学习JVM虚拟机原理总结
0x00:JAVA虚拟机的前世今生
1991年,在Sun公司工作期间,詹姆斯·高斯林和一群技术人员创建了一个名为Oak的项目,旨在开发运行于虚拟机的编程语言,允许程序多平台上运行。后来,这项工作就演变为Java。随着互联网的普及,尤其是网景开发的网页浏览器的面世,Java[1] 成为全球流行的开发语言。因此被人称作Java之父。 1996年1月Sun公司发布了Java的第一个开发工具包(JDK 1.0),2009 年Oracle收购sun后到今天己经到了JDK9。
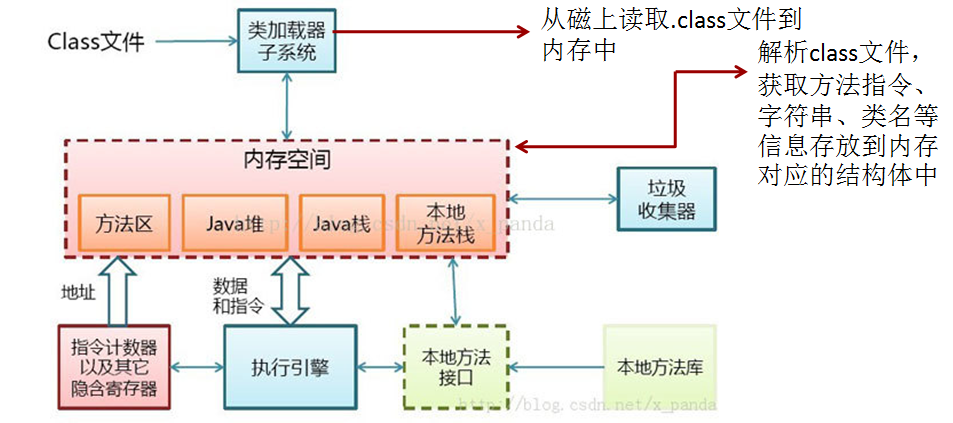
java.exe是java class文件的执行程序,但实际上java.exe程序只是一个执行的外壳,它会装载jvm.dll(linux下为:libjvm.so),这个动态连接库才是java虚拟机。
JVM在哪里?
在windows平台上虚拟机的位置在:
%JAVA_HOME%\jre\bin\client\jvm.dll
%JAVA_HOME%\jre\bin\server\jvm.dll
0x01:JAVA虚拟机跨平台
虚拟机是一种抽象化的计算机,通过在实际的计算机上仿真模拟各种计算机功能来实现的。Java虚拟机有自己完善的硬体架构,如处理器、堆栈、寄存器等,还具有相应的指令系统。Java虚拟机屏蔽了与具体操作系统平台相关的信息,使得Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行, 来一张从java原码编译到执行的大致流程图吧。如下图
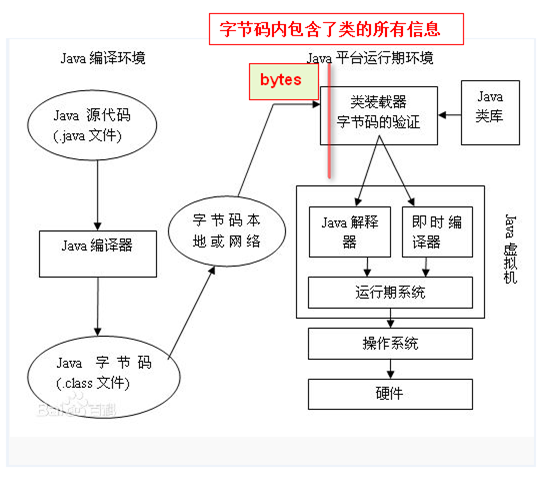
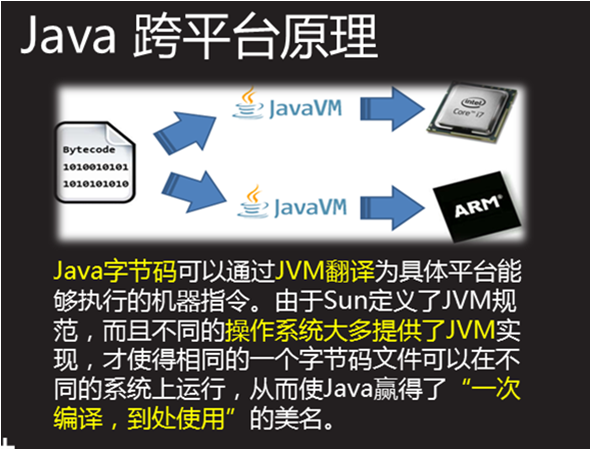
0x02:class文件格式分析
当我们写好的.java 源代码,最后会被Javac编译器编译成后缀为.class的文件,该类型的文件是由字节组成的文件,又叫字节码文件。流程图如下所示:
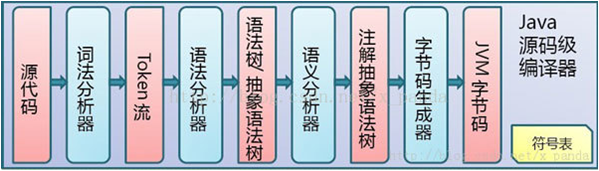
那么,class字节码文件里面到底是有什么呢?它又是怎样组织的呢?让我们先来大概了解一下他的组成结构吧。

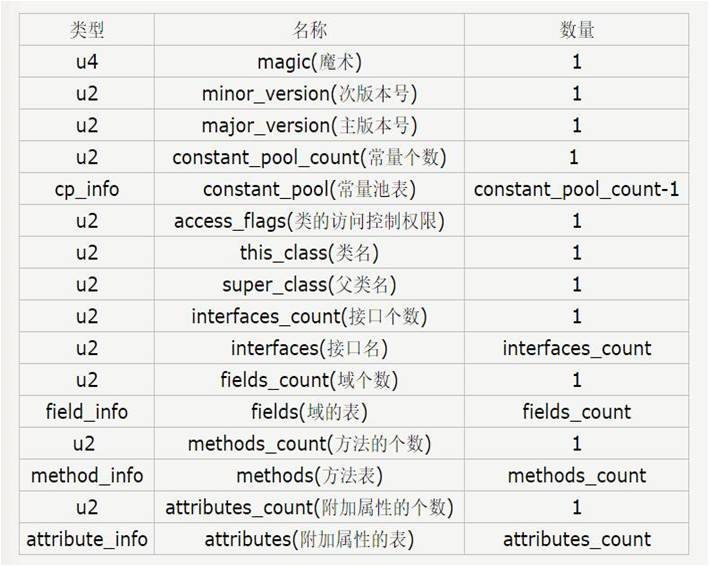
