Linux内核-虚拟文件系统(VFS)
1. 文件路径
对于路径"/dir1/dir2/x3",包含了4个文件,其中"/"、"dir1/"、"dir2/"一定为目录(目录本质上也是文件,只不过和.doc、.txt等普通文件相比,它专门存储子目录或文件的信息,而不是存储最终的用户数据),”x3”可能为目录,也可能为普通文件。
存于硬盘时,每个目录和普通文件,都对应一个ext2_dir_entry_2和ext2_inode结构(对于ext2文件系统),加载到内存时,每个文件又会对应一个dentry和inode结构。暂且需要知道的是,dentry结构包含"文件名",inode结构包含"文件内容的位置信息",同一个文件的信息,使用2个结构描述,是因为同一个文件,可能会有多个文件名(比如链接文件),这些文件名,共用一份"文件内容的位置信息"即可,这样既可以节省空间,又避免了"位置信息"修改后,必须同步到多个结构中的问题。
1.1. dentry & inode
对于"/dir1/dir2/x3"路径中的"dir2"目录,它的文件名仅仅是"dir2",而不是"/dir1/dir2",通过"/dir1/dir2"能找到它,只是因为"dir2"的dentry,包含在"dir1"的文件内容中。
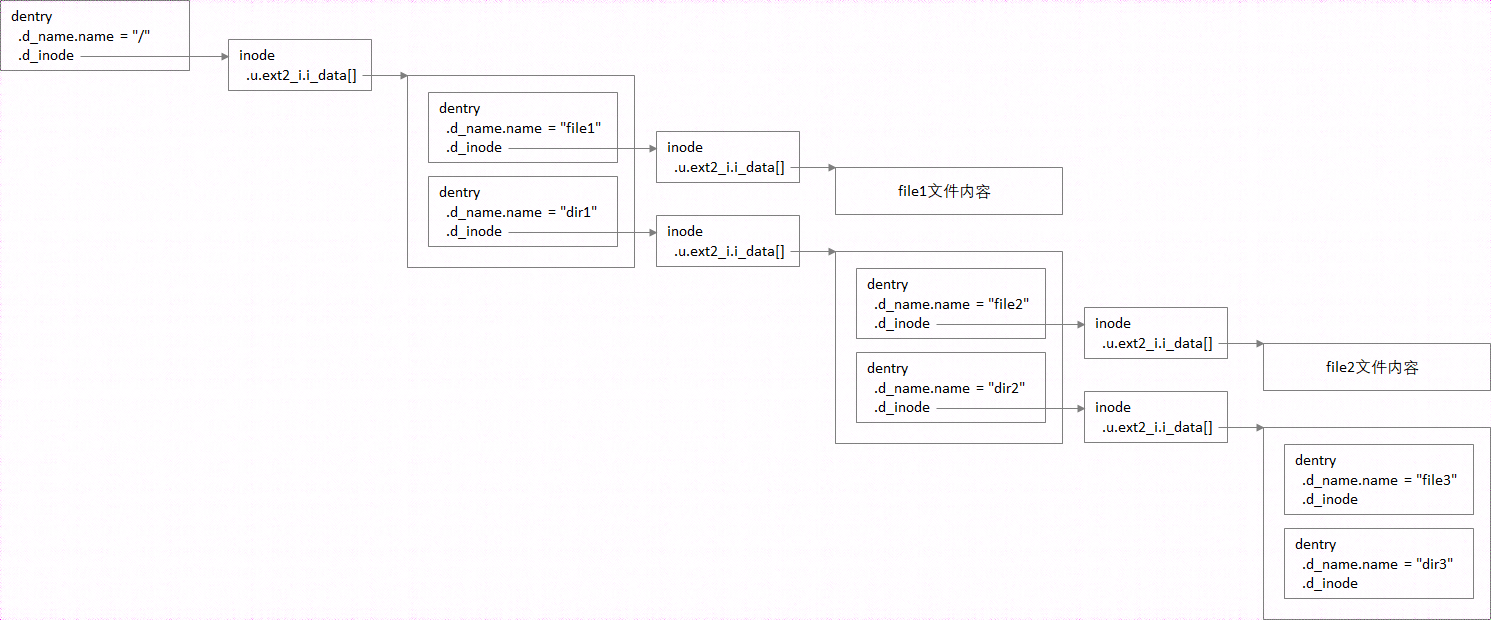
假设目录结构如下:

加载到内存后,创建的dentry和inode,以及相互关系为:
1.2. 硬盘 & 分区
1.2.1. 硬盘类型
机械硬盘:Hard Disk Drive (HDD)
固态硬盘:Solid State Drive (SSD)
1.2.2. 硬盘接口类型
SCSI接口:除了硬盘,还可以接其它设备;
SATA & PATA接口:专门用于接硬盘,Serial-ATA (串行),Parallel-ATA (并行);
PCIe接口:除了硬盘,还可以接网卡显卡等,会使设备更接近CPU;
IDE接口:=PATA接口。
1.2.3. 系统中的硬盘、分区名称
硬盘和接口,没有固定的对应关系,同一种硬盘,一般可以通过多种接口接入系统,同一种接口,一般也可以接多种硬盘。系统中的硬盘名称(可以通过fdisk命令查看),依据的是接口类型,比如通过SATA接口接入的硬盘,名称为"sdX",通过IDE接口接入的硬盘,名称为"hdX",其中,X表示当前硬盘为系统中同种类型的第几块,比如第1块IDE硬盘为"hda"、第2块IDE硬盘为"hdb"。
一块物理硬盘,又可以分为多个分区,相当于逻辑上,将一块硬盘,分为多块硬盘,对于"hda"硬盘来说,"hdaX"就是它的第X个分区,不过最多只可以分3个主分区,如果希望分更多的分区,就需要先分一个扩展分区"hda4",再在扩展分区里面继续分。

