Frida官方手册 - JavaScript API(篇二)
发布者:freakish
发布于:2017-10-24 14:31
JavaScript API
Int64
- new Int64(v): 以v为参数,创建一个Int64对象,v可以是一个数值,也可以是一个字符串形式的数值表示,也可以使用 Int64(v) 这种简单的方式。
- add(rhs), sub(rhs), and(rhs), or(rhs), xor(rhs): Int64相关的加减乘除。
- shr(n), shl(n): Int64相关的左移、右移操作
- compare(rhs): Int64的比较操作,有点类似 String.localCompare()
- toNumber(): 把Int64转换成一个实数
- toString([radix = 10]): 按照一定的数值进制把Int64转成字符串,默认是十进制
UInt64
- 可以直接参考Int64
NativePointer
- 可以直接参考Int64
NativeFunction
- new NativeFunction(address, returnType, argTypes[, abi]): 在address(使用NativePointer的格式)地址上创建一个NativeFunction对象来进行函数调用,returnType 指定函数返回类型,argTypes 指定函数的参数类型,如果不是系统默认类型,也可以选择性的指定 abi 参数,对于可变类型的函数,在固定参数之后使用 “…” 来表示。
类和结构体
- 在函数调用的过程中,类和结构体是按值传递的,传递的方式是使用一个数组来分别指定类和结构体的各个字段,理论上为了和需要的数组对应起来,这个数组是可以支持无限嵌套的,结构体和类构造完成之后,使用NativePointer的形式返回的,因此也可以传递给Interceptor.attach() 调用。
- 需要注意的点是, 传递的数组一定要和需要的参数结构体严格吻合,比如一个函数的参数是一个3个整形的结构体,那参数传递的时候一定要是 [‘int’, ‘int’, ‘int’],对于一个拥有虚函数的类来说,调用的时候,第一个参数一定是虚表指针。