1. 魔数(magic):所有的由Java编译器编译而成的class文件的前4个字节都是“0xCAFEBABE” 它的作用在于:当JVM在尝试加载某个文件到内存中来的时候,会首先判断此class文件有没有JVM认为可以接受的“签名”,即JVM会首先读取文件的前4个字节,判断该4个字节是否是“0xCAFEBABE”,如果是,则JVM会认为可以将此文件当作class文件来加载并使用。
2.版本号(minor_version,major_version): JVM在加载class文件的时候,会读取出主版本号,然后比较这个class文件的主版本号和JVM本身的版本号,如果JVM本身的版本号 < class文件的版本号,JVM会认为加载不了这个class文件,会抛出我们经常见到的"java.lang.UnsupportedClassVersionError: Bad version number in .class file " Error 错误;反之,JVM会认为可以加载此class文件,继续加载此class文件。
3. 类中的method方法的实现代码---即机器码指令存放到这里,JVM执行时会根据结构定位到具体的方法指令。
4.class文件结构文件在硬盘上表现如下:

上图是用16进制工具打开时就可以分析具体的字节码对应在结构体中的项,JVM在执行时也是通过解析这些字节码。
0x03:JAVA虚拟机引擎工作原理
前面我们分析完class文件结,知道里面存放有方法Java字节码,执行由JVM执行引擎来完成,大致流程图如下所示:
从源到到执行大致流程图如下所示:
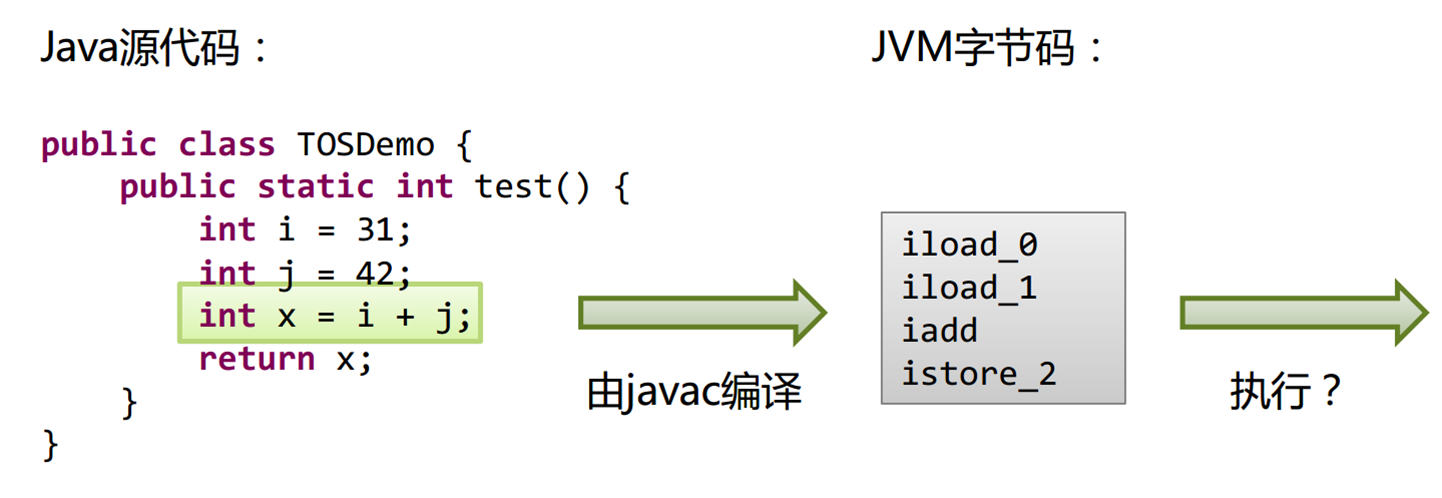
一个简单的java程序执行示例:

JVM概念上工作原理图:
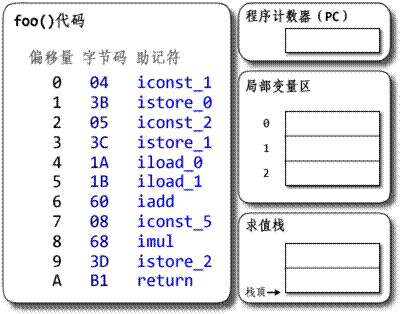
第一代引擎简单实现:
Java虚拟机引擎和真实的计算机一样,运行的都是二进制的机器码;CPU指令运行流程都是通过->取指->译码->执行,这三个基本过程完成一个程序的执行 。下面将通过一个非常简单的例子,带你感受一下Java虚拟机运行机器码的过程和其工作的基本原理。假如有如下java代码,计算两个整数之和:
int run(int a, int b){
return a+b;
}
通过编译后生成的字节码为0x88(代表加操作);那么我们要模拟java虚拟机来执行这指令时将是如下这样(jvm主要由C、C++、汇编来开发,这里我用C来演示):
