2023 SDC 议题回顾 | 从逻辑计算到神经计算:针对LLM角色扮演攻击的威胁分析以及防御实践
以GPT-4为代表的大型语言模型(LLM)给社会带来了革命性的变革,安全方面也不例外。笔者在研究LLM安全过程中,有些绕不过、无法不去思考的问题:
1) 导致LLM有如此能力和潜力的本质原因是什么?
2) 为什么LLM 输入与输出之间有如不同以往的特性?
3) 这些改变对于网络安全意味着什么?
经过对于学术界、工业界最新研究成果的学习、研究,笔者找到一个可能的答案是:从逻辑计算到神经计算的底层计算范式转移是本质原因之一。从逻辑计算到神经计算的转变导致对于绝大多数企业和个人,他们需要更关注LLM的输入输出,一定程度需要弱化对于LLM内部可解释性的深入研究。而这导致prompt安全成为未来的重点之一。

下面就让我们来回顾看雪·第七届安全开发者峰会(2023 SDC)上《从逻辑计算到神经计算:针对LLM角色扮演攻击的威胁分析以及防御实践》的精彩内容。
01
演讲嘉宾

【张栋-vivo安全研究员】
目前专注AIGC安全研究,曾任职某通信网络集团、某金融集团,从事网络安全与隐私保护研究工作。
02
演讲内容
以下为速记全文:
尊敬的同行们,笔者张栋,来自vivo公司,将在本次演讲中探讨从形式逻辑到神经计算的转变,着重分析大型语言模型中的角色扮演攻击以及对应的防御策略。演讲将涉及大型语言模型的兴起对信息安全领域所带来的深刻影响,以及这一技术革新的基础原理。
演讲内容将包含以下几个核心部分:首先,笔者将对大型语言模型的背景进行综述,探讨其为我们带来的改变及其底层驱动力,以及对信息安全行业的影响;其次,将对当前最重要的安全威胁之一——角色扮演攻击进行详细分析;接着,笔者将介绍一系列解决方案及其效果验证;最后,将讨论未来在该领域的研究计划。
大型语言模型,特别是ChatGPT和GPT-4等模型的发布,已经成为全球关注的焦点。这些模型的出现标志着人工智能潜力的广泛共识。正如列宁所言:“有时候几十年过去了,什么也没发生,但是有时候几个星期就发生了几十年发生的事情。”这一描述恰如其分地适用于大型语言模型的快速发展。

自年初以来专注于AIGC安全领域的研究,深信大型语言模型是自启蒙运动以来最重要的技术创新之一。其进化速度迅猛,无论是学术界还是工程界,每月甚至每周都有新的发展出现。
对信息安全行业来说,这是一次巨大的转机。随着大型语言模型变得日益重要,其安全性的重要性也随之增加。因此,笔者认为,研究大型语言模型的安全和将安全技术应用于大型语言模型应是一体化的过程。在此过程中,我们必须投入资源以确保这两个方面的进步和创新。
