2020 看雪SDC议题回顾 | 麒麟框架:现代化的逆向分析体验
发布者:Editor
发布于:2020-11-03 18:43
无论是对于硬件厂商还是安全行业来说,通过逆向深入研究各种攻击行为都十分有必要。
最关键的是,即使配置好了环境,现阶段绝大多数二进制分析工具或者框架都不支持进行更高层次的分析,这导致传统的二进制分析体验,尤其是针对物联网设备和恶意软件的分析体验是完全支离破碎的。
而麒麟框架基于完全跨平台的模拟,冲破种种传统二进制分析的束缚,在更高的层次上对不同的平台提供统一的分析接口,为广大安全研究人员带来焕然一新的现代化逆向分析体验。
下面就让我们来回顾看雪2020第四届安全开发者峰会上《麒麟框架:现代化的逆向分析体验》的精彩内容。

孔子乔,京东牧者安全实验室安全工程师,Lancet战队成员,GeekPwn 2019名人堂,Blackhat Asia 2020演讲者,Qiling和Unicorn的贡献者,主攻二进制分析和代码审计。
武晨旭,京东牧者安全实验室安全工程师,麒麟框架主要贡献者,BlackHat Asia 2020 演讲者 BUUCTF Re方向Top1。
以下为速记全文:
大家好,我是孔子乔。今天我和武晨旭为大家带来的议题是“麒麟框架:现代化的逆向分析体验”。
这是我们的目录,第一部分是演讲者介绍,第二部分是麒麟框架介绍,第三、四、五部分我们会分别给出3个例子来介绍麒麟框架怎样给大家更好的逆向体验。其中,第三部分会讲一下MBR插桩分析,这是一个比较简单的例子,主要用来展示我们麒麟的架构和它的设计。第四部分是麒麟框架调试层支持,这个待会儿由武晨旭待来讲。第五部分会说一下反OLLVM平坦化,这属于一个反混淆的例子。第六部分的话会谈一下我们的展望。
首先是演讲人介绍,刚才主持人已经介绍过我们两个了,我就只介绍最后一位吧。虽然没有站在台上,但还是应该介绍一下他,KJ是我们京东牧者安全实验室的创始人,也是各种安全会议演讲常客。
等会儿武晨旭还会帮我们介绍它对GDB调试的支持以及我们自己的调试Qdb。同时IDA插件也会为这个IDA提供一个动态插桩分析的能力。这样干讲不直观,所以我尽量用一张图让大家直观了解什么是麒麟框架。
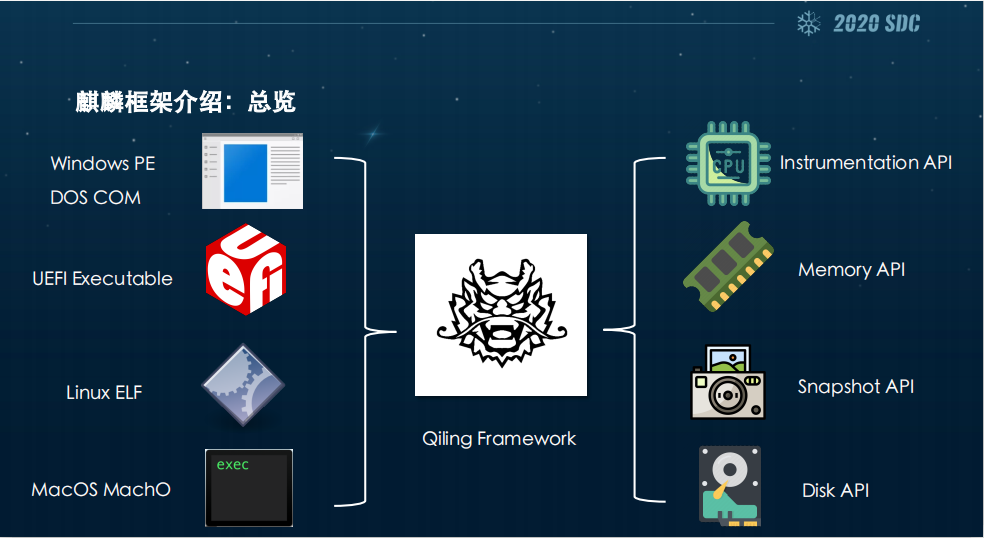
在这上层,麒麟框架会解析二进制文件,设置内存,同时实现关键的系统调用,然后再从二进制文件的入口点开始执行,不会去给你搞一个完整的系统。接下来我们怎么设计一个架构呢?最底层,就是Arch层,它比较贴近底层,会设置寄存器、内存和栈,还会负责架构相关的底层实现,像x86的GDT就是我们在这里实现的。
再上面一层就是Loader,Loader会去解析你输出的二进制,判断系统的类型,比如说你现在是在Windows上跑还是在Mac上跑,你想跑的目标系统是一个posix还是UEFI,它的符号也会在这个地方解析,然后去重定位,同时会去解析代码段,把它加载进内存设置堆栈,总之他就是为这个程序跑起来做好一切的前期准备工作。
Loader上面的最后一层是OS层,这一层也可以说是我们的核心实现,包括系统调用实现,同时也提供操作系统常见的相关抽象,比如说磁盘、文件路径等。
接下来说说分析API,等会儿我们在MBR插桩分析部分会仔细讲,在这里先简单提一下。图上左边可以看到寄存器、内存,包括我们引以为傲的插桩、磁盘和快照。

MBR是磁盘的第一个上区,相信大家都很熟悉了。我们知道8086,它虽然是16位的,但是它开启了分段并且有20位地址线,所以我们需要地址转换,这是在Arch层做的。Loader层就是解析COM文件或者MBR Dump,同时把硬盘映射给加上。而OS层主要是实现传统的BIOS中断。上一年代的分析员可能对这很熟悉,比如说我们用ncurse来实现BIOS图形服务和键盘服务,然后我们可以通过硬盘映射来实现硬盘服务,因此可以说麒麟框架是目前唯一一个可以对MBR进行插桩分析的框架。
样本分析呢是来自于Flare-On Challenge 8-doogie,这个大家都可以搜到。我们有一个工具叫qltool,跟Qemu usernmode有点类似,可以直接把它跑起来,不需要写代码。如果能跑起来之后,你会看到它会等待一个输入。这时候你随便输,一般会得到一些乱码。但他这里给了一个提示,会有一个日期显示是1990年2月6号,我们后面会用到它。

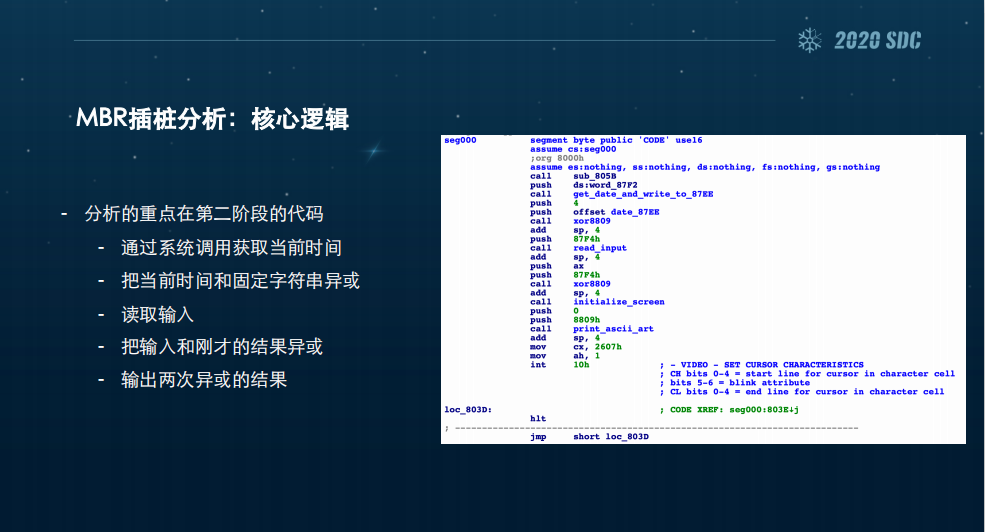
核心逻辑上我们关注的肯定是它跳转之后的逻辑。之后的逻辑其实也非常简单,第一部分首先通过中断来获取当前的时间,然后把当前的时间分成两个word,把一段固定词组进行异或,接着读取输入,和一个固定字段进行异或,这时候再输出两次异或的结果。