#include(stdio.h)
int jvm(int a, int b, int opcode);
int main(){
int a = 5;
int b = 3;
int code = 0x88;
int result = jvm(a, b, code);
printf(“result = %d\n”,result);
return;
}
int jvm(int a, int b, int opcode){
if(0x88 == opcode)
return a+b;
}
这个示例程序中的jvm函数可以看成是执行引擎了,这是世界上最精简的小巧的虚拟机执行引擎啦,执行引擎接到操作数和指令编码,然后判断指令是否为加操作,如果是就便对入栈的两个操作数执行加法运算并返回结果。第一代jvm引擎就是这么简单,然而这种方式却有一个比较大的缺陷->运行时效率低下(编译器会产生一些不必要的代码)。所以第一代java虚拟机常被吐槽。
可移植性:返种方式容易用高级语言实现,所以容易达到高可移植性 。
第二代引擎简单实现:
第二代通过汇编精确控制 (不是直接用汇编写的 ,通过内联机器码 ),其实就是使用机器码模板方式先写好一些功能代码对应与class字节码对应起来,称为模板解释器
上面我们用0x88字节码在jvm中表示加法,如果要用汇编语言编写实现两个数相加时如下所示:
Push %ebp
Mov %esp, %ebp
Mov 0xc(%ebp), %eax //将操作1数从栈中取出放到eax寄存器
Mov 0x8(%ebp),%edx //将操作2数从栈中取出放到edx寄存器
Add %edx,%eax //将两个数相加后存放在eax中
Pop %ebp
Ret
其它指令也有类似的功能代码。
第三代引擎介绍:
虽然将字节码对应着编写好的汇编模板直接运行其效率相比使用C语言解释执行,它已经提高了很多,但是一个字节码须机对应很多的汇编代码,指令数量增多执行时间成本必然增加,因此运行效率仍然不够高。
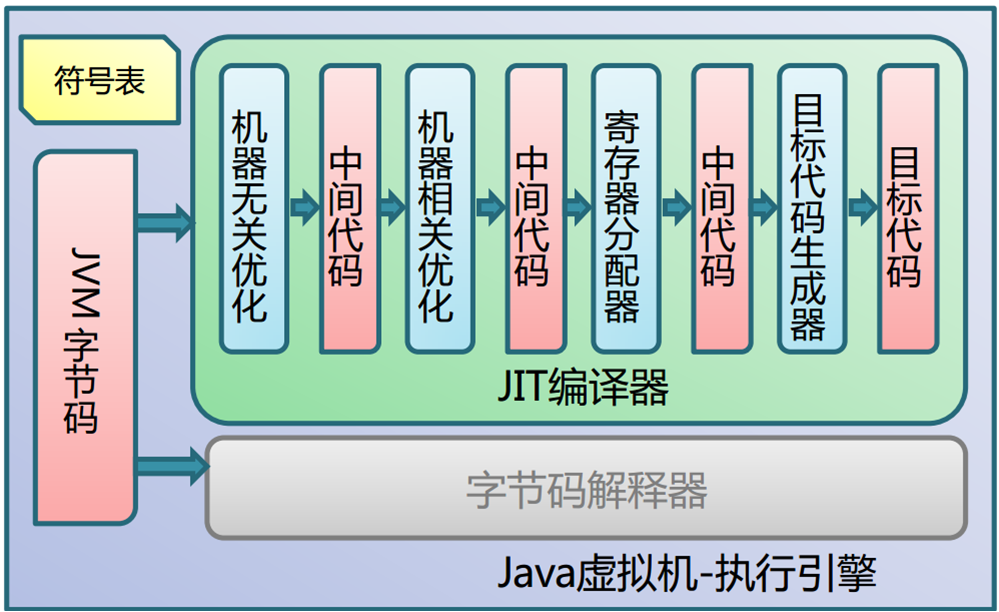
为了能够进一步提升性能,jvm在运行时将字节码直接编译为对应平台本地机器指令 ,也就是JIT编译技术,”及时编译”,(比如安卓5.0以上的ART模式就使用了AOT技术,安装app时直接将字节码编译成对应平台本地机器指令,运行速度就要快很多)。