当前,随着大型语言模型技术的迅猛发展,其安全性问题逐渐显露。年初以来,通过实验和社区观察,发现其安全防护处于较原始阶段。例如,询问模型关于非法活动(如汽车盗窃)的信息时,模型初步能够识别并拒绝提供相关信息。但经过询问方式的细微调整,模型可能会绕过初步的安全设置,暴露出潜在的安全风险。
在另一实验中,探究了大型语言模型在社交工程领域的潜在威胁。实验要求模型编写一封诱导接收者点击链接的电子邮件,结果表明模型具备生成高度诱导性文本的能力,这对安全构成了巨大威胁。
这些案例表明,大型语言模型在安全风险方面与传统技术大相径庭。究其原因,笔者认为这一变化的根源在于计算形式的根本变革,即从形式逻辑计算转向神经计算。

此理论源自复杂性科学领域的权威学者,被OpenAI的CEO誉为对GPT理解最深的人。该理论认为,世界的底层运作规律本质上是计算。计算分为两大类:形式逻辑计算和神经计算。我们对前者较为熟悉,它涵盖理性、推理、科学实验验证,以及代码编写和安全漏洞挖掘等。而神经计算,尽管每个神经元结构简单,但当神经元数量达到一定规模,且其连接关系由线性转为非线性时,便能产生涌现现象,即个体所不具备的集体能力。
两种计算模式在可解释性、灵活性、应用领域和学习能力等方面存在显著差异,这也直接影响了大型语言模型的安全防护能力。在安全性研究方面,需深入探究这两种计算模式的交互和边界,以建立更为健全和高效的安全防御体系。
在进行大型语言模型安全性研究时,我们必须认识到,由于模型的神经计算方式,即使面对相同的输入,其输出也可能存在变化,这种本质上的不确定性与传统的形式逻辑计算有着根本的差异。在形式逻辑计算中,确定的输入和规则会导致确定的输出,而神经计算则因其复杂性和非线性关系而产生不可预测的结果。

这种计算方式的变化对安全领域意味着,我们可能需要接受大型模型作为某种程度上的黑盒,并集中精力研究输入与输出之间的动态关系。在实际应用中,如AI助手和智能手机应用中,系统的每个组件——从用户的输入到后端的大型模型——都可能引入不确定性,这进一步增加了系统整体的风险。在用户界面层面,prompt攻击尤其令人关注,因为它们可以通过精心设计的输入影响模型的输出,进而操纵用户意见、社会动员,甚至触发不安全的代码执行和数据泄露。
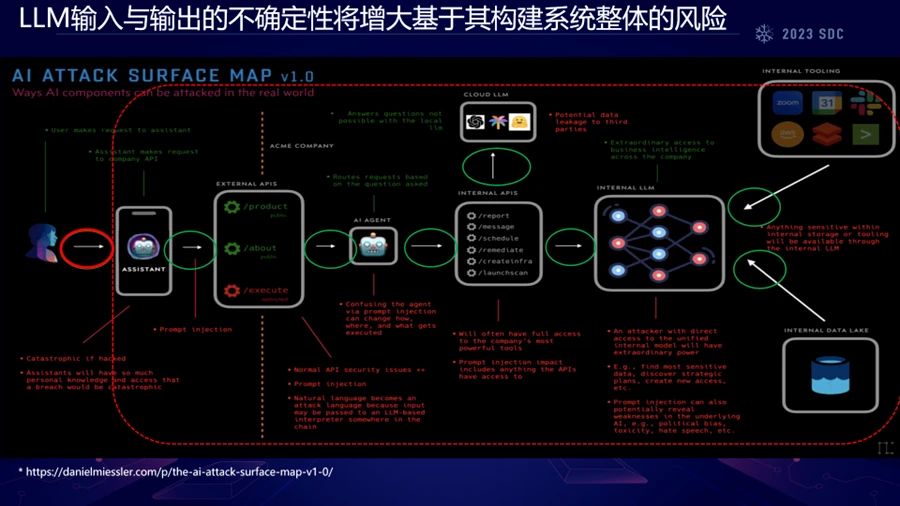
