导读:语音是人类信息沟通的重要途径,同时也是人机交互的重要桥梁,自动语音识别可以表述为通过计算机将人类语音信号转录为书面形式的文字输出的过程。本文分享了网易易盾提出的多级建模单元的端到端汉语语音识别方法及具体的落地实践。(文 |网易易盾-杨玉婷)
1.语音识别简介
语音是人类信息沟通的重要途径,同时也是人机交互的重要桥梁,自动语音识别(Automatic Speech Recognition,ASR)可以表述为通过计算机将人类语音信号转录为书面形式的文字输出的过程。
自 20 世纪 50 年代以来,自动语音识别问题就一直是机器学习界的一个重要研究课题。在过去几十年里,语音识别经历了从基于 GMM-HMM 的传统语音识别技术到端到端语音识别技术的发展历程。在传统的语⾳识别框架中,整个自动语音识别系统由多个模块组成,包括声学模型、发音词典和语言建模。端到端语音识别系统使用单个序列到序列模型,直接将输入的声学特征序列映射到文本序列,与传统的 GMM-HMM 混合系统相比,端到端语音识别方法具有训练流程简单、系统组成简单、识别效果好等优点,是目前学术研究和工业落地的热点。
2.为什么要用多级建模?
选择建模单元是构建 ASR 系统的重要一环,目前端到端汉语语音识别系统通常选择汉字作为模型的建模单元。然而,建模单元的选择不仅仅是涉及到网络的输出,也应该跟语言特性相关。汉语具有一定的语言特性,我们常说英语表音,汉语表意,看到一个英文,也许并不认识这个单词,但我们可以读出来,而看到一个汉字如果不认识的话,也许能猜出它的意思,但不能知道知道汉字的读音。也就是说汉字是一种文字符号,本身与发音无关。因此直接选择汉字作为端到端汉语语音识别系统的建模单元,模型很难学习到声学特征和发音单元之间的映射知识,同时由于语音和汉字之间没有“发音”关联性,模型直接学习从语音映射到汉字会变得困难。
针对上述问题,我们提出了一种多级建模的端到端汉语语音识别方法,除了汉字(Character-level)建模单元,我们还在模型中引入了音节(Syllable-level)作为建模单元。具体地,多级建模方法基于 Encoder-Decoder 的架构,使用多任务学习 hybrid CTC/Attention[1] 方式进行训练,其中 CTC 分支使用音节作为建模单元,使得模型可以学习到从语音特征序列到音节序列的映射信息,而 Attention 分支使用汉字作为建模单元,利用序列上下文信息和声学特征将音节转换为最终输出的汉字。多级建模单元使得模型在训练的过程中能够融合学习多级信息,包括音韵学信息和序列上下文信息,从而提升汉语语音识别的性能。