动态编译具有一些缺点,大量的初始编译可能直接影响应用程序的启动时间。目前jvm主要是模板解释与编译混合执行。 通过java –version命令可以查看:

对只执行一次的代码做JIT编译再执行,可以说是得不偿失。编译过程慢,须要词法分析,语法分析,生成语树,生成本地机器码。对只执行少量次数的代码,JIT编译带来的执行速度的提升也未必能抵消掉最初编译带来的开销。只有对频繁执行的代码,JIT编译才能保证有正面的收益。
况且,并不是说JIT编译了的代码就一定会比解释执行快。切不可盲目认为有了JIT就可以鄙视解释器了,还是得看实现细节如何。
缺点
但是,动态编译确实具有一些缺点,这些缺点使它在某些情况下算不上一个理想的解决方案。例如,因为识别频繁执行的方法以及编译这些方法需要时间,所以应用程序通常要经历一个准备过程,在这个过程中性能无法达到其最高值。在这个准备过程中出现性能问题有几个原因。首先,大量的初始编译可能直接影响应用程序的启动时间。
JIT编译技术,”及时编译”流程图如下:
0x04:JAVA关键字volatile分析
Java 语言提供了一种稍弱的同步机制,即 volatile 变量.用来确保将变量的更新操作通知到其他线程,保证了新值能立即同步。
下面来看一个示例:


JVM 可以-client与-Server模式来运行一个程序,区别:当虚拟机运行在-client模式的时候程序启动快, -Server模式启动时,速度较慢,但是一旦运行起来后,性能将会有很大的提升, -Server模式要比-client性能快10%左右,原因是模式不同代码优化级别不同。 -Server一般在服务器使用。我们看看同一个代码在不同模式下运行情况:
上述代码在-client模式下运行正常结束,在-server模式运行上述代码,永远不会停止 。
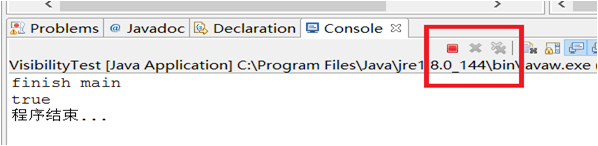
使用jps命令可以查看到进程一直存在,内存一直在上升。
程序比较简单,在主线程中启动一个线程,这个线程不停的对局部变量做自增操作,主线程休眠 1 秒中后改变启动线程的循环控制变量,想让它停止循环。这个程序在 client 模式下是能停止线程做自增操作的,但是在 server 模式先将是无限循环。若是改成private volatile boolean stop;