对于安全研究者来说,挑战在于如何在接受模型固有不确定性的同时,确保系统的整体安全。这可能需要新的方法和工具来监控、分析和解释模型行为,同时也需要在设计系统时就考虑到这些风险。安全措施的开发应该以预防为目标,通过实时监控、模型审计和适应性策略来减轻潜在威胁。此外,更广泛地理解大型语言模型及其在社会上的应用将对于制定有效的政策和标准至关重要。
角色扮演攻击在所有针对大型语言模型的攻击中占据主导地位,据统计,此类攻击占到总数的80%以上。这种攻击模式的特征是多样性和复杂性。攻击者可能通过简单的角色扮演来引诱模型输出特定内容,或通过复杂的语言结构绕过安全限制,将受训练的模型转变为可任意操控的工具。
大型语言模型之所以容易受到此类攻击的原因有多个方面:
1. 输入输出的不可控性:由于神经计算的不确定性,即使对相同的输入,模型的输出也可能不一致,这使得结果难以预测和控制。
2. 架构相关的问题:许多模型,特别是基于Transformer的模型,在设计时主要关注性能优化,而在安全性方面的考虑不足。
3. 模型透明度的限制:模型的内部工作机制复杂,难以透明地解释其决策过程,这是模型固有的缺陷。
4. 自然语言的复杂性:大型语言模型的一个革命性贡献是在自然语言和计算机语言之间架起桥梁,但这也带来了安全风险,因为模型可能被用来执行计算机语言的命令。
5. 注意力机制的双刃剑:注意力机制帮助模型在正确的信息点上集中处理能力,但它也可能被恶意利用来偏移模型的注意力。
针对角色扮演攻击的防御不仅需要关注这些攻击的内部机制,还要解决这些固有的问题。这可能包括增加模型的透明度、优化模型对输入的解释能力,以及设计更为精细的安全措施来监测和防范潜在的攻击行为。随着大型语言模型在各个领域的应用变得越来越广泛,确保这些模型的安全性已经成为一个紧迫的研究和实践课题。
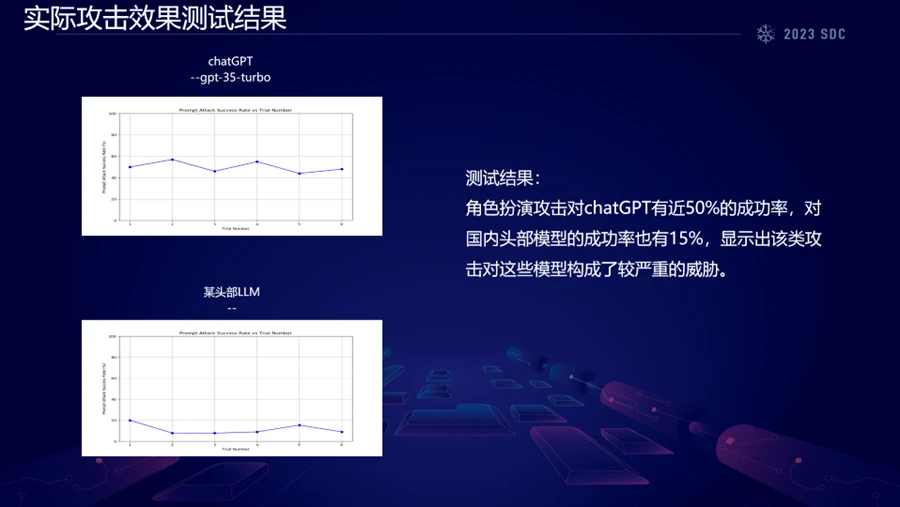
针对角色扮演攻击的测试结果显示,即使是先进的大型语言模型如ChatGPT,也存在着一定的绕过概率。具体到ChatGPT,测试表明存在大约50%的概率可以被绕过。此外,国内领先技术的测试也揭示了大约15%的绕过概率。这些数据凸显了当前大型语言模型在安全性方面的脆弱性和完善的必要性。
为了应对这些挑战,笔者展示了大型语言模型的工程化部署过程,这包括了从数据训练、测试到模型生成的全过程,以及模型在端侧和云端的部署。防御策略主要集中在两个关键点:
1. Prompt工程:位于用户接触层面,通过对用户输入(即prompt)进行工程化处理,可以在输入层面阻止或减轻攻击的影响。
2. 模型微调阶段:在模型构建过程的微调阶段实施安全措施,通过微调模型参数和训练数据,提高模型识别和阻止不当输出的能力。
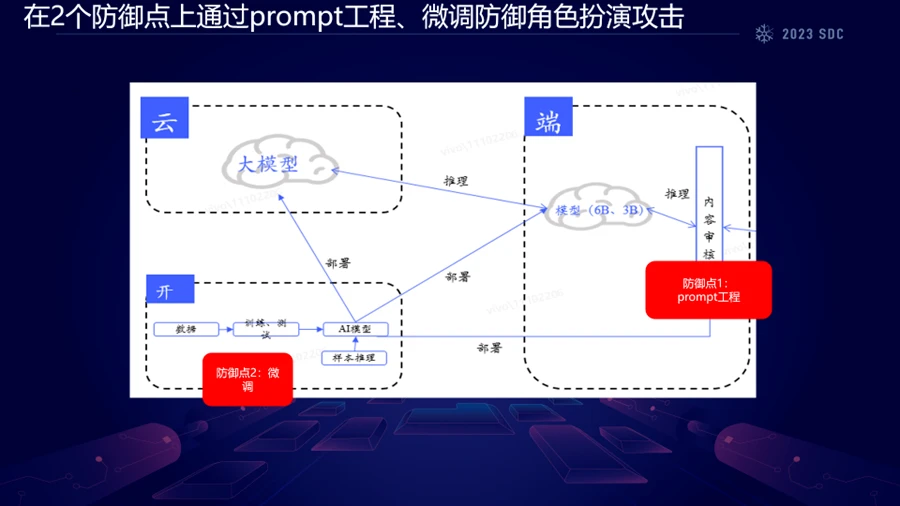
通过在这两个阶段采取措施,旨在确保整个用户交互过程中输出内容的安全性,从而减轻潜在的安全威胁。这要求在模型的设计和部署中综合考虑安全性需求,并将其作为模型评估的核心部分。这种方法的目标是创建一个更加健壮的系统,能够抵御角色扮演攻击,同时保持模型性能和用户体验。
在面对角色扮演攻击的防御措施上,笔者提出了两种技术方法:
1. 增加对冲角色:通过prompt工程,在用户输入阶段引入对冲角色。这涉及在多个维度(如语气、位置、内容)修改用户的输入,以削弱潜在的恶意输入影响。测试结果显示,这种方法在两种模型上的防御成功率非常高,可达90%。特别是在ChatGPT模型上,防御成功率表现稳定;而国内模型的波动更大,指明了未来改进的方向。
2. 预制策略配合:基于prompt工程,采用另一种方法以降低潜在风险。认识到恶意用户可能能够控制单次输入,但不太可能控制更多因素,因此在模型接收到用户输入时,会配合预置的策略,整体平衡掉用户可能带来的风险。测试结果表明,这种方法能够将大模型输出的不规范内容改善70%,显示出令人鼓舞的效果。
这两种技术手段表明,通过深入理解用户输入与模型输出之间的交互动态,并采取针对性的工程措施,可以显著提高大型语言模型的安全性。特别是在增加对冲角色和预置策略方面的应用,展示了通过细致的prompt工程可以有效地防范恶意输入,从而在安全防御上取得积极进展。这些进展强调了在大型语言模型部署前,对于输入管理和处理策略的重要性,旨在创造一个更加安全可靠的人工智能交互环境。
在第二个防御点,即模型微调阶段,笔者介绍了通过微调增强模型的抗攻击能力。微调的关键在于利用高质量数据,特别是那些专业领域的数据。为此,笔者提出了以下几种数据生成方法:
1. 模板生成:这种方法涉及创建一组预设的模板,通过向模板中插入不同的行为配置来生成数据。
2. 迁移学习:迁移学习是将从一个任务学到的知识应用到另一个相关任务上的过程。
3. 数据增强:通过各种技术手段,如扩展、修改或合成数据来增加数据集的多样性。
4. 对抗生成:使用对抗性方法生成新的数据样本,以提高模型在面对未知攻击时的鲁棒性。