Supported Types
- void
- pointer
- int
- uint
- long
- ulong
- char
- uchar
- float
- double
- int8
- uint8
- int16
- uint16
- int32
- uint32
- int64
- uint64
Supported ABIs
- default
- Windows 32-bit:
- sysv
- stdcall
- thiscall
- fastcall
- mscdecl
- Windows 64-bit:
- win64
- UNIX x86:
- sysv
- unix64
- UNIX ARM:
- sysv
- vfp
NativeCallback
- new NativeCallback(func, returnType, argTypes[, abi]): 使用JavaScript函数 func 来创建一个Native函数,其中returnType和argTypes分别指定函数的返回类型和参数类型数组。如果不想使用系统默认的 abi 类型,则可以指定 abi 这个参数。关于argTypes和abi类型,可以查看NativeFunction来了解详细信息,这个对象的返回类型也是NativePointer类型,因此可以作为 Interceptor.replace 的参数使用。
SystemFunction
- new SystemFunction(address, returnType, argTypes[, abi]): 功能基本和NativeFunction一致,但是使用这个对象可以获取到调用线程的last error状态,返回值是对平台相关的数值的一层封装,为value对象,比如是对这两个值的封装, errno(UNIX) 或者 lastError(Windows)。
Socket
SocketListener
SocketConnection
IOStream
InputStream
OutputStream
UnixInputStream
UnixOutputStream