1.3. ext2硬盘逻辑划分
下图可以更加精细的展示,ext2文件系统对磁盘的逻辑划分:除了整个硬盘包含一个主引导记录块(MBR),以及每个分区各包含一个引导块之外,ext2又将分区进一步划分成了多个记录块组,每个块组中又包含超级块、块组描述符表、块使用位图、inode使用位图、inode记录块区、用户数据记录块区。
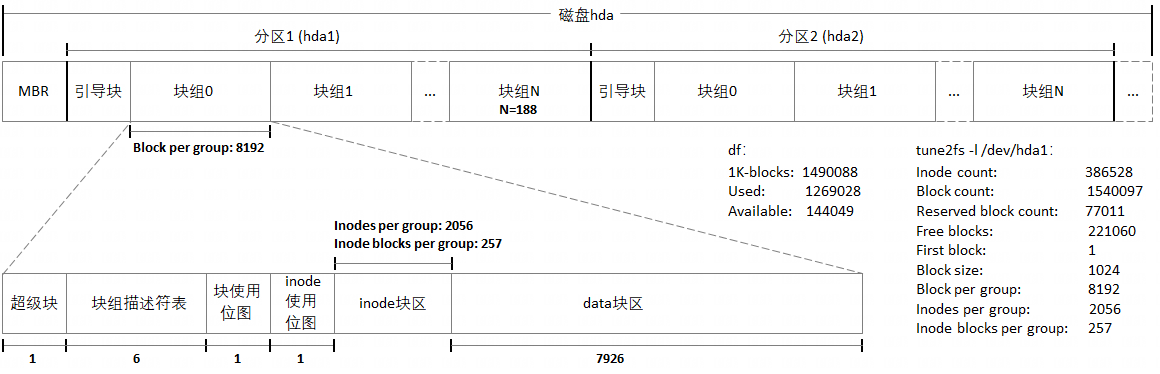
以下通过tune2fs和df命令的结果,加以佐证: Block count(hda1分区记录块总量) = 1540097 Block per group(每个块组中的记录块数量)= 8192 推导:1540097 / 8192 = 188 ... 1 hda1分区中的块组数量=188(多余1个记录块,作为hda1分区的引导块) Inode count(hda1分区inode总量)= 386528 Inodes per group(每个块组中的inode数量)= 2056 推导:386528 / 2056 = 188 同样得出,hda1分区中的块组数量 = 188 Inodes per group(每个块组中的inode数量)= 2056 记录块大小 = 1K (df命令显示"1K-blocks") inode结构大小 = 128(根据inode结构体定义) 2056 推导:--------- = 257 1K / 128 Inode blocks per group(每个块组中用于存储inode的记录块数量)= 257(与tune2fs命令结果吻合) Block count(hda1分区记录块总量)= 1540097,其中5%(经验值)用于保留记录块 推导:1540097 * 5% = 77011 Reserved block count(hda1分区中的保留记录块数量)= 77011(与tune2fs命令结果吻合) hda1分区中的块组数量=188 记录块大小 = 1K (df命令显示"1K-blocks") ext2_group_desc结构大小 = 128(根据ext2_group_desc结构体定义) 188 推导A:-------- = 6 1K / 32 每个块组中用于存储ext2_group_desc的记录块数量 = 6 推导B:8192-1-6-1-1-257 = 7926 每个块组中用于存储文件内容的记录块数量 = 7926 推导C:7926 * 188 = 1490088 1K-blocks(hda1分区中用于存储文件内容的记录块总量)= 1490088(与df命令结果吻合) Used(hda1分区中已用记录块数量)= 1269028 推导A:1490088 - 1269028 = 221060 Free blocks(hda1分区中空闲记录块数量(包含保留记录块))= 221060(与tune2fs命令结果吻合) 推导B:221060 - 77011 = 144049 Available(hda1分区中空闲记录块数量(不包含保留记录块))= 144049(与df命令结果吻合)
1.4. path_walk()
path_walk()函数,本质上是根据硬盘中存储的ext2_dir_entry_2和ext2_inode(对于ext2文件系统),在内存中,建立路径中各个节点的dentry和inode。基于以上对dentry和inode,以及ext2硬盘逻辑划分的理解,整个函数的主体不难看懂,只不过在具体过程中,要考虑链接文件和挂载设备的情况,其中,链接文件的原理比较简单,挂载设备会在之后一节详述。

插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

通过path_walk()函数可以看出,ext2_dir_entry_2结构的大小是可变的,这也是ext2硬盘逻辑划分中,为什么只有inode块区,而没有dentry块区的原因。
2. 设备挂载、卸载
2.1. 概念理解
2.1.1. 实例
iso挂载

"-t iso9660"参数,表示挂载设备为光盘格式,另外,挂载操作针对的是设备,因此iso文件不能直接挂载,要通过回接设备挂载,所以加了"-o loop"参数。其实,Linux系统可以自动识别iso格式,所以这2个参数都可以不显式添加 。
通过iso的挂载就可以看出,挂载就类似于"解压缩",挂载前,只能看到挂载设备本身,看不到它内部包含的目录/文件,而挂载后,挂载目录就与挂载设备中的根目录等价了,访问挂载目录,即为访问挂载设备内部的根目录。所以推测,挂载概念的设计意图,就是将一个设备挂载到哪,以及如何挂载,优先留给用户决定。
光盘挂载