3.多级建模方法
模型架构
我们的模型使用了两级建模单元,包括汉字建模单元和音节建模单元。在训练阶段,使用语音特征序列和标注文本组成的数据对(X, Y)来训练网络,每个汉字可以由一个带调的音节表示,文本序列 Y 通过开源工具 Python-pinyin[2] 可以得到音节序列 S_Y,例如“北 京 天 安 门”转换成音节序列“bei3 jing1 tian1 an1 men2”。统计训练数据中出现的汉字并编号得到汉字词典,统计训练数据中出现的音节并编号得到音节词典。
下图展示了我们的多级建模系统架构。整个模型主要由前置的卷积模块, Encoder 模块和 Decoder 模块构成。前置的卷积模块提取输入序列的局部特征,并对序列进行下采样,减小后续的计算开销。Encoder 可以是 Conformer[3] 网络或者 Transformer[4] 网络。其中,Conformer 编码器层主要由四个子层构成:一个前馈网络层、自注意力模块、卷积模块和第二个前馈网络层。Transformer 编码器层主要由两个子层构成,分别是自注意力模块和前馈网络模块。解码器层由堆叠在一起的三个子模块组成:自注意力模块、多头注意力模块和前馈网络模块。
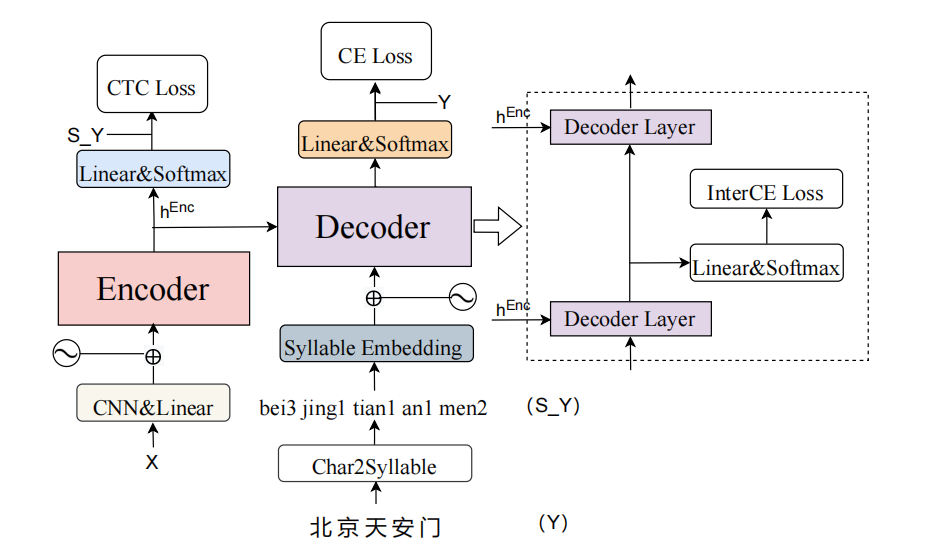
多级建模方法核心点在于:
音节建模:CTC 分支使用音节作为建模单元,特征序列X经过卷积模块和 Encoder 模块得到声学特征向量,通过一个全连接层将特征映射成音节字典大小的向量,再进行softmax归一化得到每一帧的概率分布,联合目标音节序列 S_Y 计算 CTC loss。
汉字建模:Attention 分支使用汉字作为建模单元。Decoder 模块接收音节embedding 向量和 Encoder 模块输出的声学特征向量作为输入,Decoder 的输出通过一个全连接层将特征映射成汉字字典大小的向量,再进行 Softmax 归一化得到概率分布,联合目标汉字序列 Y 计算 CE loss。