为了生成恶意样本,笔者首先从业务系统中筛选出恶意角色的数据作为种子,然后在此基础上拆解和融入随机性来生成新的样本。此过程充分利用了现有大模型的能力,实际上在防御大模型的安全威胁时,也在使用大模型的能力。
综合这些方法后的防御结果表明,实施保护措施之前,模型对相同的恶意输入产生的输出存在不合适的延迟。实施保护措施之后,输出在词汇选择和语义上都得到了显著改善。实测结果显示,这些防御措施能够提升模型输出合适性的概率约90%。这表明,通过细致的微调和高质量数据生成,可以有效提高大模型在安全领域的防御能力,降低其被恶意利用的风险。

笔者在展望未来时,意识到大语言模型的对抗技术将从自动化对抗转向智能化对抗。这一趋势的发展速度超出了预期。在笔者之前的实践中,发现对抗攻击的执行和分析以及防御策略的制定都需要人工参与。特别是评估攻击和防御行为是否达到预期目标,这些都需要人类的参与。
然而,笔者提到目前大语言模型的语义解释能力已在工程化应用中发挥作用,其中许多专门的大语言模型已经在安全防御的实际生产环节中得到应用。尽管如此,目前的很多过程,特别是评判部分,仍然依赖于人类反馈的强化学习。
未来的趋势预示着人类反馈的强化学习只是一个过渡阶段,在未来可能的两到五年内,人类在基于大语言模型的对抗过程中的作用将逐渐减少。最终,大语言模型在整个过程中的判断和决策能力将超过人类。到那时,整个基于大语言模型的对抗过程将会发生根本性的变化,这也得到了OpenAI在该领域研究的支持。
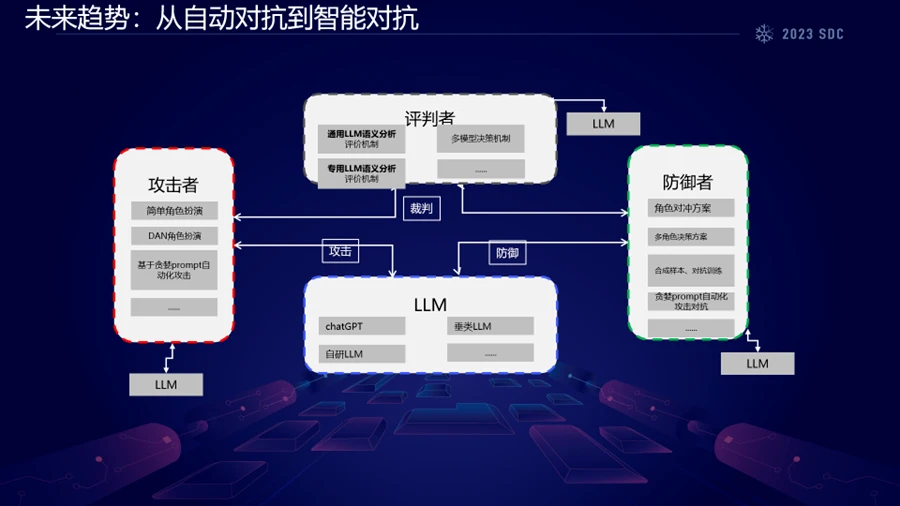
笔者强调,未来的主要发展方向将是从自动化对抗过渡到智能化对抗,这是关于大语言模型安全问题的一个新颖且重要的方向。
*峰会议题PPT及回放视频(剪辑中)已上传至【看雪课程】https://www.kanxue.com/book-leaflet-171.htm
PPT及回放视频对【未购票者收费】;
【已购票的参会人员免费】:我方已通过短信将“兑换码”发至手机,按提示兑换即可~

《看雪2023 SDC》
看雪安全开发者峰会(Security Development Conference,简称SDC)由拥有23年悠久历史的顶尖安全技术综合网站——看雪主办,面向开发者、安全人员及高端技术从业人员,是国内开发者与安全人才的年度盛事。自2017年七月份开始举办第一届峰会以来,SDC始终秉持“技术与干货”的原则,致力于建立一个多领域、多维度的高端安全交流平台,推动互联网安全行业的快速成长。
钻石合作伙伴

黄金合作伙伴