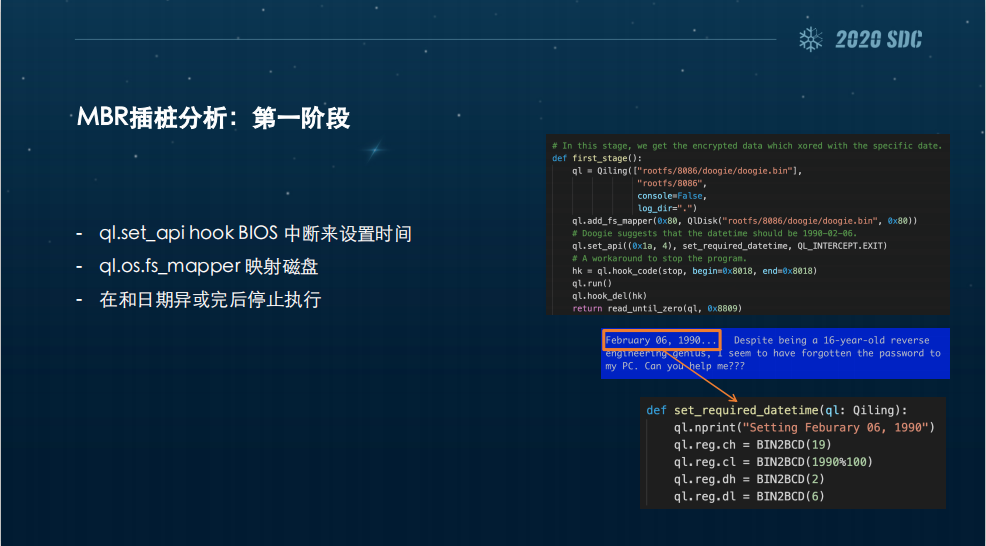
具体来说,第一阶段就是用ql.set_api ,通过它来Hook BIOS中断,设置时间,然后我们在ql.os.fs_mapper 里映射磁盘。之后在和日期第一次异或完后就停止执行,因为这个时候我们需要获得中间结果。


在运行它之前,首先我们需要用FS API把这个文件挂载到我们模拟的系统上,接着通过Set API把时间给设置一下。在系统调用完成之后,我们覆盖它原来返回的值,最后执行到读取输入之前,我们不读取输入,因为我们需要自动化地去破解这个工作,这是第一个阶段。
第三阶段也是最关键的一个阶段。因为它最后都是要打印的,Key肯定是不唯一的,所以我们要把每个Key试出来。这个阶段主要分为两步,先设计时间,然后再挂载硬盘。
这里最关键的是,我们在运行的时候先用ql.save,先把Contex保存下来,接下来我们把Key直接填入缓冲区,就我们跳入整个输入的函数。可以看到这里,直接把它填到缓冲区里面,直接跳过输入的函数,然后直接从输入读取完后开始执行,就只执行后面这半部分,Reading put全把它给跳过。执行一次之后返回,这时候再恢复刚才的上下文,再重新试下一个Key,接下来就是直接运行整个脚本。
后面这是一个分析脚本。这是第一阶段,跟日期异或之后结果就结束,第二阶段一下就跑完了,第三阶段就是把每个Key打印出来,在这儿要观察我们save/restore的速度。我们不会去保存系统的东西,只保存二进制的东西,所以它非常快。这里还有time.sleep一秒的延迟,所以这是一个非常方便的API。现在已经可以看到有些地方已经出Flag了,这里就不再继续播放了。
那么接下来,就由武晨旭来介绍麒麟框架的调试层。
大家好,我是武晨旭,接下来由我来介绍麒麟框架调试层的支持。我想先说一下当今逆向技术的痛点。首先来说PC端,PC端一直以来缺乏比较好用的HOOK工具。如果我们只有一台比如说像Windows系统的设备,但我们需要调试多个架构的程序,我们就需要使用多个虚拟机或者其它架构的实体机,这对于安全分析来说是有一定价格上的代价的。
对于这个痛点的话,麒麟框架有一个特点就是能够兼容很多架构,也就是说它能把主流的这些架构全部在一个机器上进行模拟。还有就是我们在麒麟框架里引用了demigod模块,使麒麟可以直接去模拟内核模块,比如说.sys、.ko、.kext等,省去了双机调试的麻烦。
还有另一个痛点在loT方面,这方面主要就是逆向环境搭建比较困难,因为它大多数是ARM、ARM64、Mips这些架构。另外,在调试方面我们的工具也是少之又少。举一个例子,如果我们想要去逆向调试路由器的话,首先我们要通过各种途径去获得固件,拿到固件后需要解包,那如何去调试呢?我们需要用Qemu把固件运行起来,运行起来以后我们再挂载GDB,去远程调试。
这其中还有一些问题,比如我们需要模拟一些设备或者网桥,这些东西我们自己去定义,设置这些东西的话,我们针对一种固件是可以的,但是换了另外一种固件之后,我们又需要重新再去设置一遍,这样的重复开发对于逆向调试来说时间成本就非常高了。
而麒麟框架可以完全把这个程序放到用户态去模拟,再进行任何方式的Hook,这其实是Qemu所做不到的东西。我们提供了非常多的Hook方式,比如说address hook、code hook,以及block hook等。
接下来展示一下我们麒麟框架现在支持的三种调试手段,一个是GDBSever(远程调试),一个是社区提供的基于命令行的qdb,还有一个就是IDA插件,是完全图形化的。
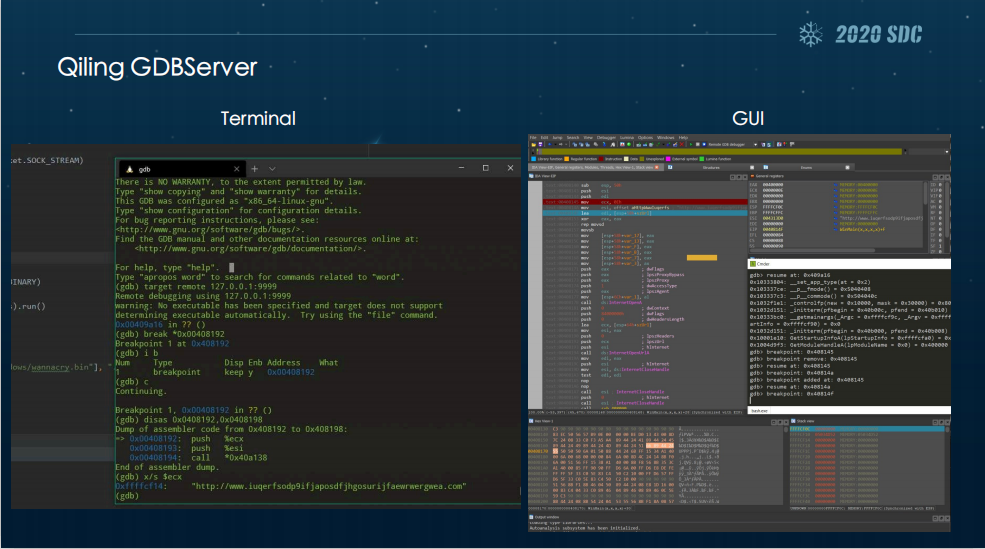
而用了麒麟的GDBSever,我们只需要一台机器就可以模拟所有主流的架构。但是在使用一段时间后,我们会发现麒麟的GDBSever也有一些复杂,比如说我们用GDB时,有些人会觉得反汇编的效果比较差,相比于IDA来说函数的分析没那么全,还有一个就是GDB可能对一些人来说比较难于操作。

通过麒麟与现代当今最主流静态反汇编工具IDA实现动静结合,能够更好地帮助逆向人员进行逆向工程和代码理解,当然之后还有些高级的功能比如说像反混淆、反平坦化,会由孔子乔来继续为大家分享。
这里我还要说的是IDA还有一个非常有趣的特点,就是它可以绘制控制流图中每一个block中指令的背景颜色。这个特点结合麒麟框架之后,我们就可以实现绘制程序的执行流程,这个功能对于一些垃圾代码,可能永远不会跑到的一部分指令,我们可以很方便地识别出来之后去除。

接下来想给大家演示的是一个著名的loT僵尸网络病毒Mirai。这个病毒有一些加密数据,这些加密数据是在运行时才解密,每次解密使用完后立刻再加密,因此我们如果想要提取大量被解密的数据,可能需要重复调试动作很多次,但是使用麒麟的话,只点几下鼠标就够了。