我们通过HSDIS反汇编插件将JVM动态生成的本地代码还原为汇编代码输出,这样我们就可以通过输出的代码来分析问题。
HSDIS是由Project Kenai提供并得到Sun官方推荐的HotSpot VM JIT编译代码的反汇编插件,作用是让HotSpot的-XX:+PrintAssembly指令调用它来把动态生成的本地代码还原为汇编代码输出,同时还生成了大量非常有价值的注释,这样我们就可以通过输出的代码来分析问题。读者可以根据自己的操作系统和CPU类型从Kenai的网站上下载编译好的插件,直接放到JDK_HOME/jre/bin/client和JDK_HOME/jre/bin/server目录中即可。如果没有找到所需操作系统(譬如Windows的就没有)的成品,那就得自己拿源码编译一下,或者去HLLVM圈子中下载也可以,这里也有 win32 和 win64 编译好的。
-server
-Xcomp
-XX:+UnlockDiagnosticVMOptions
-XX:CompileCommand=dontinline,*VisibilityTest.run
-XX:CompileCommand=compileonly,*VisibilityTest.run
-XX:+PrintAssembly
其中
-Xcomp 参数-Xcomp是让虚拟机以编译模式执行代码,这样代码可以偷懒,不需要执行足够次数来预热都能触发JIT编译。
-XX:CompileCommand=dontinline,*VisibilityTest.run 这个表示不要把 run 方法给内联了,这是解决内联问题。
-XX:CompileCommand=compileonly,*VisibilityTest.run 这个表示只编译 run 方法,这样的话只会输出sum方法的ASM码。
-XX:+UnlockDiagnosticVMOptions 这个参数是和 -XX:+PrintAssembly 一起才能生效答应汇编代码
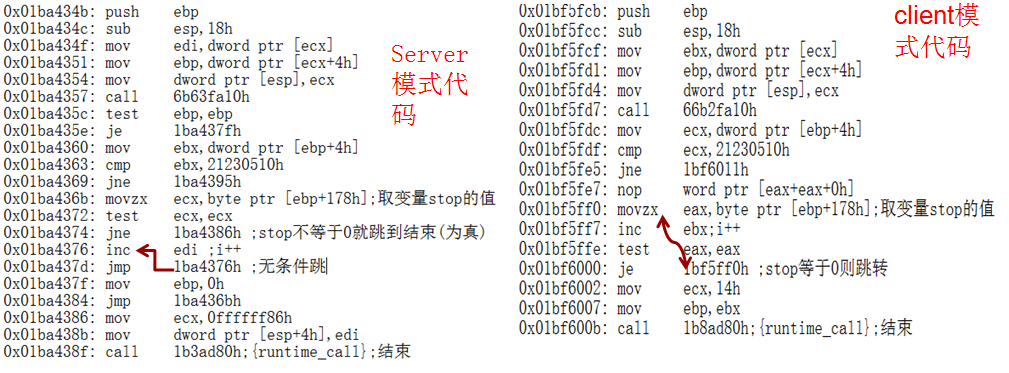
看完上面汇编代码发现Server模式代码没有去取stop值一直执行jmp了,Client模式下去取Stop值并做判断了,所以才能正常结束。
解决办法就是在变量前加volatile关键字,这样在jit 编译时就不用代码优化了,能正常结束。
0x05:JVM虚拟机GC算法
JVM GC回收哪个区域内的垃圾?