Win32InputStream
Win32OutputStream
File
SqliteDatabase
SqliteStatement
Interceptor
- Interceptor.attach(target, callbacks): 在target指定的位置进行函数调用拦截,target是一个NativePointer参数,用来指定你想要拦截的函数的地址,有一点需要注意,在32位ARM机型上,ARM函数地址末位一定是0(2字节对齐),Thumb函数地址末位一定1(单字节对齐),如果使用的函数地址是用Frida API获取的话, 那么API内部会自动处理这个细节(比如:Module.findExportByName())。其中callbacks参数是一个对象,大致结构如下:
- onEnter: function(args): 被拦截函数调用之前回调,其中原始函数的参数使用args数组(NativePointer对象数组)来表示,可以在这里修改函数的调用参数。
- onLeave: function(retval): 被拦截函数调用之后回调,其中retval表示原始函数的返回值,retval是从NativePointer继承来的,是对原始返回值的一个封装,你可以使用retval.replace(1337)调用来修改返回值的内容。需要注意的一点是,retval对象只在 onLeave函数作用域范围内有效,因此如果你要保存这个对象以备后续使用的话,一定要使用深拷贝来保存对象,比如:ptr(retval.toString())。
- 事实上Frida可以在代码的任意位置进行拦截,但是这样一来 callbacks 回调的时候,因为回调位置有可能不在函数的开头,这样onEnter这样的回调参数Frida只能尽量的保证(比如拦截的位置前面的代码没有修改过传入的参数),不能像在函数头那样可以确保正确。
- 拦截器的attach调用返回一个监听对象,后续取消拦截的时候,可以作为 Interceptor.detach() 的参数使用。
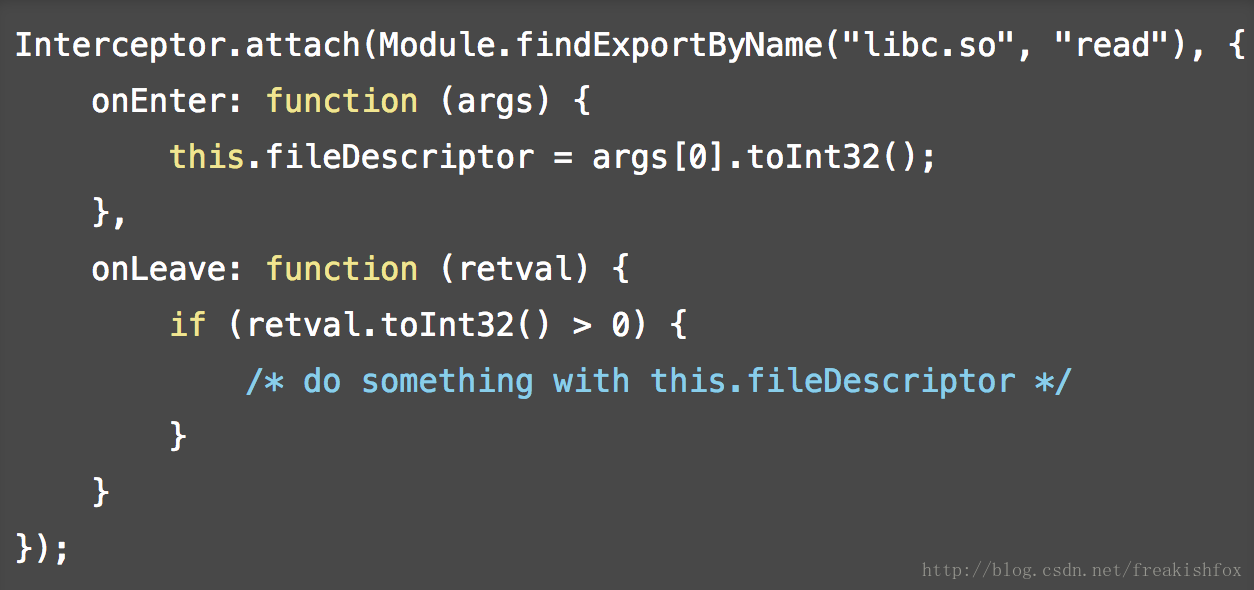