这是我们最后写好的自定义脚本,我们只需要把IDA插件载入IDA,当前这个例子只需要使用Continue、Step,在这两个位置进行Hook就可以了。
我们现在已经定位到被加密的数据了,我们找到它在Data段里面的地址,比如说我们现在选中了这一块Data地址,这些数据我们想解密出来,我们只需要找到里面的解密函数,把这段内存中的数据放进去即可,如果我们想解密的数据量非常大,可能有几百K、几兆的数据,也可以通过循环放进去,这样就可以做到人力轻易不可能做到的事情。
我们现在定位到的是解密函数,为了让大家看得更清楚,我们先在两端都放上断点,现在我们看到的就是它解密函数的算法,其实这些算法我们并不需要关心,我们只需要写好脚本,然后点击Continue。
现在来到了第一个断点,先展示一下内存窗口,可以输入任意一个地址,选择我们想看的内存的大小就可以展示出来。我们把想要解密的数据全部放到这下面这块内存中,等我们解密完之后也会把解密后的数据实时显示在这一部分。接下来我们只需要再点击一次Continue,它就会把我们想解密的所有的数据解密出来。接下来就由孔子乔继续为大家演示使用IDA插件进行反平坦化。
正如看经典数据加密解密一样,混淆与反混淆基本上是一个更普遍的话题,今天有很多的议题也都是关于反混淆的。OLLVM是一个非常著名的混淆器,它被研究得很多了。它基于LVM,这个可能大家都熟悉,它是一个前端中间有IR然后到后端。而OLLVM相当于是多加了混淆Pass,它中间有一个非常有趣的特点叫平坦化。为什么叫平坦化待会儿大家一看就知道了。
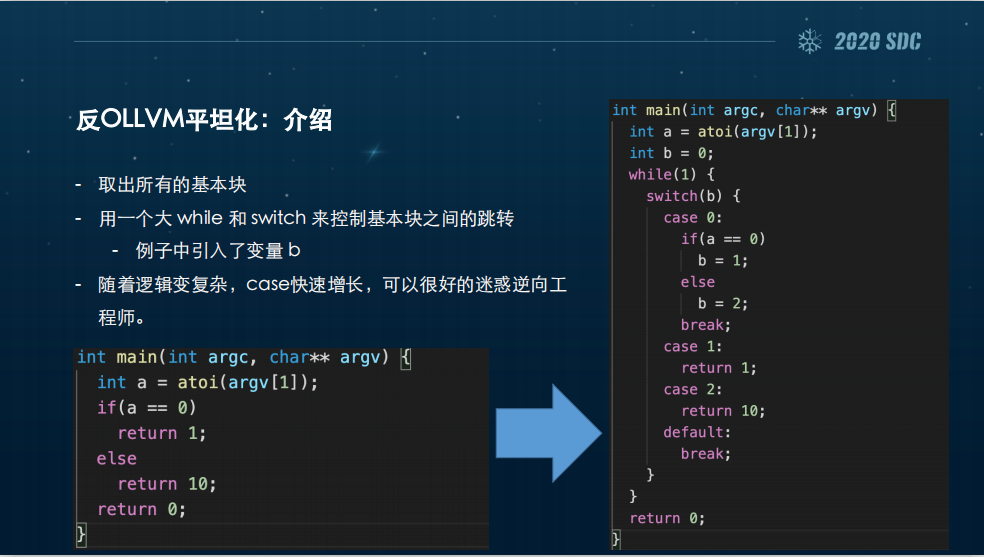
先讲它怎么工作的。首先它第一步是取所有的基本块,这个基本块会用一个大while和switch来控制基本块之间的跳转,大家来看左下角这个例子是LVM官方的例子,先取出a,如果a是0的话它返回1,否则返回10,如果都不是返回0。
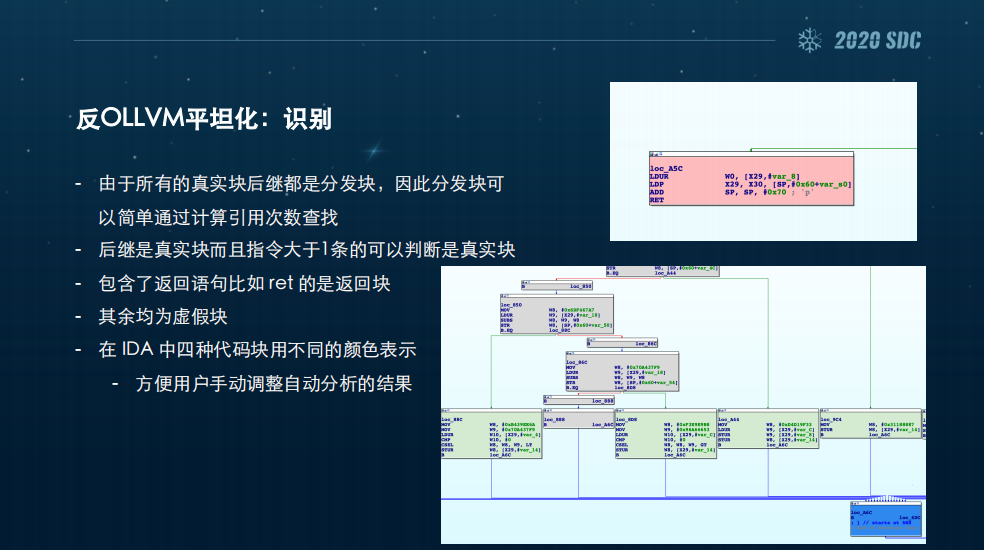
这里我们用的样本比较简单,是我自己写的一段程序,是用NDK配合OLLVM来进行译的,这个等会儿会给大家看视频。反OLLVM平坦化第一步就是识别,其识别是识别四种块。第一种是真实块,包含混淆前程序里面的真实逻辑,可能会有一次条件语句。第二种是虚假块,它是没有任何原逻辑的,仅仅负责switch case的实现,也就是我们刚刚引入的变量b它就会在这里。第三种是返回块,它会结束函数的执行。
最后一种就是分发块,它相当于一个switch语句,决定控制流走向。事实上,反混淆的核心就是识别分发块。我们可以看到右边这一块,如果是确定了分发块,剩下的块基本上都是可以直接退出来的。
在IDA插件中我用四种颜色来表示,因为你可以手动调整这些结果,编译参数不一样或者说优化等级不一样都会产生一些不一样的结果,所以有的时候需要我们手动调整一下这个结果。
那在这里,麒麟能干什么呢?刚才的一个议题说道量子执行混淆最大的特点是因为你不知道上下文,所以你不知道它接下的语句到底是干什么,但麒麟就能知道这个上下文,因为它能模拟执行,当前程序是干什么自然都知道。所以,在识别出各种块之后,需要用麒麟带着上下文寻找之前真实的控制流。
具体怎么用麒麟框架呢?首先用部分执行和快照,我们先从函数头开始保存快照之后,从任意一个真实块的起始开始执行,如果遇到分支就用强制执行各执行一次,直到遇到返回块或者另一个真实块停止,这样我们就找到了原来程序控制流程里面的一条路径。接下来我们记录下这条路径,再恢复快照到刚才的状态,然后再到下一个真实块去找,找到所有的真实路径。
此外,这里面我们是需要Hook内存读写来跳过对堆的读写的,因为我们知道很多时候我们会去读写堆,或者全局变量可能在堆上,要把这些读写屏蔽掉。
最后,我们再通过Keystone来patch,把原来的函数给patch掉,右边就是我们反混淆之后的结果,可以看到只保留了真实块和返回块,黄色的是第一个块,是设置堆栈的,不能删了。

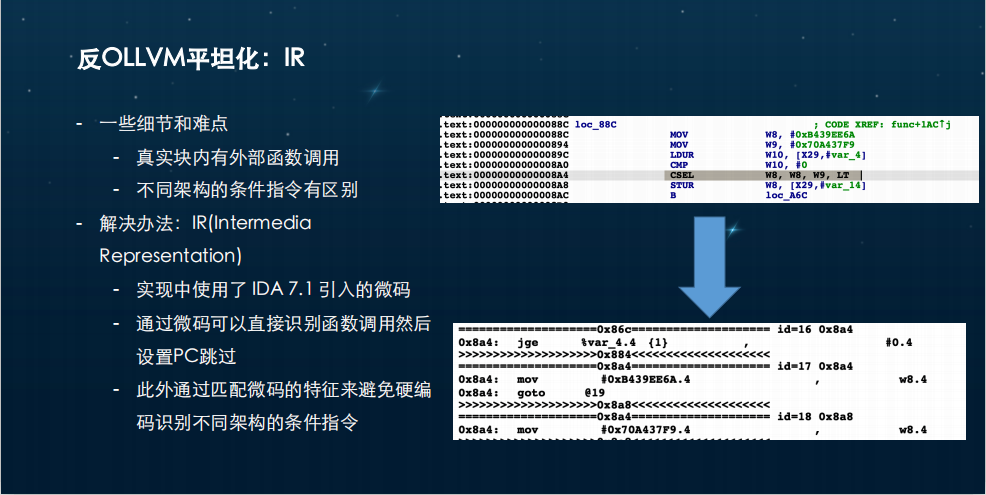
我们的具体实现是使用了IDA 7.1引入的微码,实际上就是一个IR。我们通过微码直接识别函数调用,然后设置PC跳过,就是我们刚刚说的Register API,把这些跳过。同时我们也会通过匹配一些微码特征来避免硬编码识别不同架构的条件指令。
接下来就是用视频给大家演示一下这个效果。首先原来的函数,可以看到相当平坦,所以叫平坦化。右边是真实逻辑,这个时候直接按F5这个逻辑是没法看的,这个逻辑有一个大while一个大switch,但是可以找到一些原来的蛛丝马迹,原来有一些逻辑是在里面的。