在多级建模方法中,Deocder 模块接收音节 Embedding 和声学特征向量作为输入,输出汉字序列,承担了将音节转换为汉字(Syllable-to-character)的任务。相对于利用之前时间步的汉字序列信息和声学特征预测下一个时间步的汉字(Character-to-character),将音节序列转换为汉字序列是一个更具有挑战性的任务。因此,我们在 Decoder 模块引入了中间层的辅助任务来促进从音节到汉字的转换,从而提升系统的性能,我们将辅助任务模块命名为 InterCE。
InterCE loss 的计算是使用 Decoder 模块中间层的输出,经过线性层和 Softamx 得到概率分布,最后计算和标注文本的交叉熵。整个网络的目标函数是基于音节的 CTC loss,基于汉字的 CE loss 和中间层 InterCE loss 的加权和。
模型推理
模型训练完成后,在推理阶段,Encoder 模块提取声学特征,Encoder 的输出通过线性层和 Softmax 函数得到每一帧在音节词典上的概率分布,通过 CTC prefix beam search 得到最优 N-best 的音节序列。Decoder 模块利用音节 Embedding 和声学特征向量作为输入,输出最终的汉字序列。模型推理的计算过程如下图所示。

实验验证
我们在汉语开源数据集 AISHELL-1[5] 上验证了多级建模方案的实验效果,AISHELL-1 包含来自 400 个说话人的 178 小时中文语音数据。我们分别使用 Conformer 网络和 Transformer 网络验证多级建模方案的效果。
在不使用语言模型的情况下,基于 Transformer 网络,多级建模方法在 AISHELL-1 上取得了 5.2% 的 CER,性能优于基于汉字建模和基于音节建模的基准模型。基于 Conformer 网络,多级建模方案在 Aishell-1 上取得了 4.6% 的 CER,优于最近发表的基于汉字建模的基准模型,实验结果表明多级建模方法提升了汉语语音识别性能。
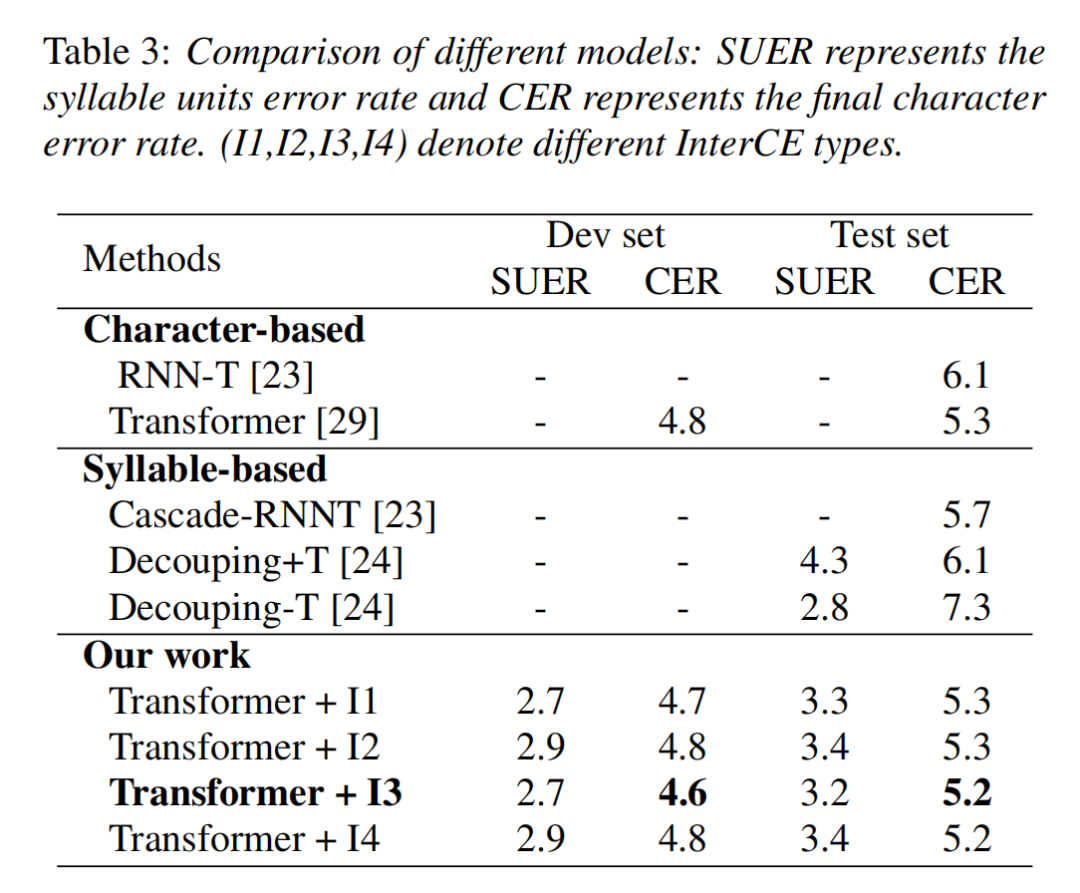
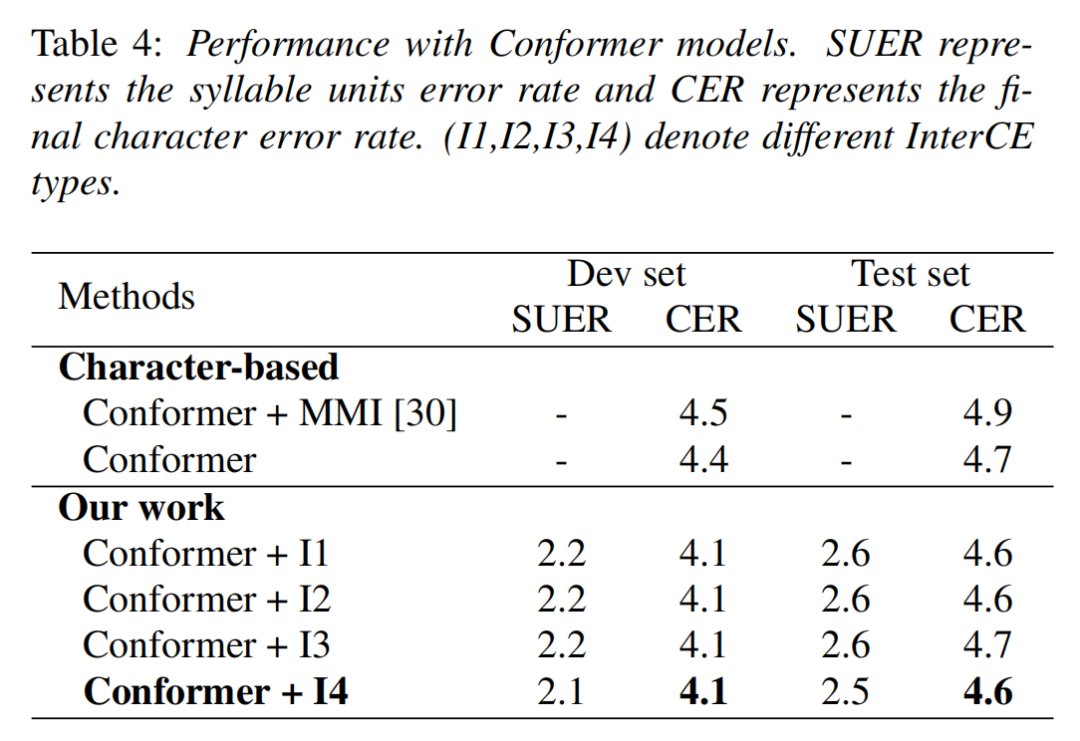
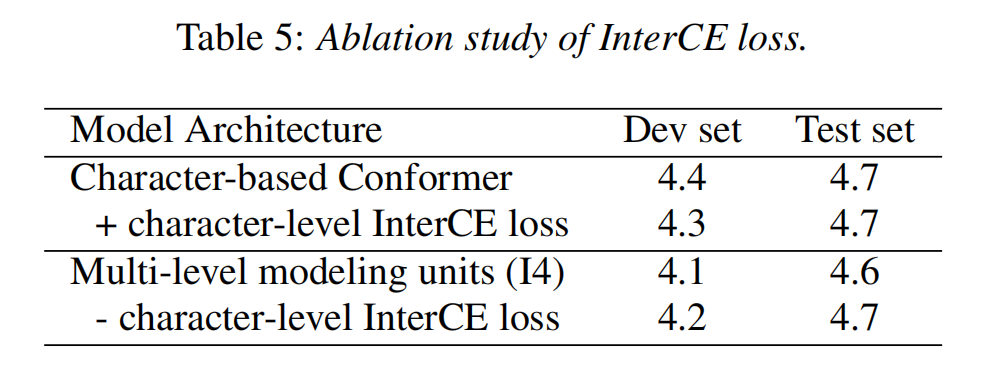
我们通过消融实验来分析 InterCE loss 带来的性能提升。首先,我们在基于汉字建模的模型中增加 InterCE loss 辅助任务,结果显示 InterCE loss 辅助任务只能带来轻微的性能提升。其次,我们将 InterCE loss 从多级建模的框架中移除,结果显示在验证集和测试集上性能有 0.1% 的下降。消融实验结果表明在一个端到端模型中使用音节和汉字两级建模单元可以提升汉语语音识别的性能,除此之外,在多级建模的框架下增加辅助任务 InterCE loos 可以带来额外的性能提升。