- 还有一个比较方便的地方,那就是在回调函数里面,包含了一个隐藏的 this 的线程tls对象,方便在回调函数中存储变量,比如可以在 onEnter 中保存值,然后在 onLeave 中使用,看一个例子:
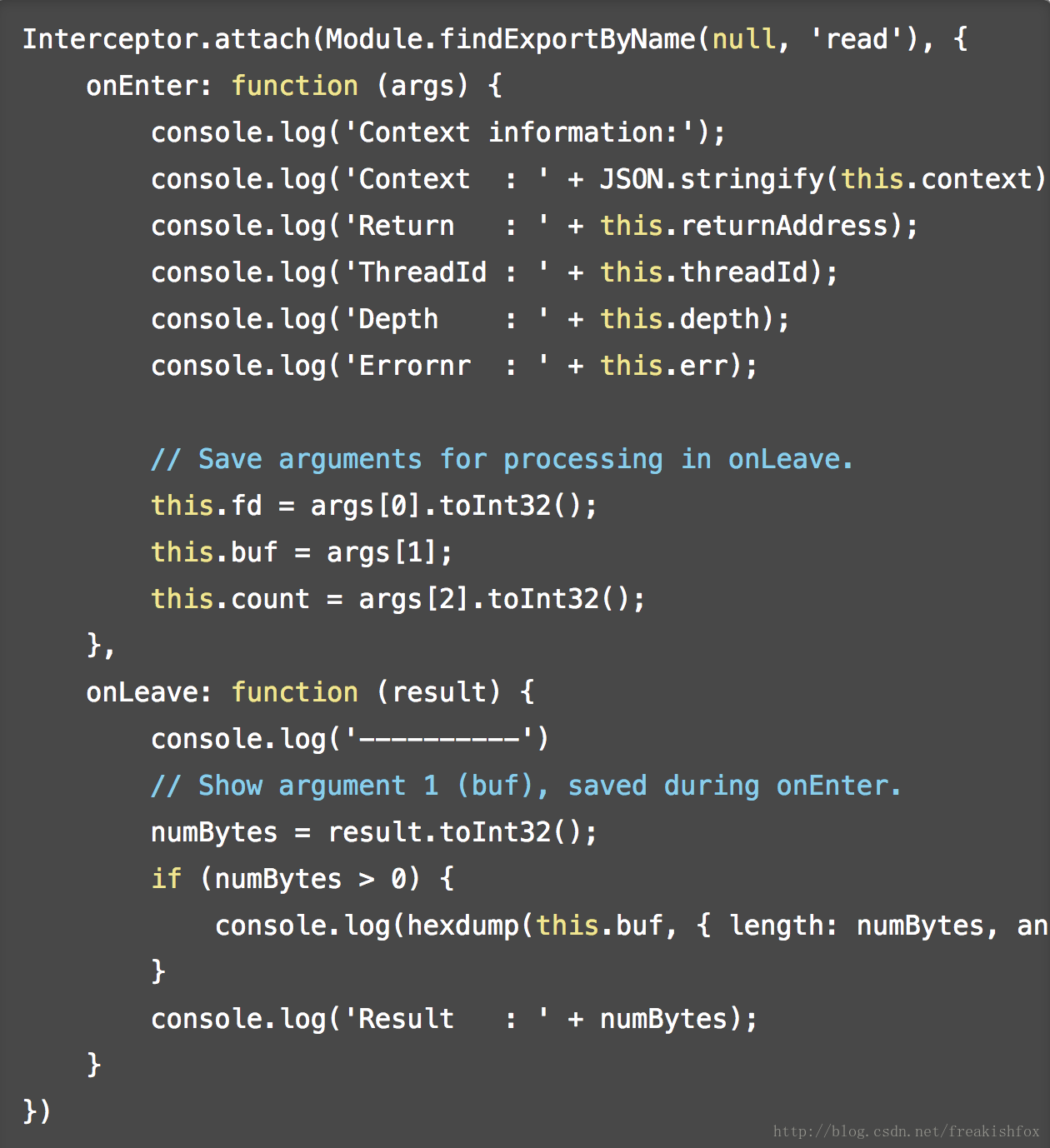
- 另外,this 对象还包含了一些额外的比较有用的属性:
- returnAddress: 返回NativePointer类型的 address 对象
- context: 包含 pc,sp,以及相关寄存器比如 eax, ebx等,可以在回调函数中直接修改
- errno: (UNIX)当前线程的错误值
- lastError: (Windows) 当前线程的错误值
- threadId: 操作系统线程Id
- depth: 函数调用层次深度
- 看个例子:

- Interceptor.detachAll(): 取消之前所有的拦截调用
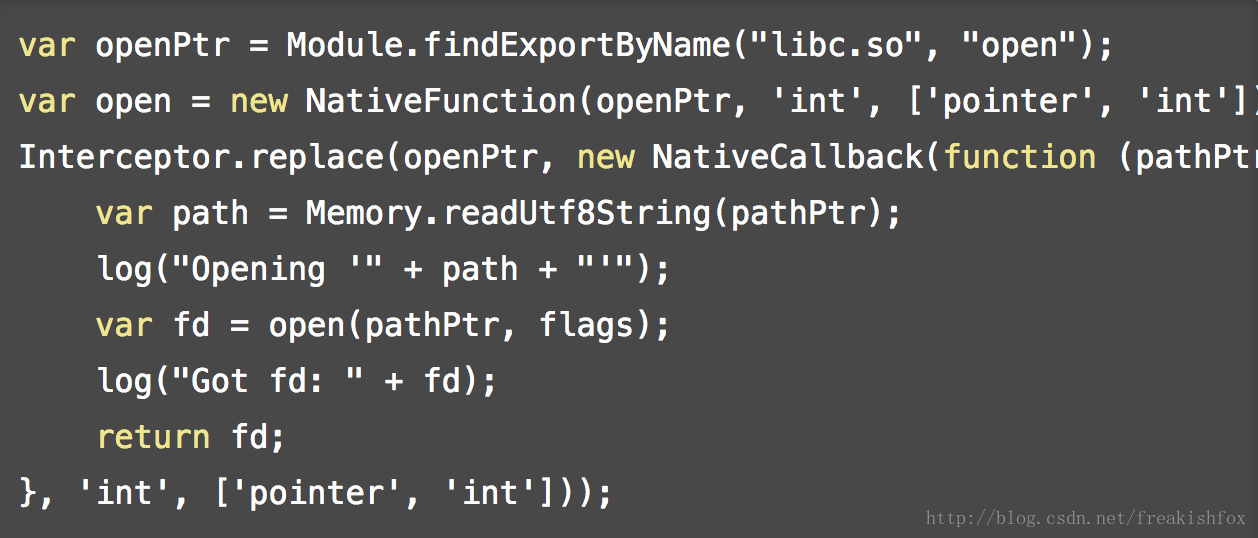
- Interceptor.replace(target, replacement): 函数实现代码替换,这种情况主要是你想要完全替换掉一个原有函数的实现的时候来使用,注意replacement参数使用JavaScript形式的一个NativeCallback来实现,后续如果想要取消这个替换效果,可以使用 Interceptor.revert调用来实现,如果你还想在你自己的替换函数里面继续调用原始的函数,可以使用以 target 为参数的NativeFunction对象来调用,来看一个例子:
- Interceptor.revert(target): 还原函数的原始实现逻辑,即取消前面的 Interceptor.replace调用
- Interceptor.flush(): 确保之前的内存修改操作都执行完毕,并切已经在内存中发生作用,只要少数几种情况需要这个调用,比如你刚执行了 attach() 或者 replace() 调用,然后接着想要使用NativeFunction对象对函数进行调用,这种情况就需要调用flush。正常情况下,缓存的调用操作会在当前线程即将离开JavaScript运行时环境或者调用send()的时候自动进行flush操作,也包括那些底层会调用 send() 操作的函数,比如 RPC 函数,或者任何的 console API