接下来第一步是要设置一下麒麟,因为我们需要一个Rootfs和一个自定义脚本,这里是用的example script,因为我们并不需要里面有太多的功能。
第一步自动分析,可以看到,这个蓝色的就是我刚才说的分发块,可以看到上面有很多的箭头,因为它的引用次数最多。接着就可以看到所有后期只要超过一条指令,我们都识别为真实块。
但是,实际上像旁边的Jump Location 978只有一条指令被识别为虚假块,但它也可以是真实块。这个不影响,我们也可以手动去进行调整。
再往上看这个虚拟块,因为是switch case,每一次跳转都是一个不同的case,再往上可以看到最初退出的那个case,也就是我们刚刚说的返回块。
这里我会故意把它设成真实块,来展示我们可以手动地去设置不同的基本块,而且这个是不影响的,仅仅是为了结果好看一些。接下来通过一个选项稍等一会儿就可以看到,这个在patch。大家也看到左下角控制流在飞速变化,因为我们在把虚假块消灭,同时把控制流改成真实控制流。
这里可以看到,相当于反平坦化之后的结果,只有真实块和虚假块,这个时候再按F5就可以看到逻辑恢复成了跟右边的逻辑基本一致的状态。以上就是反平坦化的例子。


最关键的是,即使配置好了环境,现阶段绝大多数二进制分析工具或者框架都不支持进行更高层次的分析,这导致传统的二进制分析体验,尤其是针对物联网设备和恶意软件的分析体验是完全支离破碎的。
而麒麟框架基于完全跨平台的模拟,冲破种种传统二进制分析的束缚,在更高的层次上对不同的平台提供统一的分析接口,为广大安全研究人员带来焕然一新的现代化逆向分析体验。
下面就让我们来回顾看雪2020第四届安全开发者峰会上《麒麟框架:现代化的逆向分析体验》的精彩内容。
演讲嘉宾
孔子乔,京东牧者安全实验室安全工程师,Lancet战队成员,GeekPwn 2019名人堂,Blackhat Asia 2020演讲者,Qiling和Unicorn的贡献者,主攻二进制分析和代码审计。
武晨旭,京东牧者安全实验室安全工程师,麒麟框架主要贡献者,BlackHat Asia 2020 演讲者 BUUCTF Re方向Top1。
演讲内容
以下为速记全文:
大家好,我是孔子乔。今天我和武晨旭为大家带来的议题是“麒麟框架:现代化的逆向分析体验”。
这是我们的目录,第一部分是演讲者介绍,第二部分是麒麟框架介绍,第三、四、五部分我们会分别给出3个例子来介绍麒麟框架怎样给大家更好的逆向体验。其中,第三部分会讲一下MBR插桩分析,这是一个比较简单的例子,主要用来展示我们麒麟的架构和它的设计。第四部分是麒麟框架调试层支持,这个待会儿由武晨旭待来讲。第五部分会说一下反OLLVM平坦化,这属于一个反混淆的例子。第六部分的话会谈一下我们的展望。
一.演讲者介绍
二.麒麟框架介绍
然后进入我们的麒麟框架介绍。首先是总览,麒麟框架本质上是在沙箱环境内模拟执行二进制文件,在模拟执行的基础上提供统一的分析API,这个API包括插桩分析、快照、系统调用和API劫持等。它的优点是它是跨系统的,比如说Windows、MacOS、BSD等,当然它也是跨架构的,在x86或者在arm等架构上,它是可以模拟这些架构的。另外它也是跨二进制的,常见的二进制麒麟框架现在基本上都支持了。
等会儿武晨旭还会帮我们介绍它对GDB调试的支持以及我们自己的调试Qdb。同时IDA插件也会为这个IDA提供一个动态插桩分析的能力。这样干讲不直观,所以我尽量用一张图让大家直观了解什么是麒麟框架。
中间就是我们的麒麟框架,大家可以把它想成一个黑箱,左边输入你的Windows PE或者DOS COM等,什么都行。比如Windows, UEFI Executable,实际上它也是一个PE,经过我们麒麟框架的模拟执行之后,框架能给些什么呢?第一我们会给一个插桩API,利用这个插桩你可以在你想要的地方去获得你的上下文,还有内存API和快照的API,另外还可以给出一些有关磁盘的API。
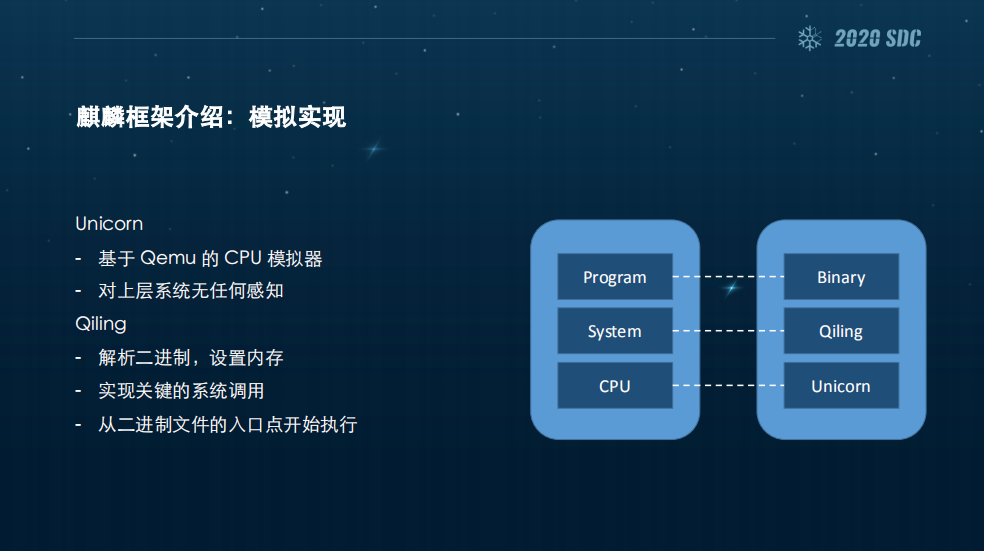
那我们模拟是怎么实现的?一般计算机有三层,最底层的是CPU,然后它上面运行着系统,系统上面则运行着程序。
麒麟框架的这种模拟实现其实跟这个是对应的,我们最下层是Unicorn,Unicorn是基于Qemu的CPU模拟器,它对上层系统是没有任何感知的。当Unicorn遇到一个interrupt或者syscall,会直接停下来。
在这上层,麒麟框架会解析二进制文件,设置内存,同时实现关键的系统调用,然后再从二进制文件的入口点开始执行,不会去给你搞一个完整的系统。接下来我们怎么设计一个架构呢?最底层,就是Arch层,它比较贴近底层,会设置寄存器、内存和栈,还会负责架构相关的底层实现,像x86的GDT就是我们在这里实现的。
