2020 看雪SDC议题回顾 | 基于量子逻辑门的代码虚拟(vmp)保护方案
发布者:Editor
发布于:2020-11-02 19:05
目前,代码虚拟(vmp)虽然仍是当前应用最广最有效的方案之一,但其机制已被完全研究透彻,在遇到不计成本的攻击下,其安全风险日益增大。
所幸,随着量子计算技术的蓬勃发展,给代码虚拟(vmp)保护的进化带来了新的机会和方向。
基于“量子逻辑门”的全新代码虚拟(vmp)保护方案将极大地增加代码语言的复杂度,帮助中大型企业在通信、支付、算法、核心技术等模块进行深度加密,有效增强安全性,避免因逆向破解造成的经济损失。
下面就让我们来回顾看雪2020第四届安全开发者峰会上《基于量子逻辑门的代码虚拟(vmp)保护方案》的精彩内容。
演讲嘉宾

赵川,VxProtect安全团队创始人,15年软件/安全从业经验。专注于软件安全保护、知识付费内容保护、区块链、保险行业大数据安全等领域。曾任职微软、网龙等公司。
演讲内容
以下为速记全文:
大家好,我是来自VxProtect团队的赵川,我们的团队是一群专注于安全技术的小团队,在我们研究软件加固与破解技术的过程当中,我们发现软件加壳技术中作为软件加固的核心VM本身的一些问题。针对这些问题我们做了一些研究,所以今天在这里跟大家分享一下。
今天主要讲的内容有三方面。第一个直接就是现有的VM,也就是VMP和TMP这两款工具系统架构的一些基础情况和它们本身存在的问题。第二就是今天我们标题当中的主题,通过参照当前量子技术的一些研究发现,基于量子的某些逻辑方案可以应用于我们的传统计算机中。之后第三个部分就是在这种思路上的变化当中,我们还能做出多少其他方面的变化。
一.市面上常见VM产品相关技术分析
目前市面上最流行的要数俄罗斯的VMP(VMprotect),与西班牙Themida系列的保护工具了。这两款工具虽然都号称有代码虚拟保护的功能,但原理还是有很大的不同,甚至是走了两个极端方向的。
