近年来,随着大数据、人工智能、云计算等数字技术的蓬勃发展,新技术带来了新业态和新的增长。然而,隐私泄露、网络欺诈、流量欺诈等现象的存在也成为数据要素健康流通的阻碍,为互联网治理带来挑战,因此构建一个安全的数据协作技术环境显得十分必要且紧迫。而隐私计算可以在数据不泄露的前提下,对数据进行计算并得到计算结果,在创造更好的数据底层环境的同时,体现数据深层价值,深入推动行业传统数据业务转型。
然而什么是隐私计算?有专家认为,隐私计算是指在保护数据本身不对外泄露的前提下实现数据分析计算的技术集合。从技术机制来看,隐私计算涉及三大技术体系的联合创新:其一是人工智能算法;其二是分布式系统和底层硬件;其三是密码学设计。
对于隐私计算而言,一般目前有几种比较主要的方法,包括安全多方计算(MPC),其提出者是唯一的中国籍图灵奖获得者姚期智教授(Paul Yao)。但在提出时由于计算机的算力非常有限,故仅存在于理论的模型,但随着计算机计算能力的整体提升以及集群/云计算的发展,使得安全多方计算成为现实;另外一种比较主流的是联邦学习,联邦学习本质上是人工智能的一种;第三种则是可信执行环境(TEE),即通过软硬件方法在中央处理器中构建一个安全的区域,保证其内部加载的程序和数据在机密性和完整性上得到保护。

图1 安全多方计算示意
本文主要讨论的是另一种与上述方法均存在差异的隐私计算方法(不是算法),即差分隐私(Difference Privacy)。那什么是差分隐私?简而言之,差分隐私就是利用一些随机化的方法,在两个邻近的数据集的查询结果中添加一些随机化的内容,使得攻击者无法通过查询结果的差异来推测其中存在的隐私信息。
那什么是邻近的数据集?严格的意义上而言,所谓临近数据集就是仅相差一条数据记录的两个数据集。那么什么又是推测结果呢?实际上推测就是我们不用通过直接访问含有隐私内容的数据,而仅仅是通过两次或多次查询数据集中的其它信息而间接计算得到相关结果。
有点抽象!举个简单的例子,如在一个单位里有99个员工,他们都是男士,且只有2个已婚人士,而此时又来了一个美女员工,但对于其它97个未婚男士(其它两个已婚男士没准也关心)急于知道这个美女的婚姻状况,于是他们可以通过统计员工数据库中的相关婚姻信息就能推测出这个美女到底是否为单身(注意只需要统计就行,而不用单独、直接地访问这位女士的个人记录),这就是通过相邻数据集来对某些隐私信息进行推测(因为美女员工入职前,所有已婚员工的数量是2,待她入职后则这个数量如果不变则说明她是未婚否则是已婚)。
那如何来防止这类间接的数据攻击呢?我们可以在查询的结果中加入一些所谓随机性,使得两次的查询结果间看上去是非常相似的,从而不能通过此类方法来进行。一般而言我们经常用的随机化方法就是所谓拉普拉斯(Laplace)随机化方法。
目前已经有不少开源项目都支持对于差分隐私的计算,如Facebook的Opacus框架或者Google RAPPOR算法。
下图是一个差分隐私的原理示意:
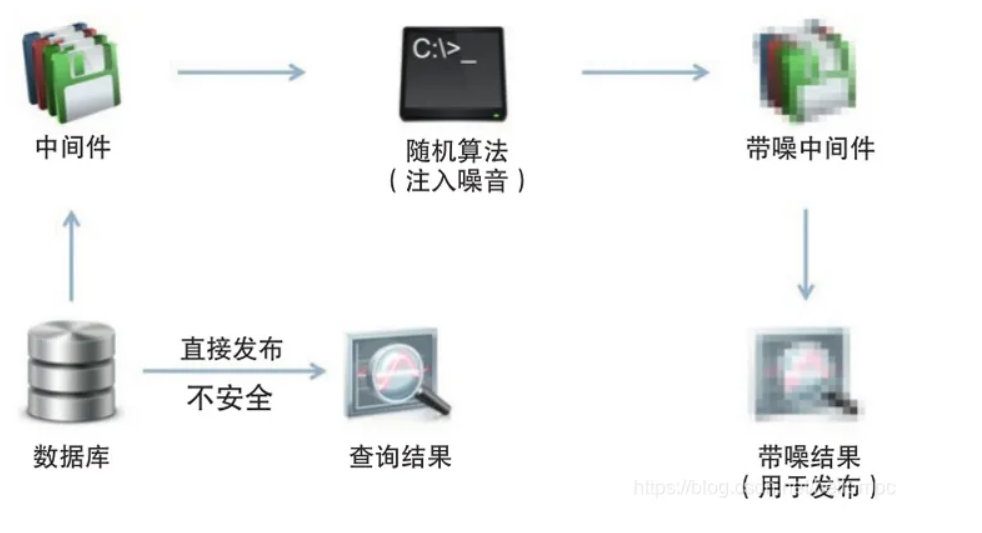
图2 差分隐私原理示意
可以看出,利用随机算法可以对原生的查询结果进行某种方式的混淆,从而使得攻击者无从推测出其真实内容,达到隐私数据保护的作用。当然随机算法采用哪种方式,并没有一定之规,除了拉普拉斯方法外也可以采用其它方式的随机算法,但其评价的标准一定是需要看混淆的差异是否足够小,以下是一个判断标准(此公式往往也是衡量差分隐私效果是否足够“完美”的标准):

上述公式就不多解释了(其中,Pr是概率函数,A是某种差分隐私计算算法,而D1和D2是两个相邻数据集)。对于一些细节,大家可以参考相关文献,总之需要记住的一点是ε(希腊字母,Epsilon)越小越好。
以上公式还有另一种常见形式,就是在概率公式后再加一个偏置,被称为德尔塔—— δ。
δ。
关于差分隐私的内容本期先简单聊到这里,今后聚铭网络将会给出更多关于数据安全方面的内容,敬请关注。