再上面一层就是Loader,Loader会去解析你输出的二进制,判断系统的类型,比如说你现在是在Windows上跑还是在Mac上跑,你想跑的目标系统是一个posix还是UEFI,它的符号也会在这个地方解析,然后去重定位,同时会去解析代码段,把它加载进内存设置堆栈,总之他就是为这个程序跑起来做好一切的前期准备工作。
Loader上面的最后一层是OS层,这一层也可以说是我们的核心实现,包括系统调用实现,同时也提供操作系统常见的相关抽象,比如说磁盘、文件路径等。
接下来说说分析API,等会儿我们在MBR插桩分析部分会仔细讲,在这里先简单提一下。图上左边可以看到寄存器、内存,包括我们引以为傲的插桩、磁盘和快照。
为什么我说引以为傲呢?因为对于所有麒麟支持的系统和架构组合,比如说你在Windows上想去模拟一个UEFI的PE或者你在Mac OS上想去跑一个Windows的PE,只要是这些组合我们都可以提供统一的分析API。
接下来第三部分,我们会用一个相当简单的例子,也就是MBR插桩分析,来展示麒麟框架是怎么设计的。
三.MBR插桩分析
MBR是磁盘的第一个上区,相信大家都很熟悉了。我们知道8086,它虽然是16位的,但是它开启了分段并且有20位地址线,所以我们需要地址转换,这是在Arch层做的。Loader层就是解析COM文件或者MBR Dump,同时把硬盘映射给加上。而OS层主要是实现传统的BIOS中断。上一年代的分析员可能对这很熟悉,比如说我们用ncurse来实现BIOS图形服务和键盘服务,然后我们可以通过硬盘映射来实现硬盘服务,因此可以说麒麟框架是目前唯一一个可以对MBR进行插桩分析的框架。
样本分析呢是来自于Flare-On Challenge 8-doogie,这个大家都可以搜到。我们有一个工具叫qltool,跟Qemu usernmode有点类似,可以直接把它跑起来,不需要写代码。如果能跑起来之后,你会看到它会等待一个输入。这时候你随便输,一般会得到一些乱码。但他这里给了一个提示,会有一个日期显示是1990年2月6号,我们后面会用到它。
样本分析MBR大家肯定也很熟悉,这个阶段BIOS把MBR加载到 0x7c00开始执行,然后一般MBR会把自己的剩余代码通过磁盘服务再往后加载一段到内存,然后从那地方跳转执行,这个程序和其他的MBR代码的运行也是一样的。
核心逻辑上我们关注的肯定是它跳转之后的逻辑。之后的逻辑其实也非常简单,第一部分首先通过中断来获取当前的时间,然后把当前的时间分成两个word,把一段固定词组进行异或,接着读取输入,和一个固定字段进行异或,这时候再输出两次异或的结果。
接下来,我们的麒麟框架能怎样逆向这个东西呢?最基础的一点,我们可以把这个东西跑起来,去模拟MBR文件的运行。第二点的话,我们去Hook BIOS中断INT 1A 返回来改时间,就相当于它在跑的时候我们可以把它的时间改成那个时间,然后我们可以动态去读写内存,获得它各个阶段的缓冲区字符串。同时我们还可以用快照快速地尝试每个Key。
我们可以看到它的flag不是唯一的。破解也是分三个阶段的,第一阶段我们首先获取它和指定日期异或后的字符串,这个用到了Hook API,部分执行以及FS Mapper。第二阶段我们读取内存,搜索所有可能的Key,这个我们主要就是用Memory API来实现。最后一个阶段我们会测试每一个Key对不对,这里用的是Hook API,部分执行,Memory API以及快照API。
具体来说,第一阶段就是用ql.set_api ,通过它来Hook BIOS中断,设置时间,然后我们在ql.os.fs_mapper 里映射磁盘。之后在和日期第一次异或完后就停止执行,因为这个时候我们需要获得中间结果。
第二阶段我们用Memory API读取内存,猜测Key的长度,然后在假设最后结果是可打印ASCII码的情况下,把所有有可能的Key都搜索一遍。
最后一个阶段部分执行就直接跳过输入读取,然后保存快照,再通过 Memory API填入Key,把每一个都试一遍,然后再恢复快照,从读取后开始部分执行到打印字符,最后观察结果就可以得到一个Flag。
接下来给大家播放一个视频demo。我在这里稍微具体讲一下,这里首先是第一阶段,固定日期跟固定字符串异或之后的结果,我可以给大家先运行一下看一下,这就是用qltool来进行运行的。然后可以看到它有一个输入,同时有一个日期。
在运行它之前,首先我们需要用FS API把这个文件挂载到我们模拟的系统上,接着通过Set API把时间给设置一下。在系统调用完成之后,我们覆盖它原来返回的值,最后执行到读取输入之前,我们不读取输入,因为我们需要自动化地去破解这个工作,这是第一个阶段。