Stalker
- Stalker.follow([threadId, options]): 开始监视线程ID为 threadId(如果是本线程,可以省略)的线程事件,举个例子:


- Stalker.unfollow([threadId]): 停止监控线程事件,如果是当前线程,则可以省略 threadId 参数
- Stalker.parse(events[, options]): 按照指定格式介些 GumEvent二进制数据块,按照options的要求格式化输出,举个例子:

- Stalker.garbageCollect(): 在调用Stalker.unfollow()之后,在一个合适的时候,释放对应的内存,可以避免多线程竞态条件下的内存释放问题。
- Stalker.addCallProbe(address, callback): 当address地址处的函数被调用的时候,调用callback对象(对象类型和Interceptor.attach.onEnter一致),返回一个Id,可以给后面的Stalker.removeCallProbe使用
- Stalker.removeCallProbe(): 移除前面的 addCallProbe 调用效果。
- Stalker.trustThreshold: 指定一个整型x,表示可以确保一段代码在执行x次之后,代码才可以认为是可靠的稳定的, -1表示不信任,0表示持续信任,N表示执行N次之后才是可靠的,稳定的,默认值是1。
- Stalker.queueCapacity: 指定事件队列的长度,默认长度是16384
- Stalker.queueDrainInterval: 事件队列查询派发时间间隔,默认是250ms,也就是说1秒钟事件队列会轮询4次
ApiResolver
- new ApiResolver(type): 创建指定类型type的API查找器,可以根据函数名称快速定位到函数地址,根据当前进程环境不同,可用的ApiResolver类型也不同,到目前为止,可用的类型有:
- Module: 枚举当前进程中已经加载的动态链接库的导入导出函数名称。
- objc: 定位已经加载进来的Object-C类方法,在macOS和iOS进程中可用,可以使用 Objc.available 来进行运行时判断,或者在 try-catch 块中使用 new ApiResolver(‘objc’) 来尝试创建。
- 解析器在创建的时候,会加载最小的数据,后续使用懒加载的方式来持续加载剩余的数据,因此最好是一次相关的批量调用使用同一个resolver对象,然后下次的相关操作,重新创建一个resolver对象,避免使用上个resolver的老数据。
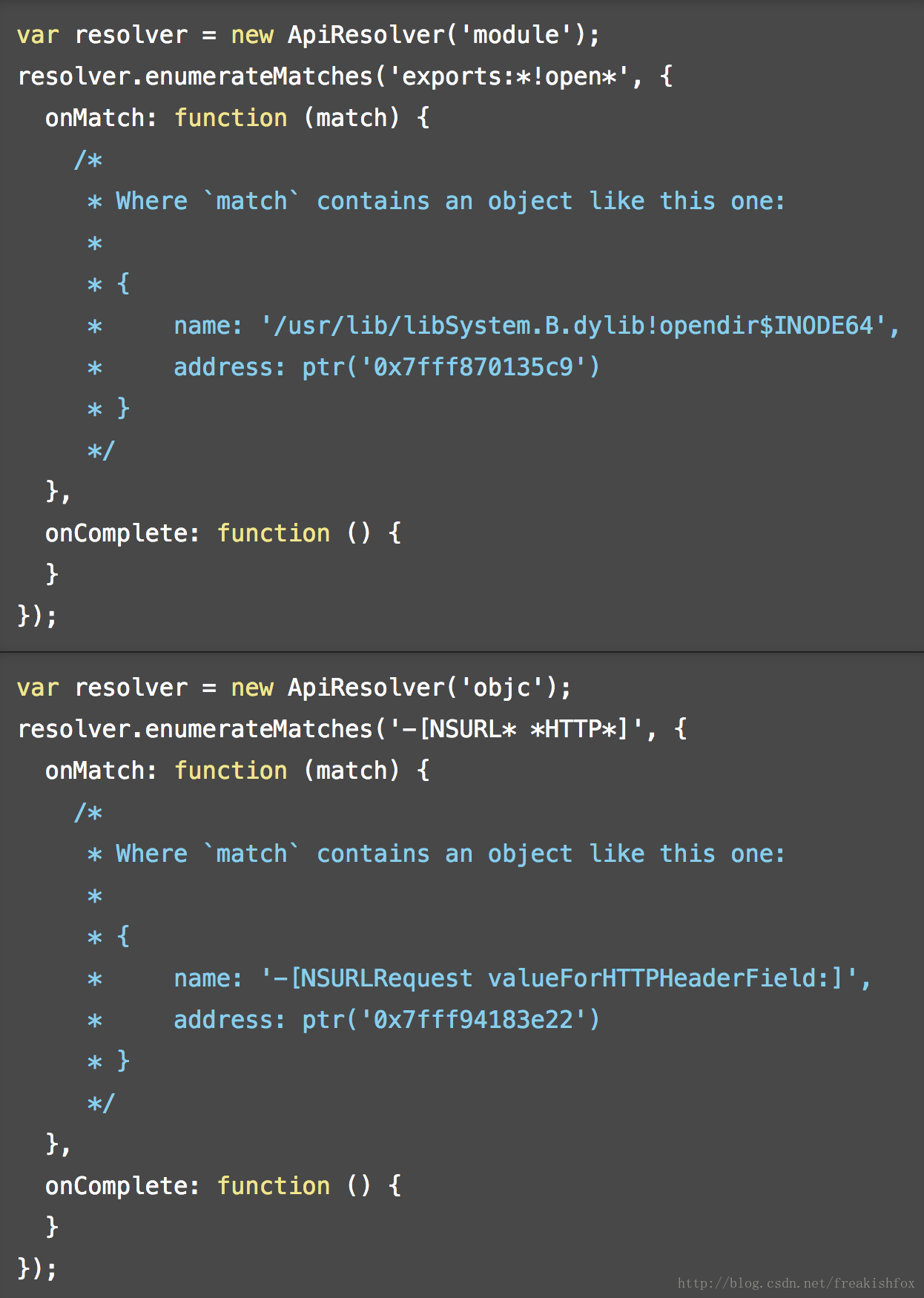
- enumerateMatches(query, callbacks): 执行函数查找过程,按照参数query来查找,查找结果调用callbacks来回调通知:
- onMatch: function(match): 每次枚举到一个函数,调用一次,回调参数match包含name和address两个属性。
- onComplete: function(): 整个枚举过程完成之后调用。
- 举个例子:
- enumerateMatchesSync(query): enumerateMatches()的同步版本,直接返回所有结果的数组形式
DebugSymbol
- DebugSymbol.fromAddress(address), DebugSymbol.fromName(name): 在指定地址或者指定名称查找符号信息,返回的符号信息对象包含下面的属性:
- address: 当前符号的地址,NativePointer
- name: 当前符号的名称,字符串形式
- moduleName: 符号所在的模块名称
- fileName: 符号所在的文件名
- lineNumber: 符号所在的文件内的行号
- 为了方便使用,也可以在这个对象上直接使用 toString() ,输出信息的时候比较有用,比如和 Thread.backtrace 配合使用,举个例子来看:
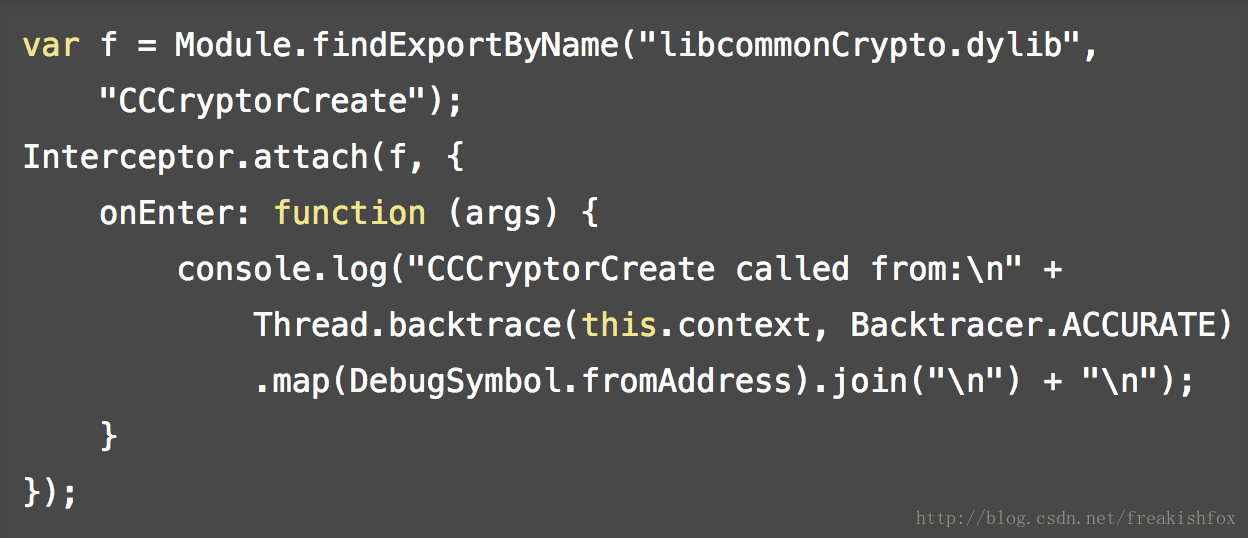
- DebugSymbol.getFunctionByName(name), DebugSymbol.findFunctionsNamed(name), DebugSymbol.findFunctionsMatching(glob): 这三个函数,都是根据符号信息来查找函数,结果返回 NativePointer 对象。
Instruction
- Instruction.parse(target): 在 target 指定的地址处解析指令,其中target是一个NativePointer。注意,在32位ARM上,ARM函数地址需要是2字节对齐的,Thumb函数地址是1字节对齐的,如果你是使用Frida本身的函数来获取的target地址,Frida会自动处理掉这个细节,parse函数返回的对象包含如下属性:
- address: 当前指令的EIP,NativePointer类型
- next: 下条指令的地址,可以继续使用parse函数
- size: 当前指令大小
- mnemonic: 指令助记符
- opStr: 字符串格式显示操作数
- operands: 操作数数组,每个操作数对象包含type和value两个属性,根据平台不同,有可能还包含一些额外属性
- regsRead: 这条指令显式进行读取的寄存器数组
- regsWritten: 这条指令显式的写入的寄存器数组
- groups: 该条指令所属的指令分组
- toString(): 把指令格式化成一条人比较容易读懂的字符串形式
- 关于operands和groups的细节,请参考CapStone文档
ObjC
Java
- Java.available: 布尔型取值,表示当前进程中是否存在完整可用的Java虚拟机环境,Dalvik或者Art,建议在使用Java方法之前,使用这个变量来确保环境正常。
- Java.enumerateLoadedClasses(callbacks): 枚举当前进程中已经加载的类,每次枚举到加载的类回调callbacks:
- onMatch: function(className): 枚举到一个类,以类名称进行回调,这个类名称后续可以作为 Java.use() 的参数来获取该类的一个引用对象。
- onComplete: function(): 所有的类枚举完毕之后调用
- Java.enumerateLoadedClassesSync(): 同步枚举所有已经加载的类
- Java.use(fn): 把当前线程附加到Java VM环境中去,并且执行Java函数fn(如果已经在Java函数的回调中,则不需要再附加到VM),举个例子:
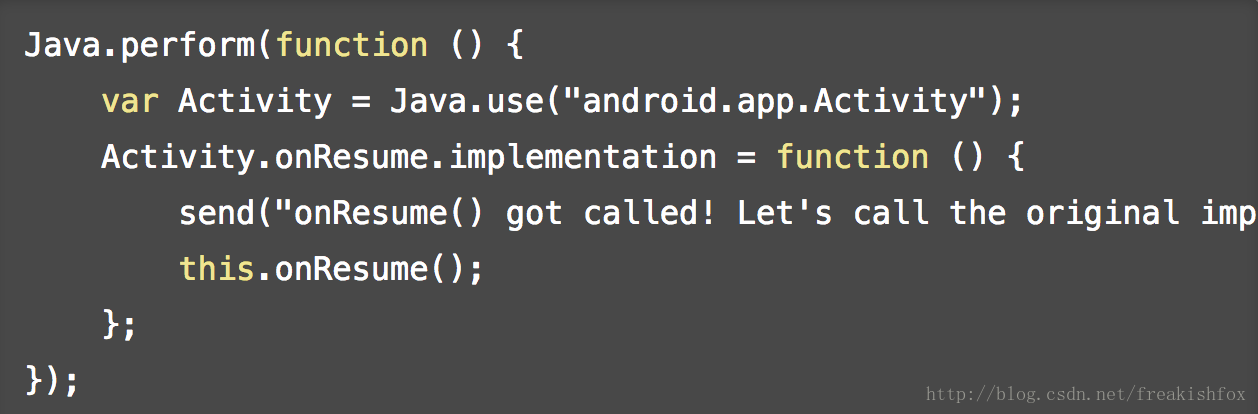
- Java.use(className): 对指定的类名动态的获取这个类的JavaScript引用,后续可以使用$new()来调用类的构造函数进行类对象的创建,后续可以主动调用 $dispose() 来调用类的析构函数来进行对象清理(或者等待Java的垃圾回收,再或者是JavaScript脚本卸载的时候),静态和非静态成员函数在JavaScript脚本里面也都是可见的, 你可以替换Java类中的方法,甚至可以在里面抛出异常,比如:
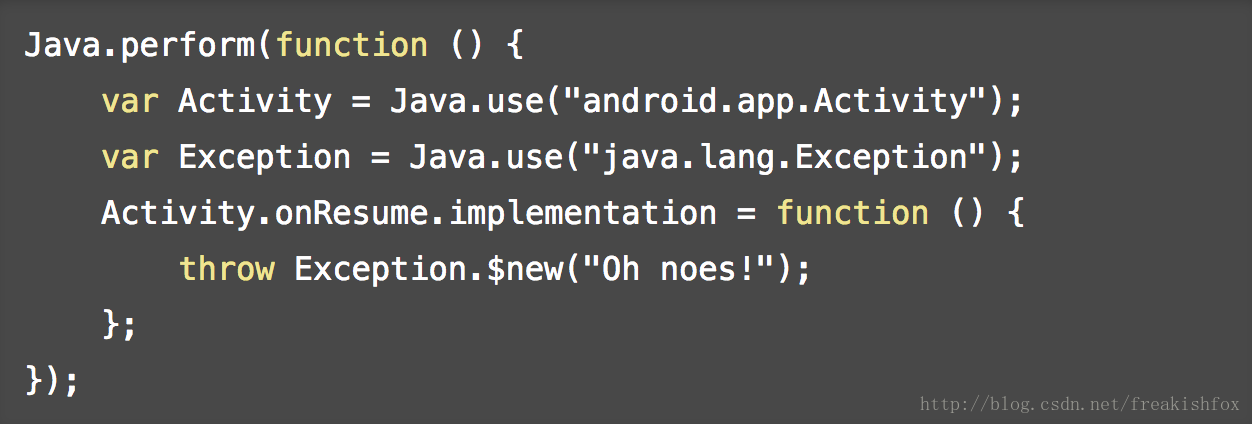
- Java.scheduleOnMainThread(fn): 在虚拟机主线程上执行函数fn
- Java.choose(className, callbacks): 在Java的内存堆上扫描指定类名称的Java对象,每次扫描到一个对象,则回调callbacks:
- onMatch: function(instance): 每次扫描到一个实例对象,调用一次,函数返回stop结束扫描的过程
- onComplete: function(): 当所有的对象都扫描完毕之后进行回调
- Java.cast(handle, klass): 使用对象句柄handle按照klass(Java.use方法返回)的类型创建一个对象的JavaScript引用,这个对象引用包含一个class属性来获取当前对象的类,也包含一个$className属性来获取类名称字符串,比如:

单篇儿太长,下篇继续
声明:该文观点仅代表作者本人,转载请注明来自看雪