随着AI技术与网络安全结合得越来越紧密,基于AI技术的网络攻防手段也在日益更替。
11月26日,全球顶级的信息安全峰会HITB+Cyberweek 2021于近日举办,腾讯朱雀实验室专家研究员Jifeng Zhu和研究员Keyun Luo受邀参加,并进行了题为《Deep Puzzling: Binary Code Intention Hiding based on AI Uninterpretability》(《基于AI不可解释性的二进制代码意图隐藏》)的议题分享。
会上,腾讯朱雀实验室展示了如何利用AI模型的特性,实现二进制代码的意图隐藏,有效防止代码被黑客逆向分析,从而保障核心代码的安全。目前,朱雀实验室已将这项技术面向全球开发者开源,方便研究团队灵活取用,用前沿的AI技术助力网络安全的升级。
让黑客猜不透的“代码包装高手”
AI技术不断演进,黑客利用AI来进行网络攻击的事件屡见不鲜,传统攻防手法往往乏力应对,在此背景下,通过AI进行代码防护,开始成为行业的技术趋势。
相比传统攻防技术,AI算法具有诸多优势,例如,在复杂特征建模、内容生成、概率容错、不可解释性等方面拥有强大的能力。此次腾讯朱雀实验室推出的Deep Puzzling(深度迷惑)技术正是利用了AI的这些特点,前瞻性地对代码进行深层次的安全布防。
Deep Puzzling犹如一个“包装高手”,将多种载荷编码到AI模型的参数中,实现高强度的代码意图隐藏,由此来“迷惑”黑客,令其无法反向分析其中的代码逻辑。这样即使黑客取得了AI模型文件,也很难猜透代码的真实意图。这项技术有效地提高了代码的破解难度,可以帮助更多代码拥有者守护自己的知识产权和信息安全,抑制AI型网络攻击的滋长。
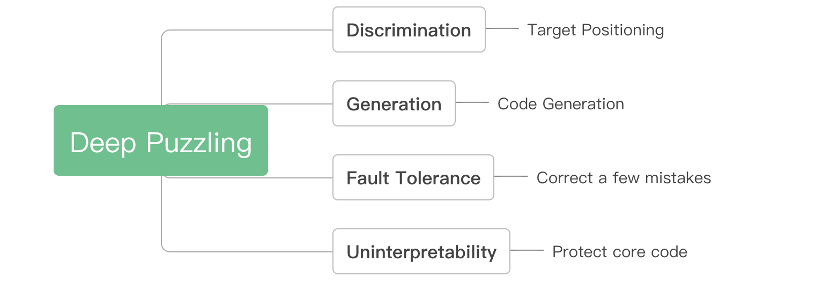
(Deep Puzzling核心能力)
让“意图隐藏”研究更具有实用性
其实早在2018年,就有前人尝试过利用AI技术来完成代码的意图隐藏。当时有研究人员提出了一种基于AI密钥的“包装”思路——DeepLocker,其工作原理为,只有特定目标经过AI模型产生的密钥才能解锁意图代码。这项研究展示了AI在意图隐藏方面的巨大潜力。

(DeepLocker工作原理)
不过,由于密钥解密代码的逻辑是暴露的,黑客仍然可以找到过程中的漏洞来盗取核心代码。
而此次腾讯朱雀实验室提出的Deep Puzzling在同一研究方向上进行了突破性的尝试,在这个技术框架里,有多个互相连接的模型,通过技术适应,保证让黑客无法通过修改输入数据的方式,来推测输出代码之间的逻辑关联,进而加大了逆向分析代码的难度,提高了核心代码的安全级别。
不仅如此,朱雀实验室还设计了一个检测模块,来验证这种方法的有效性。

(Deep Puzzling工作原理演示)
首先,通过读取海量的普通环境数据,构建一个“触发-生成-纠错”模型,端到端地实现了“目标定位-代码执行”步骤,然后直接生成载荷。
值得一提的是,这个系统还具备反调试能力。这种反调试能力并非传统的进程状态查看、时间分析、异常处理等,而是利用网络构造出没有任何“显式if”判断含义的计算过程,这个计算过程处于黑盒中,很难得知其因果关联性,因而具有良好的数据密封性。
此外,由于AI模型产生的代码有一定的错误率,研究员们还设计了一种纠错模型,来进一步降低局部解码的错误率,使得AI模型大概率地输出精确的结果,以确保被计算机正确地执行。
经过大量反复稳定性测试,有力地佐证了Deep Puzzling的可行性。朱雀实验室的研究员还透露,“我们邀请过业界多位资深的逆向工程研究人员来尝试破解,均无法解出,更加验证了这是一个非常值得关注的新方向。”
Deep Puzzling开源地址:https://github.com/aisecstudent/DeepPuzzling