到了第二阶段,我们需要把第一次异或之后的结果拿出来,这里用一个算法。这个是地址,这个是结果,我们把结果拿出来之后,用一个算法去猜这个Key的长度。我们会假设它的结果应该都是可打印的,在这个前提下把所有的Key拿到。
第三阶段也是最关键的一个阶段。因为它最后都是要打印的,Key肯定是不唯一的,所以我们要把每个Key试出来。这个阶段主要分为两步,先设计时间,然后再挂载硬盘。
这里最关键的是,我们在运行的时候先用ql.save,先把Contex保存下来,接下来我们把Key直接填入缓冲区,就我们跳入整个输入的函数。可以看到这里,直接把它填到缓冲区里面,直接跳过输入的函数,然后直接从输入读取完后开始执行,就只执行后面这半部分,Reading put全把它给跳过。执行一次之后返回,这时候再恢复刚才的上下文,再重新试下一个Key,接下来就是直接运行整个脚本。
后面这是一个分析脚本。这是第一阶段,跟日期异或之后结果就结束,第二阶段一下就跑完了,第三阶段就是把每个Key打印出来,在这儿要观察我们save/restore的速度。我们不会去保存系统的东西,只保存二进制的东西,所以它非常快。这里还有time.sleep一秒的延迟,所以这是一个非常方便的API。现在已经可以看到有些地方已经出Flag了,这里就不再继续播放了。
那么接下来,就由武晨旭来介绍麒麟框架的调试层。
四.麒麟框架调试层支持
对于这个痛点的话,麒麟框架有一个特点就是能够兼容很多架构,也就是说它能把主流的这些架构全部在一个机器上进行模拟。还有就是我们在麒麟框架里引用了demigod模块,使麒麟可以直接去模拟内核模块,比如说.sys、.ko、.kext等,省去了双机调试的麻烦。
还有另一个痛点在loT方面,这方面主要就是逆向环境搭建比较困难,因为它大多数是ARM、ARM64、Mips这些架构。另外,在调试方面我们的工具也是少之又少。举一个例子,如果我们想要去逆向调试路由器的话,首先我们要通过各种途径去获得固件,拿到固件后需要解包,那如何去调试呢?我们需要用Qemu把固件运行起来,运行起来以后我们再挂载GDB,去远程调试。
这其中还有一些问题,比如我们需要模拟一些设备或者网桥,这些东西我们自己去定义,设置这些东西的话,我们针对一种固件是可以的,但是换了另外一种固件之后,我们又需要重新再去设置一遍,这样的重复开发对于逆向调试来说时间成本就非常高了。
而麒麟框架可以完全把这个程序放到用户态去模拟,再进行任何方式的Hook,这其实是Qemu所做不到的东西。我们提供了非常多的Hook方式,比如说address hook、code hook,以及block hook等。
接下来展示一下我们麒麟框架现在支持的三种调试手段,一个是GDBSever(远程调试),一个是社区提供的基于命令行的qdb,还有一个就是IDA插件,是完全图形化的。
首先麒麟的GDBSever可以连接到原生的GDB,以及任何支撑GDB远程调试的工具,比如说IDA、R2这样的。原生的GDB我们要去调试的话,它的缺点是我们要编译对应架构的GDBSever,然后还得放到对应架构的系统里去,再连接。
而用了麒麟的GDBSever,我们只需要一台机器就可以模拟所有主流的架构。但是在使用一段时间后,我们会发现麒麟的GDBSever也有一些复杂,比如说我们用GDB时,有些人会觉得反汇编的效果比较差,相比于IDA来说函数的分析没那么全,还有一个就是GDB可能对一些人来说比较难于操作。
于是我们后来又开发了IDA插件。麒麟的IDA插件功能方面主流的调试功能都有,包括像模拟执行,就是我们选中任何一段指令去模拟它,还有就是像Step、Continue这种比较常见的操作。此外,IDA插件还提供了实时的显示,比如说像寄存器、栈还有内存,都可以实时显示它当前运行的过程。最重要的一点前面孔子乔也提到了,我们有Binary级的快照功能,这个功能可以保存我们当前可执行文件的运行状态。
举个例子,比如说我们想做漏洞挖掘,需要对一个关键的函数做重复的操作。在做这个重复操作的时候,我们希望它每次输入变量的时候,函数所处的环境都是一模一样的,比如说像CPU的上下文、内存全部完全一样,这时我们就可以使用快照功能对它进行保存。同时,通过麒麟进行Fuzz也是这个原理。我们把当前的状态保存,然后一遍一遍输入变异的变量,从而发现漏洞。
通过麒麟与现代当今最主流静态反汇编工具IDA实现动静结合,能够更好地帮助逆向人员进行逆向工程和代码理解,当然之后还有些高级的功能比如说像反混淆、反平坦化,会由孔子乔来继续为大家分享。
这里我还要说的是IDA还有一个非常有趣的特点,就是它可以绘制控制流图中每一个block中指令的背景颜色。这个特点结合麒麟框架之后,我们就可以实现绘制程序的执行流程,这个功能对于一些垃圾代码,可能永远不会跑到的一部分指令,我们可以很方便地识别出来之后去除。