4.总结
在本文中,我们提出了一种多级建模单元的端到端汉语语音识别方法,通过多级建模的方式,模型可以融合学习多级信息。此外,我们引入了辅助任务 InterCE loss 来进一步提升模型的准确性。在推理阶段,输入的特征序列通过 Encoder 以及后续的 CTC 分支生成音节序列,随后 Decoder 模块将音节序列转换成汉字,整个解码过程通过一个端到端模型完成,无需引入额外的转换模型,从而避免了多个模型带来的累积错误。我们的模型在广泛使用的中文 Benchmark 数据集 AISHELL-1 上取得了具有竞争力的效果,并且优于最近发表的文献结果。
更多细节请参考 Paper 链接:https://arxiv.org/abs/2205.11998。
引用内容
[1] Watanabe S, Hori T, Kim S, et al. Hybrid CTC/attention architecture for end-to-end speech recognition[J]. IEEE Journal of Selected Topics in Signal Processing, 2017, 11(8): 1240-1253.
[2] Gulati A, Qin J, Chiu C C, et al. Conformer: Convolution-augmented transformer for speech recognition[J]. arXiv preprint arXiv:2005.08100, 2020.
[3] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[4] https://github.com/mozillazg/python-pinyin
[5] Bu H, Du J, Na X, et al. Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline[C]//2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA). IEEE, 2017: 1-5.