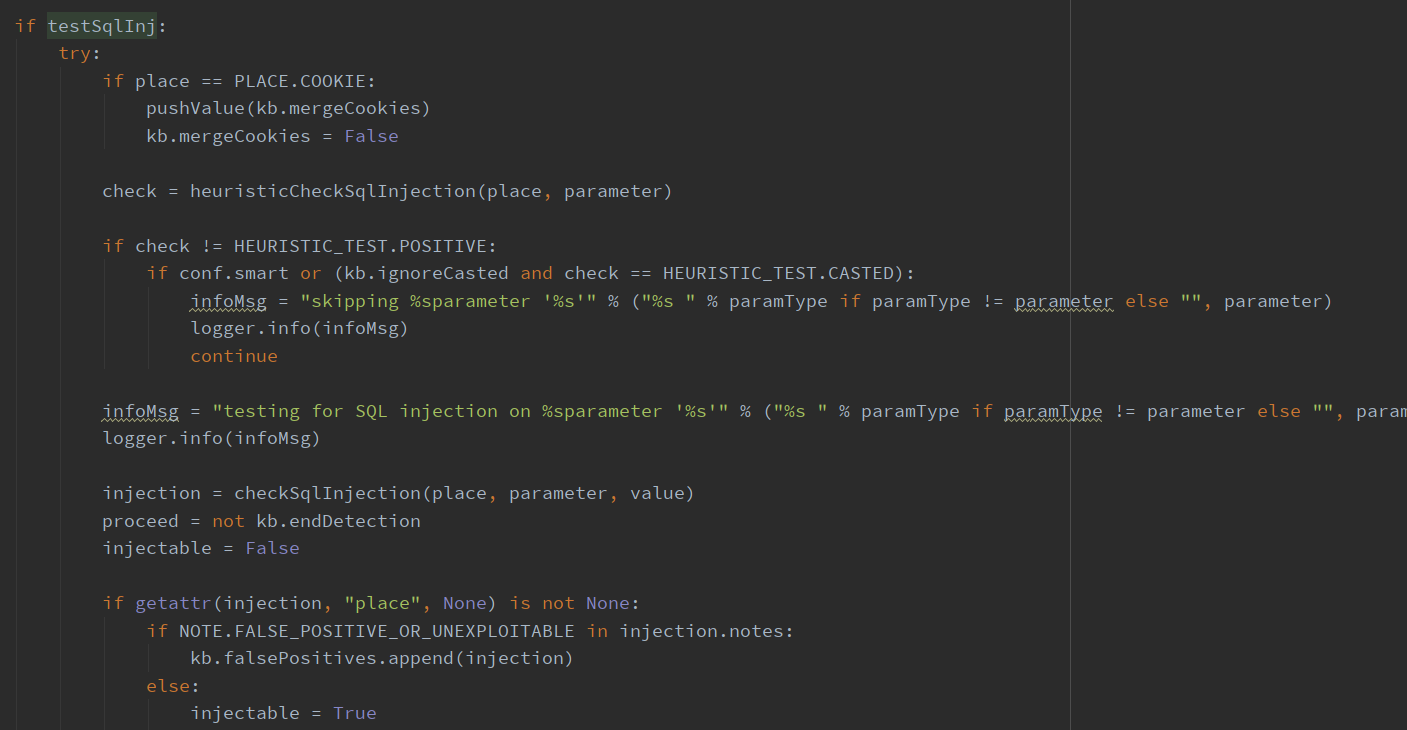
如果参数为动态,将接下来进入检测SQL注入测试环节,程序将调用 heuristcCheckSqlInjection() 函数进行启发式检测,再得到 POSITIVE 的结果后,再调用 checkSqlInjection() 进行注入点检查,再次确认有漏洞且不是 FALSE_POSTTIVE后,将injectable 设为True,中间产生的数据放入相应的数据集中,执行下一步,这两个函数的内容也会稍后详细说。
如果没检查出漏洞点,将根据不同情况提供各种各样的建议参数