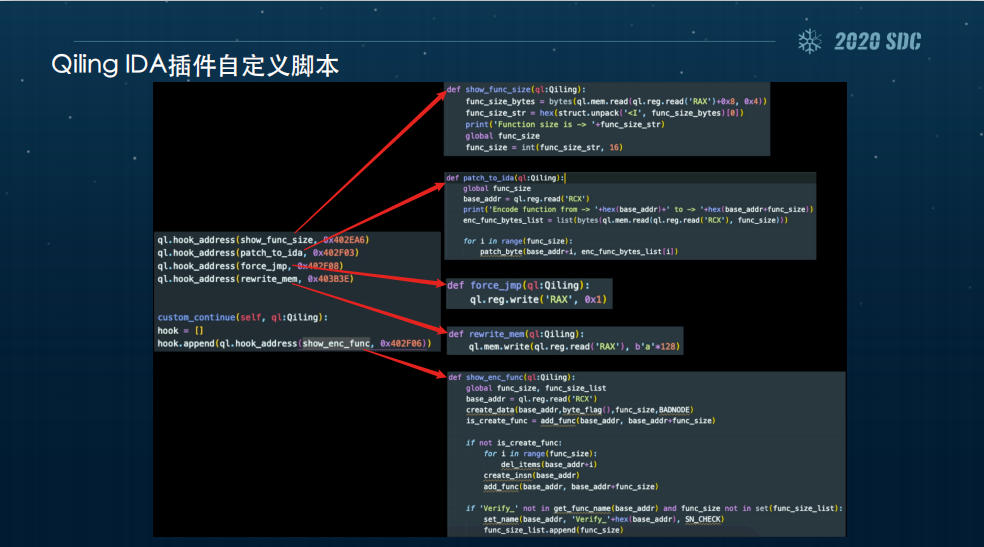
当然,麒麟的IDA插件也实现了自定义脚本,它可以将麒麟提供的所有的API以及IDA提供的所有API全部结合起来,放在这个脚本里。这个是自定义脚本的模板,一共有四个位置可以进行自定义,一个是在麒麟的初始化阶段,还有一个是在Continue阶段,也就是我们点击这个Continue时,以及后面点击Step时,还有一个是我们提到的可以选中任意一段代码去模拟执行时。
使用qiling IDA插件可以很方便地进行Hook,还可以再结合IDA读取信息,改写内存,实现任何我们想要的操作。
接下来想给大家演示的是一个著名的loT僵尸网络病毒Mirai。这个病毒有一些加密数据,这些加密数据是在运行时才解密,每次解密使用完后立刻再加密,因此我们如果想要提取大量被解密的数据,可能需要重复调试动作很多次,但是使用麒麟的话,只点几下鼠标就够了。
这是我们最后写好的自定义脚本,我们只需要把IDA插件载入IDA,当前这个例子只需要使用Continue、Step,在这两个位置进行Hook就可以了。
我们现在已经定位到被加密的数据了,我们找到它在Data段里面的地址,比如说我们现在选中了这一块Data地址,这些数据我们想解密出来,我们只需要找到里面的解密函数,把这段内存中的数据放进去即可,如果我们想解密的数据量非常大,可能有几百K、几兆的数据,也可以通过循环放进去,这样就可以做到人力轻易不可能做到的事情。
我们现在定位到的是解密函数,为了让大家看得更清楚,我们先在两端都放上断点,现在我们看到的就是它解密函数的算法,其实这些算法我们并不需要关心,我们只需要写好脚本,然后点击Continue。
现在来到了第一个断点,先展示一下内存窗口,可以输入任意一个地址,选择我们想看的内存的大小就可以展示出来。我们把想要解密的数据全部放到这下面这块内存中,等我们解密完之后也会把解密后的数据实时显示在这一部分。接下来我们只需要再点击一次Continue,它就会把我们想解密的所有的数据解密出来。接下来就由孔子乔继续为大家演示使用IDA插件进行反平坦化。
五.反OLLVM平坦化
先讲它怎么工作的。首先它第一步是取所有的基本块,这个基本块会用一个大while和switch来控制基本块之间的跳转,大家来看左下角这个例子是LVM官方的例子,先取出a,如果a是0的话它返回1,否则返回10,如果都不是返回0。
经过这个混淆之后,它引入了变量b,比如说b如果是1它跳转到返回1,如果b是2它跳转到返回10,也就是引入了一个跟原来逻辑无关的量,来控制真实的控制流。随着逻辑变复杂,case快速增长,可以很好地迷惑逆向工程师。
这里我们用的样本比较简单,是我自己写的一段程序,是用NDK配合OLLVM来进行译的,这个等会儿会给大家看视频。反OLLVM平坦化第一步就是识别,其识别是识别四种块。第一种是真实块,包含混淆前程序里面的真实逻辑,可能会有一次条件语句。第二种是虚假块,它是没有任何原逻辑的,仅仅负责switch case的实现,也就是我们刚刚引入的变量b它就会在这里。第三种是返回块,它会结束函数的执行。
最后一种就是分发块,它相当于一个switch语句,决定控制流走向。事实上,反混淆的核心就是识别分发块。我们可以看到右边这一块,如果是确定了分发块,剩下的块基本上都是可以直接退出来的。
识别的话,由于所有的真实块后期都是分发块,因此分发块可以简单通过引用次数查找的。后继是真实块而且指令大于1条的可以判断它就是一个真实块,而包含了返回语句的,比如说ret的,是一个返回块,其余的我们就都认为它是虚假块。
在IDA插件中我用四种颜色来表示,因为你可以手动调整这些结果,编译参数不一样或者说优化等级不一样都会产生一些不一样的结果,所以有的时候需要我们手动调整一下这个结果。
那在这里,麒麟能干什么呢?刚才的一个议题说道量子执行混淆最大的特点是因为你不知道上下文,所以你不知道它接下的语句到底是干什么,但麒麟就能知道这个上下文,因为它能模拟执行,当前程序是干什么自然都知道。所以,在识别出各种块之后,需要用麒麟带着上下文寻找之前真实的控制流。
具体怎么用麒麟框架呢?首先用部分执行和快照,我们先从函数头开始保存快照之后,从任意一个真实块的起始开始执行,如果遇到分支就用强制执行各执行一次,直到遇到返回块或者另一个真实块停止,这样我们就找到了原来程序控制流程里面的一条路径。接下来我们记录下这条路径,再恢复快照到刚才的状态,然后再到下一个真实块去找,找到所有的真实路径。
此外,这里面我们是需要Hook内存读写来跳过对堆的读写的,因为我们知道很多时候我们会去读写堆,或者全局变量可能在堆上,要把这些读写屏蔽掉。