虽然挂载失败(由于光驱中没有放光盘),但是已经可以表明挂载方法。
2.1.2. 原始设备 & 挂载点
当某个物理设备连到主机后,系统/dev目录下会多出一个文件,代表原始设备,Linux默认将其视为字符设备,而对这个设备的最终解释(包括挂载位置、文件格式),由用户通过mount参数指明,比如挂载一块硬盘后,再访问挂载点,就会进入挂载设备内部的根目录,按"块"为单位,访问硬盘内部的文件系统。
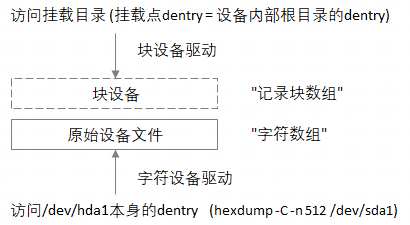
以下系统,对根目录做过扩容,可以理解为,将sda硬盘的sda2分区和sdb硬盘的sda1分区,合并为一个/dev/mapper/centos-root分区,然后挂载到了系统的根目录。
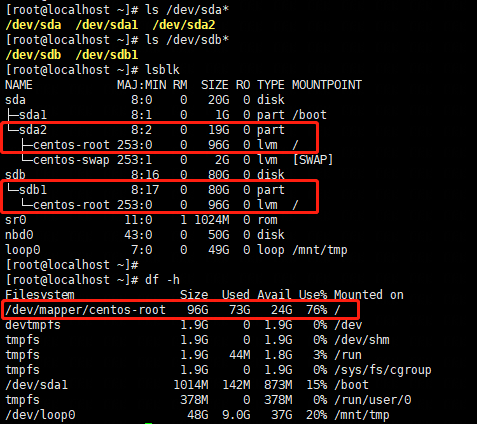
硬盘、分区的原始设备,作为字符设备被访问:
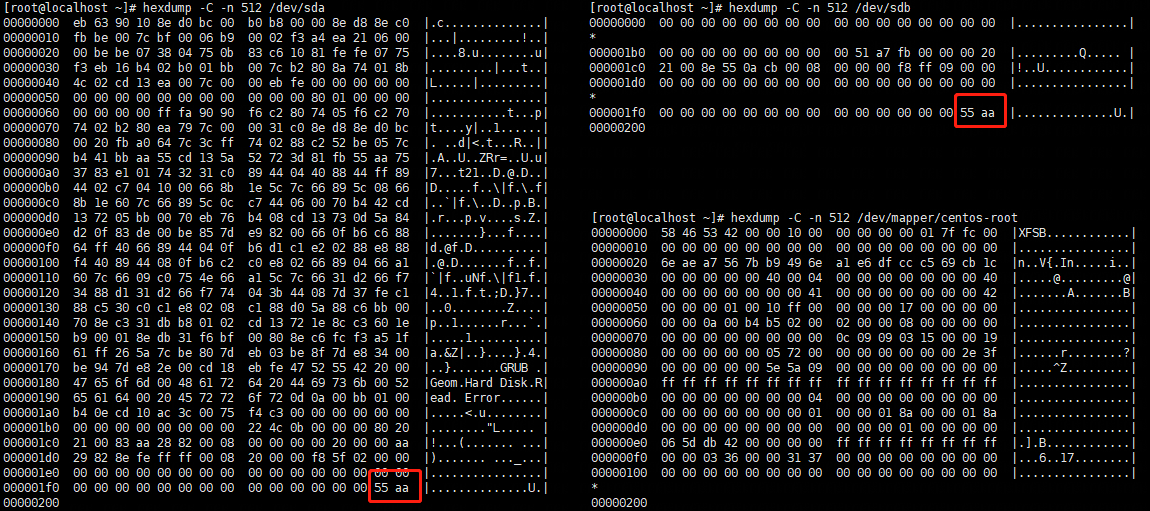
分区内部的根目录(挂载后与系统根目录等价),作为块设备被访问:

提到mount命令和系统根目录,需要了解一下,内核中共有3个挂载函数:
(1) sys_mount():该函数由mount命令,通过系统调用,进入内核态执行;
(2) mount_root():在系统启动时,由内核执行,挂载系统根目录;
(3) kem_mount():挂载对象同sys_mount(),不能挂载系统根目录,区别是,kem_mount()只由内核本身调用执行,而不是从用户态通过系统调用进入内核执行。
2.2. 同一挂载点挂载多个设备
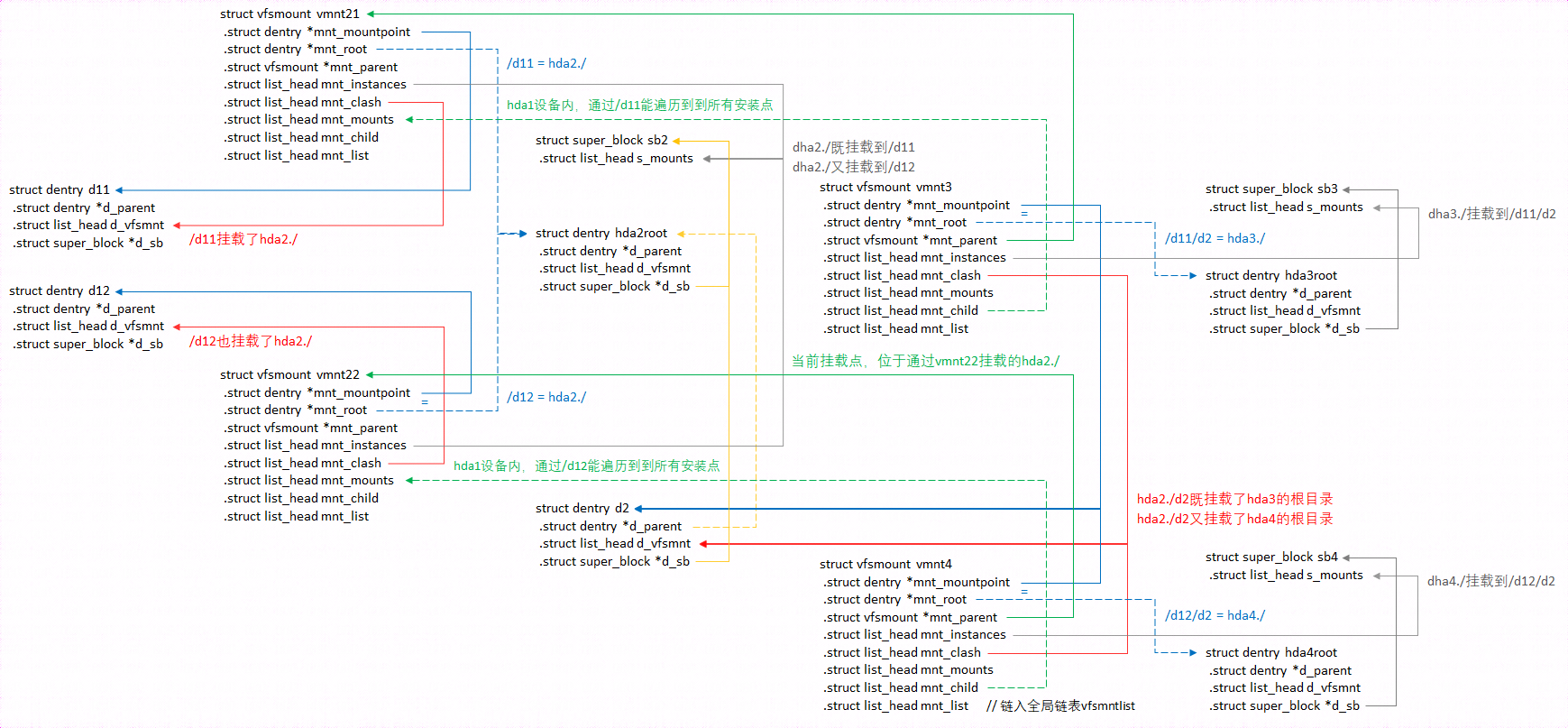
上述内容已经介绍过,挂载本质上就是,让挂载目录的dentry,与挂载设备内部的根目录dentry等价。Linux内核为此设计了vfsmount数据结构,它就相当于2个dentry之间的"等号", 其中的mnt_mountpoint、mnt_root成员,就分别为"等号"两边的dentry。
struct vfsmount {
struct dentry *mnt_mountpoint;
struct dentry *mnt_root;
struct vfsmount *mnt_parent;
struct list_head mnt_instances;
struct list_head mnt_clash;
struct super_block *mnt_sb;
struct list_head mnt_mounts;
struct list_head mnt_child;
atomic_t mnt_count;
int mnt_flags;
char *mnt_devname;
struct list_head mnt_list;
uid_t mnt_owner;
};其实,如果仅仅为了,可以建立2个dentry之间的等价关系,直接在dentry结构中添加一个mnt_root成员,也是可以的(让挂载目录dentry. mnt_root,指向挂载设备内部的根目录dentry即可),但是为了能使挂载满足以下更复杂的场景,就直接和间接的需要其它更多信息,因此内核就将这些信息抽离出来,独立定义了vfsmount结构。