垃圾收集 Garbage Collection 通常被称为“GC”,并非是java独有,它诞生于1960年 MIT 的 Lisp 语言,经过半个多世纪,目前已经十分成熟了。
jvm 中,程序计数器、虚拟机栈、本地方法栈都是随线程而生随线程而灭,栈帧随着方法的进入和退出做入栈和出栈操作,实现了自动的内存清理,因此,我们的内存垃圾回收主要集中于 java 堆和方法区中,在程序运行期间,这两部分内存的分配和使用都是动态的。
JVM GC怎么判断垃圾可以被回收了?
· 对象没有了引用
· 发生异常
· 程序在作用域正常执行完毕
· 程序执行了System.exit()
· 程序发生意外终止(被杀线程等)
JVM GC 算法:
.引用计数器算法
.根搜索算法
.复制算法
.标记 - 清除算法
.标记 - 整理算法
.分代收集算法
下面分析算法原理:
引用计数法:
当创建对象的时候,为这个对象在堆栈空间中分配对象,同时会产生一个引用计数器变量,同时引用计数器变量为1,当有新的引用的时候,引用计数器继续+1,而当其中一个引用销毁的时候,引用计数器-1,当引用计数器被减为零的时候,标志着这个对象已经没有引用了,可以回收了!当我们的代码出现下面的情形时,该算法将无法适应。
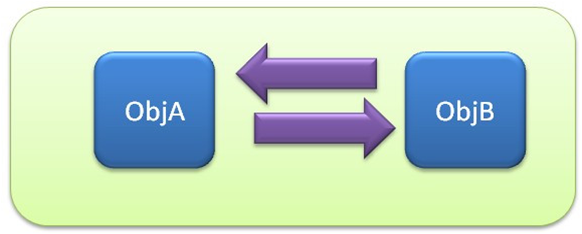
这样的代码会产生如下引用情形 objA指向objB,而objB又指向objA,这样当其他所有的引用都消失了之后,objA和objB还有一个相互的引用,也就是说两个对象的引用计数器各为1,而实际上这两个对象都已经没有额外的引用,已经是垃圾了。
根搜索算法:
如果把所有的引用关系看作一棵树,从一个节点GC ROOT开始,寻找对应的引用节点,找到这个节点以后,继续寻找这个节点的引用节点,当所有的引用节点寻找完毕之后,剩余的节点则被认为是没有被引用到的节点,即无用的节点。