最后,我们再通过Keystone来patch,把原来的函数给patch掉,右边就是我们反混淆之后的结果,可以看到只保留了真实块和返回块,黄色的是第一个块,是设置堆栈的,不能删了。
这里会有一些细节或者说难点。第一,真实块内部是有外部函数调用的。第二,不同架构的条件指令也是有区别的。我们这个反混淆可以支持x86,也可以支持ARAM也就是ARM64,我们的解决方法是用IR。其实可以说一下,刚刚说过LLVM是有IR的,OLLVM是一个Pass,它在IR上进行操作,也就是说从LLVM IR到汇编再到IR,实际上它的逻辑是有一定的等价性的,所以我们可以通过IR去寻找一些固定的Pattern。
我们的具体实现是使用了IDA 7.1引入的微码,实际上就是一个IR。我们通过微码直接识别函数调用,然后设置PC跳过,就是我们刚刚说的Register API,把这些跳过。同时我们也会通过匹配一些微码特征来避免硬编码识别不同架构的条件指令。
比如说右边是一个CSER,它是一个条件选择指令,类似我们在x86常见的comve,下面就是你看到它在同一个地址生成了4条指令,这就相当于微码用4条指令表示原来的一条指令。其实这在x86或者是其它的架构上都是类似的。
接下来就是用视频给大家演示一下这个效果。首先原来的函数,可以看到相当平坦,所以叫平坦化。右边是真实逻辑,这个时候直接按F5这个逻辑是没法看的,这个逻辑有一个大while一个大switch,但是可以找到一些原来的蛛丝马迹,原来有一些逻辑是在里面的。
接下来第一步是要设置一下麒麟,因为我们需要一个Rootfs和一个自定义脚本,这里是用的example script,因为我们并不需要里面有太多的功能。
第一步自动分析,可以看到,这个蓝色的就是我刚才说的分发块,可以看到上面有很多的箭头,因为它的引用次数最多。接着就可以看到所有后期只要超过一条指令,我们都识别为真实块。
但是,实际上像旁边的Jump Location 978只有一条指令被识别为虚假块,但它也可以是真实块。这个不影响,我们也可以手动去进行调整。
再往上看这个虚拟块,因为是switch case,每一次跳转都是一个不同的case,再往上可以看到最初退出的那个case,也就是我们刚刚说的返回块。
这里我会故意把它设成真实块,来展示我们可以手动地去设置不同的基本块,而且这个是不影响的,仅仅是为了结果好看一些。接下来通过一个选项稍等一会儿就可以看到,这个在patch。大家也看到左下角控制流在飞速变化,因为我们在把虚假块消灭,同时把控制流改成真实控制流。
这里可以看到,相当于反平坦化之后的结果,只有真实块和虚假块,这个时候再按F5就可以看到逻辑恢复成了跟右边的逻辑基本一致的状态。以上就是反平坦化的例子。
六.展望
最后一部分是展望。麒麟框架还是一个开发非常活跃的框架,目前最急的是要底层模拟同步Qemu5支持更多的架构和指令集,比如说ARM64可能会少一些指令,因为现在用的的QEMU有一点老了。
第二,我们会继续做Android Java层模拟和插桩。因为目前我们是在Native层做的,之后还会做iOS模拟的支持(目前只做了一半)。
第三,我们会继续完善Windows的支持。因为大家知道Windows是一个黑箱,做这个真的是很痛苦,我们希望引入一些外部的代码搞这个东西,目前打算是通过wine和cygwin来做。
第四,我们还会去做智能合约模拟、单片机模拟以及arm mac的模拟。
最后大家有什么想交流的可以来项目地址给我们提PR和issue。大家如果觉得我们的项目不错,给我们点一个星也是非常欢迎的。
也非常谢谢看雪给我们的机会,谢谢大家的聆听。
本届峰会议题回顾
2020看雪SDC议题回顾 | 逃逸IE浏览器沙箱:在野0Day漏洞利用复现
2020 看雪SDC议题回顾 | LightSpy:Mobile间谍软件的狩猎和剖析
2020 看雪SDC议题回顾 | DexVmp最新进化:流式编码
2020 看雪SDC议题回顾 | Android WebView安全攻防指南2020
2020 看雪SDC议题回顾 | 生物探针技术研究与应用
2020 看雪SDC议题回顾 | 世界知名工控厂商密码保护机制突破之旅
2020 看雪SDC议题回顾 | 敲开芯片内存保护的最后一扇“门”
2020 看雪SDC议题回顾 | 基于量子逻辑门的代码虚拟(vmp)保护方案
……
更多议题回顾尽情期待!!
注意:关注看雪学院公众号(ikanxue)回复“SDC”,即可获得本次峰会演讲ppt!
其他议题演讲PPT,经讲师同意后会陆续放出,请大家持续关注看雪论坛及看雪学院公众号!
- End -
声明:该文观点仅代表作者本人,转载请注明来自看雪