同一个设备,可以挂载到多个挂载点,因此需要mnt_instances 成员,链入super_block.s_mounts链表(super_block结构用于描述设备信息),以便于查询,每台设备上(以其内部的目录作为挂载点),挂载了哪些其它设备;
同一个目录,也可以挂载多个设备,因此需要挂载设备内部根目录的dentry.mnt_clash成员,链入挂载目录的dentry.d_vfsmnt链表。这是为了能从挂载目录,通过"等号","滑到"挂载设备内部的根目录。
struct dentry {
atomic_t d_count;
unsigned int d_flags;
struct inode *d_inode;
struct dentry *d_parent;
struct list_head d_vfsmnt;
struct list_head d_hash;
struct list_head d_lru;
struct list_head d_child;
struct list_head d_subdirs;
struct list_head d_alias;
struct qstr d_name;
unsigned long d_time;
struct dentry_operations *d_op;
struct super_block *d_sb;
unsigned long d_reftime;
void *d_fsdata;
unsigned char d_iname[DNAME_INLINE_LEN];
};不过,拿"变量赋值"作比喻,将同一个值,赋给不同的变量,是很容易理解的,但是给同一个变量,赋多个不同的值(x即等于5,又等于10),就比较费解了。所以问题就来了,怎样才能产生这种情况,以及访问挂载目录时,怎么选择沿着哪个"等号"往里走呢?
2.2.1. 实例
假设hda1~4分区内部的根目录内容,分别如下:
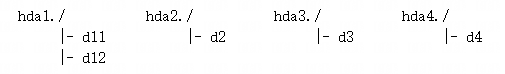
那么,按照A、B1、B2、C、D的顺序挂载后,就会使得hda2分区的/d2目录,既挂载了hda3分区,又挂载了hda4分区:

2.2.2. dentry & vfsmount
实例中的目录结构,加载到内存后,dentry之间的"等价关系":
2.3. sys_mount()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

2.4. sys_umount()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

3. 文件打开、关闭
3.1. task_struct & dentry
文件除了dentry和inode描述信息外,还要有"读写位置"等操作信息,即"读写上下文", 每个进程必须各自保存自己的"读写上下文",因为同一个文件,可以同时被多个进程读写,如果放在dentry和inode这种"公共位置",就会暴露给其它进程。
所谓打开文件,就是当前进程,为自己创建一个"读写上下文",内核为此设计了file数据结构,由于一个进程,可以重复打开同一个文件,也可以打开多个文件,所以,task_struct结构中,就通过files_struct结构,间接包含了一个struct file *fd_array[]数组。其实,open()系统调用的返回值(通常用int变量fd接收),即为该数组的下标(dup()/dup2()系统调用,本质上就是,将fd1下标处的file指针,赋值给fd2下标处的file指针,使它们指向同一个file结构)。

上图除了展示task_struct与file结构之间的关系,还整体展示了VFS层与ext2文件驱动层,其它关键数据结构之间的联系,对后续sys_open()、sys_close()、sys_write()、sys_read()函数的分析,可以起到地图的作用。
3.2. sys_open()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

3.3. sys_close()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

4. 文件读、写
4.1. 缓存页面
struct inode .struct address_space i_data // 缓存页面队列 (别与以下i_data[]混淆) .struct address_space *i_mapping // 通常=&i_data .union u .struct ext2_inode_info ext2_i .__u32 i_data[15]
ext2驱动在缓存和硬盘中,按记录块为单位,对文件内容进行存储,而VFS层按页面为单位进行缓存(address_space结构包含很多链表,用于挂接page对象),这样的设计,存在3个特点:
(1) 通过关联page、buffer_head管理结构,很容易就能关联物理页面与记录块:

"page-物理页面"关联
page管理结构,游离于对应物理页面之外,page在mem_map[]全局数组中的下标,即为对应页面在系统中"物理页面数组"中的下标;
"buffer_head-记录块"关联
buffer_head管理结构,游离于对应记录块之外,通过b_data成员,指向对应记录块;
"page-buffer_head"关联
buffer_head通过b_this_page成员,链入page的buffers链表。
(2) 不光满足了文件缓存的设计需求,也方便实现文件到虚拟内存的映射(mmap());
(3) 一个页面通常可以容纳4个记录块,隐含少量"预读"操作。
4.2. 逻辑-物理记录块映射
从文件内容的开始,按记录块大小分为多块,这些块就称为"逻辑记录块",每个逻辑记录块的内容,都来自硬盘上实际的"物理记录块",其中,文件中的1号逻辑记录块内容,可能由硬盘上的100号物理记录块存储,文件中的2号逻辑记录块内容,可能由硬盘上的5号物理记录块存储,因此,为了记录这种映射关系,就需要一张表,这便是inode.u.ext2_i.i_data[15]的作用:
i_data[0~11]:下标值为逻辑块号,i_data[]直接为对应的物理块号;
i_data[12]:保存一级间接映射记录块号,进一步包含12+(0~255)逻辑块号,对应的物理块号;
i_data[13]:保存二级间接映射记录块号,进一步包含256个一级间接映射记录块号,进一步包含268+(0~65535)逻辑块号,对应的物理块号;
i_data[14]:保存三级间接映射记录块号,进一步包含256个二级间接映射记录块号,进一步包含65536个一级间接映射记录块号,进一步包含65804+(0~16777215)逻辑块号,对应的物理块号。