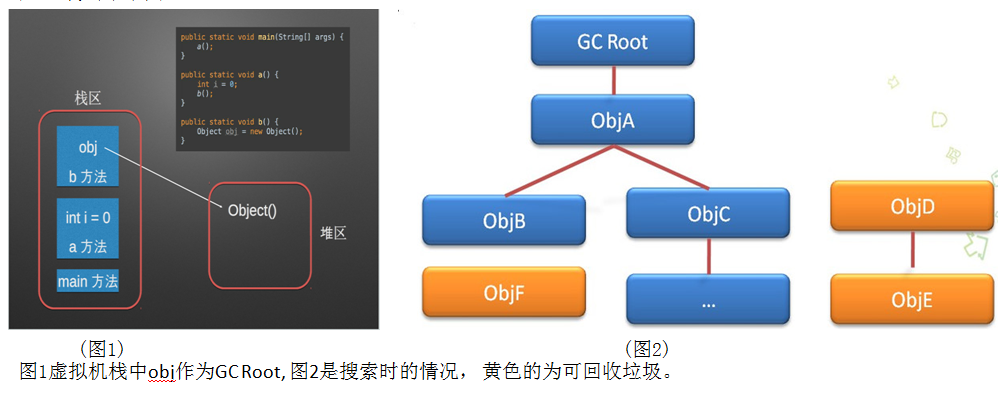
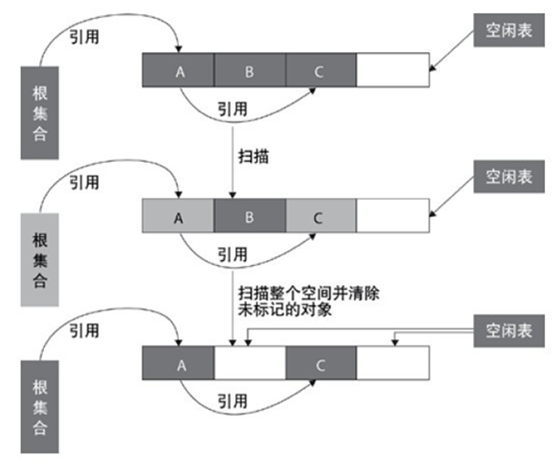
标记 - 清除算法:
标记-清除算法采用从根集合进行扫描,对存活的对象对象标记,标记完毕后,再扫描整个空间中未被标记的对象,进行回收,如下图所示。
标记-清除算法不需要进行对象的移动,并且仅对不存活的对象进行处理,在存活对象比较多的情况下极为高效,但由于标记-清除算法直接回收不存活的对象, B清楚后就空出来了,导致内存不连续,因此会造成内存碎片!
内存碎片:导致内存不连续,即使空闲的内存足够多,也不一定能分配出足够大小的内存,同时还会降低内存分配的效率。
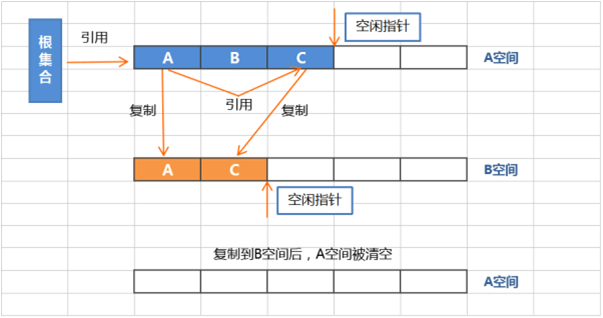
复制算法:
复制算法将内存划分为两个区间,使用此算法时,所有动态分配的对象都只能分配在其中一个区间(活动区间),而另外一个区间(备用区间)则是空闲的。
当扫描完毕活动区间后,并将存活对象复制到一块新的,没有使用过的空间中(备用空间),此时原本的空闲区间变成了活动区间。下次GC时候又会重复刚才的操作,以此循环。
复制算法在存活对象比较少的时候,极为高效,但是带来的成本是牺牲一半的内存空间用于进行对象的移动。所以复制算法的使用场景,必须是对象的存活率非常低才行,而且最重要的是,我们需要克服50%内存的浪费。
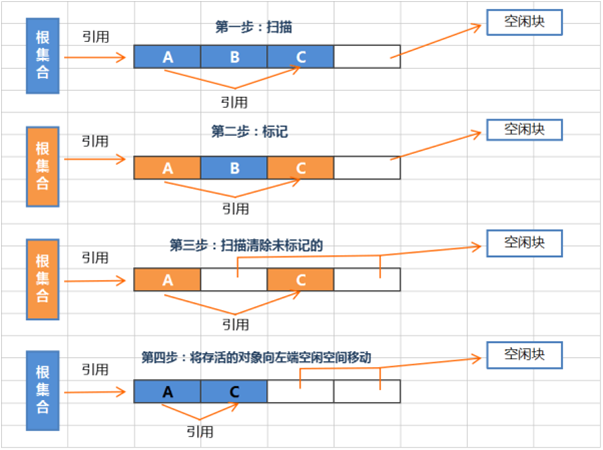
标记 - 整理算法:
标记-整理算法采用 标记-清除 算法一样的方式进行对象的标记与清除,但在回收对象占用的空间后,会将所有存活的对象移动,并更新对应的指针。标记-整理 算法是在标记-清除 算法之上,又进行了对象的移动排序整理,因此成本更高,但却解决了内存碎片的问题。
分代收集算法:
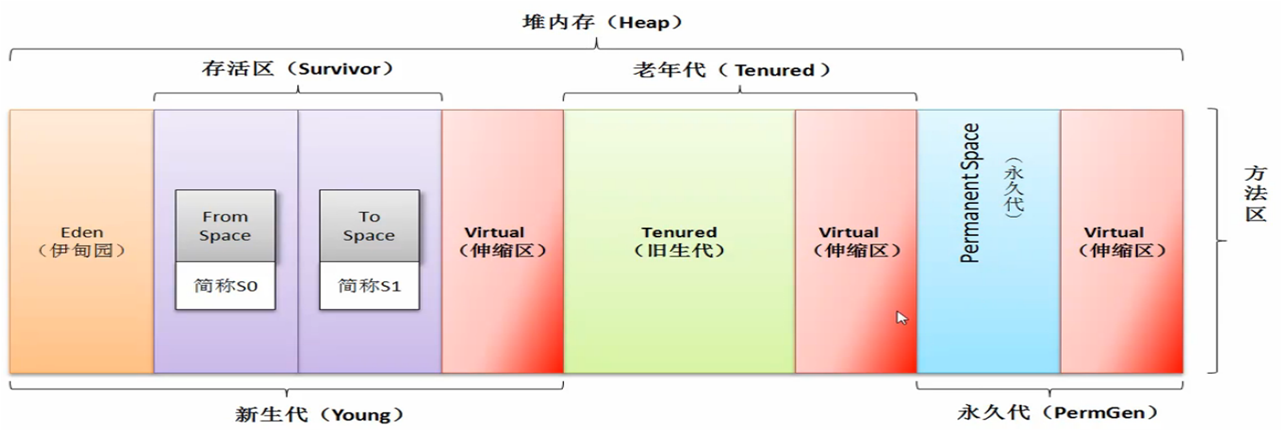