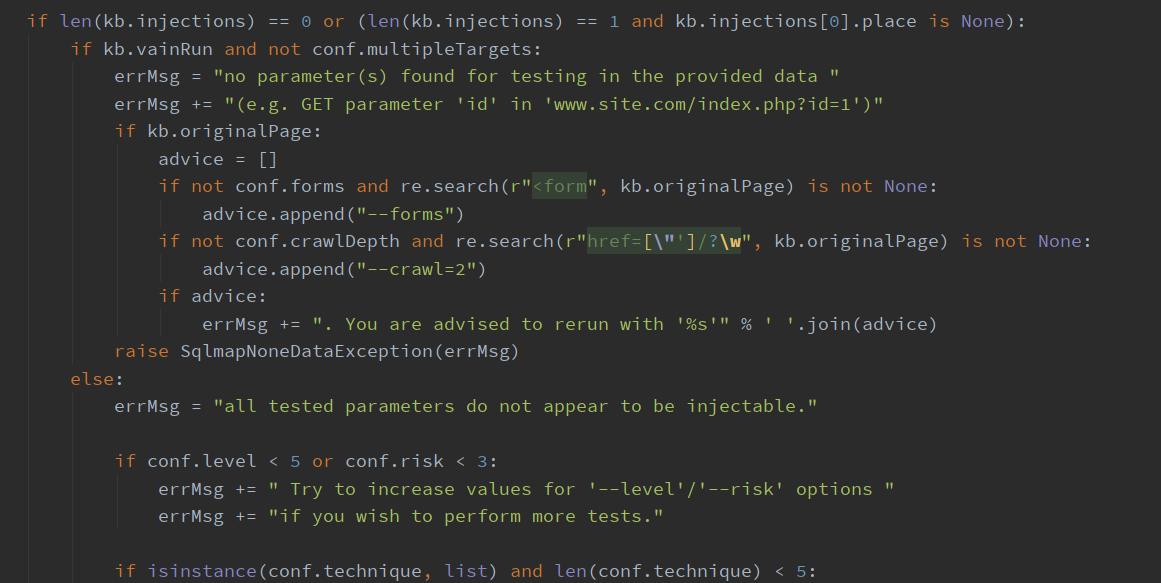
否则将结果进行保存
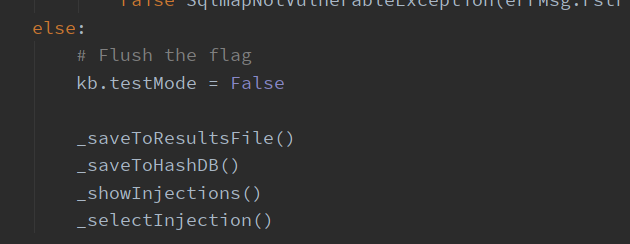
二次确认有注入数据后,将与用户交互确认,并执行 action() 函数,才是开始跑数据了。这部分后续会详细介绍。
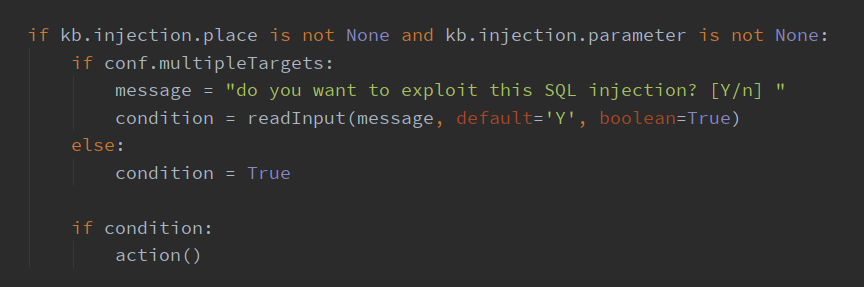
中间又是一大堆的 except 异常处理之后,finally 中显示了http错误代码,并提示最大连接限制的情况
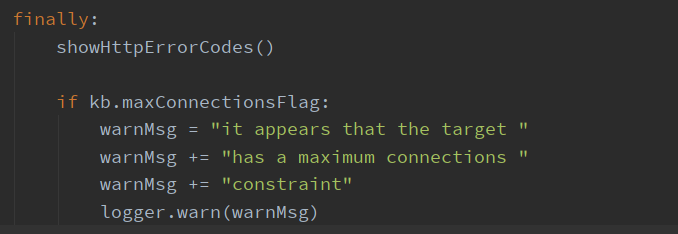
最后提示结果文件名