直接+间接映射相结合的方式,既保证了大多数文件可以避免间接映射,或者只使用少量间接映射,又保证了超大文件需要使用大量映射项的需求(任意打开一块硬盘,超大文件占比一般都很小)。
4.3. 预读
预读可以提高读取性能,基于的事实:
(1) 磁盘读取,耗时最多的是移动磁头,磁头移动到位之后,多读一些内容,对整体时间的影响不大;
(2) 磁盘读取,绝大多数情况,都具有局部连续性,对于一次读取操作,读了一个记录块之后,往往很快也会读取紧接着的多个记录块;
(3) IO读取,由DMA独立完成,不需要CPU参与。
乍一想,"预读"功能的开发难度,几乎为0,大不了参数要求读10个页面时,sys_read()同步读取10个页面后,再启动异步读取,也读取10个页面(预读是异步的,sys_read()函数只会等待同步读取页面,不会等待预读页面)。
但是,细想的话,这样就过于简单粗暴了,对预读时机和预读量的控制一定要得当,否则,少读会降低预读的效果,而多读甚至可能适得其反("预读页面即将被访问"不是根据理论推断的,而是根据经验,那么就不能排除,预读可能就是白读,虽然IO由DMA完成,但分配缓存页面,还是会消耗CPU时间以及内存的)。
Linux内核对预读时机和预读量的控制算法,在do_generic_file_read()函数内部实现,原理可以参考:https://www.cnblogs.com/sky-heaven/p/16423350.html,以下两幅图是我额外添加,用于辅助理解。
预读上下文连续
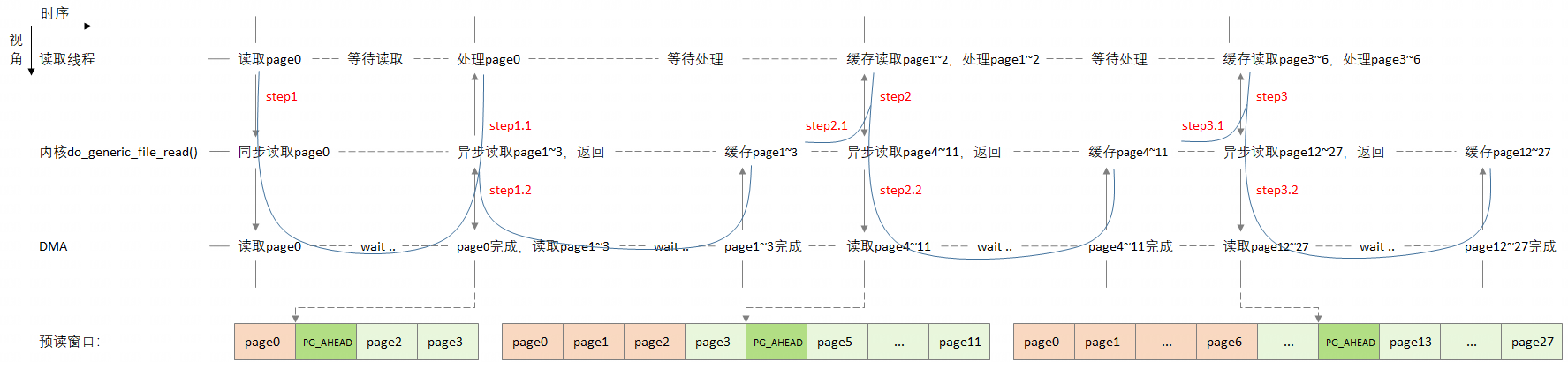
预读上下文切换

4.4. BH_ dirty & BH_Uptodate
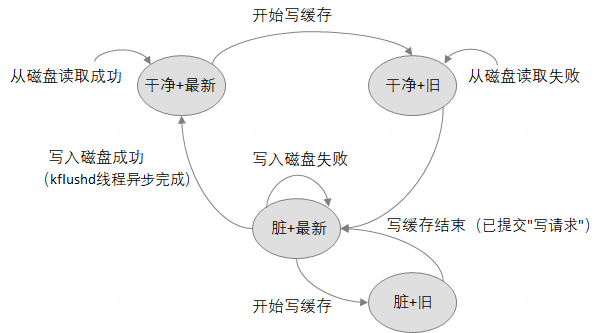
个人理解(详见代码注释):
任何造成"需要根据缓存更新磁盘内容"的操作之后,BH_Dirty=1;
任何造成"需要根据磁盘更新缓存内容"的操作之后,BH_Uptodate=1。
4.5. sys_write()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

4.6. sys_read()
插入代码,超过字数,添加"关键函数调用关系.txt"附件,没有找到附件功能,请看大图:

早在ext2_lookup()函数中,就看到过读入父目录,以及在父目录中读取目标文件的过程,由于那个过程中,读取逻辑完全由内核本身掌握,所以实质上,上下文已经融入在ext2_lookup()函数的读取逻辑中了,不需要通过打开父目录文件,显式的创建一个上下文。但是对于sys_read()函数,读取意向,由用户态的程序通过参数指示,所以读取前,一定要先打开,创建上下文。