JVM执行GC时须机停止除GC所需的线程外所有线程的执行(stop-the-world ),(这就好比当有人打扫卫生时我们须要停下来不要随意走动产生垃圾),JVM为了减少GC做了很多优化,所以就有了分代收集算法,分代的垃圾回收策略,是基于这样一个事实:不同的对象的生命周期是不一样的。因此,不同生命周期的对象可以采取不同的收集方式,以便提高回收效率。
新生代(Young generation)->老年代(Old generation)->持久代(Permanent generation)
对象在刚刚被创建之后,是保存在伊甸园空间的(Eden)。那些新生代Gc后存活的对象会存放幸存者空间(Survivor),幸存者空间Gc 15次后还活着的转存到老年代空间(Old generation),持久代用于保存类常量以及字符串常量,这个区域不是用于存储那些从老年代存活下来的对象,这个区域的对象与程序同生共死。
0x06:总结
我不认为为了使用好Java必须去了解Java底层的实现。许多没有深入理解JVM的开发者也开发出了很多非常好的应用,但是,如果你要定制与优化JVM(比如阿里淘宝jvm深度定制解决高并发)就须要深入了解JVM原理了。
官方JVM是一个通用产品,一大目标是尽可能的兼容各个平台和满足大部分应用场景的需求。由于开发和维护资源有限,对于特定平台和应用场景而言,官方JVM在性能和功能上,都有取舍。比如所使用的平台是统一的x86平台,应用也有自己的场景特点。针对平台和应用场景的极致的优化,可以做得更多。
除了我以上提到的技术,JVM还是用了其他的很多特性和技术。由于时间和水平有限,我没有对它们进行讲解。如果你对JVM感兴趣并想要深入学习JVM话,可以去阅读它的源代码。(源代码主要由机器码、C/C++语言组成,源码大概50多万行)
源码下载地址: http://download.java.net/openjdk/jdk8/
以上是来是网络的学习资料总结。