首先我们介绍一下TMD的分析保护原理。Themida VM的原理就是一个大循环读取opcode,然后跳转到对应的handler上来进行解释执行,再跳转,再读取这样一个循环的过程。
即使后续相对应的RISC VM和原来的CISC VM,都是如此的结构。但它的提升和改进在于改成了堆机+x86的一种解释模式。到了新版本,在TMD上面就诞生了大家都很熟悉的“动物园”VM模式,从Fish VM到Tiger VM,到后面的Dolphin、Puma、Shark和Eagle,其实后面本身的改进升级也就是在它们自己原始的架构和指令集上进行循环的套娃,用这样的方式增加代码直接变形的复杂度。
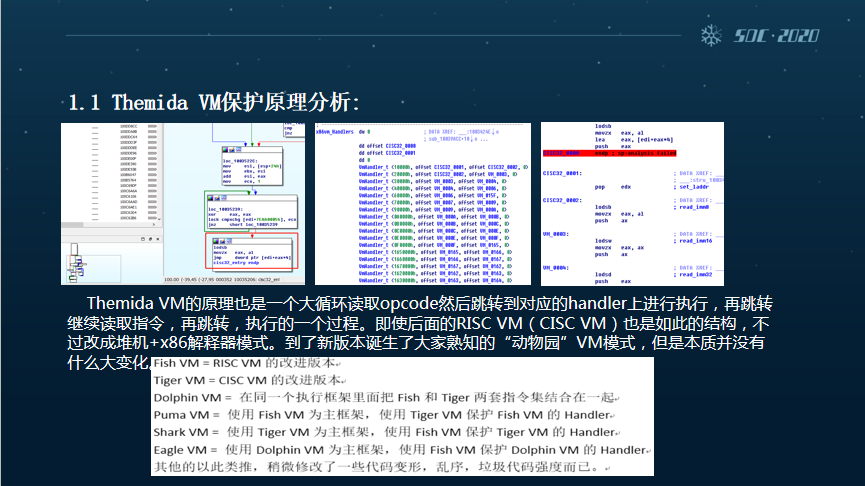
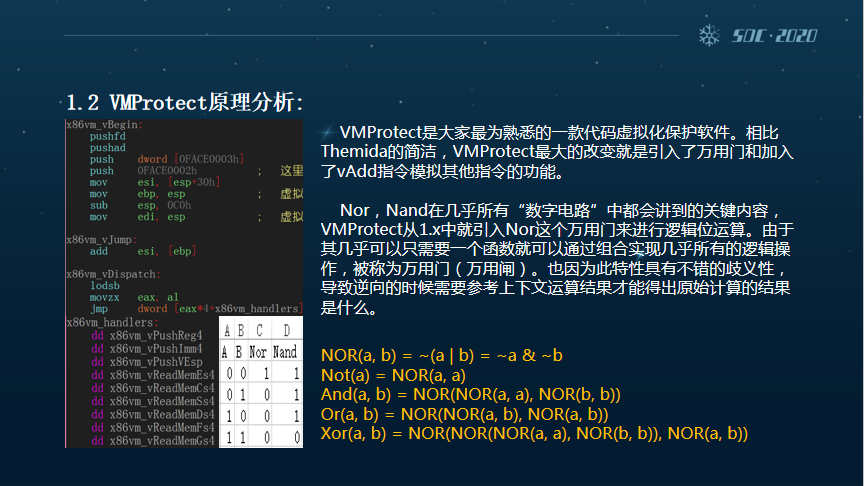
而VMP是大家最熟悉的一款虚拟化的保护软件,相比于TMD的简洁,VMP最大的变化就是引用了万用门,以及加入了vAdd指令,来模拟包括SUB等之类的指令功能。
我们知道,Nor和Nand在几乎所有的“数字电路”中都会提到的关键内容,在VMP1.0版本当中一开始就引入了了Nor这个万用门来进行逻辑位的计算。由于其几乎可以说只需要一个函数就可以通过组合实现几乎所有的逻辑操作,所以它被称为万用门,也称为万用闸。
同时也因此,该特性具有不错的歧义性,导致逆向的时候需要参考上下文才能得出原始的计算结果是什么。这里的黄字部分是我们对于VMP进行的一些现行研究。
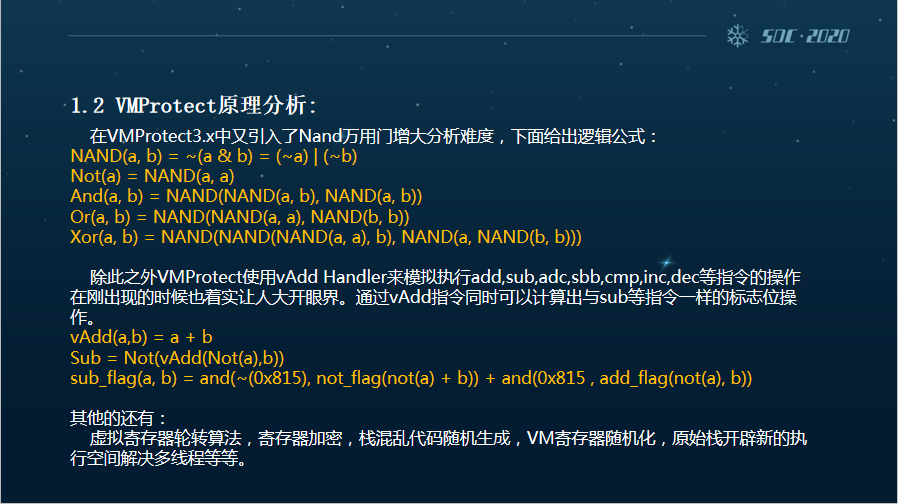
在VMP3.0版本中,又引用了Nand万用门增大分析难度,这是它的逻辑公式。除此之外,VMP还使用了刚刚讲的vAdd Handler来模拟执行包括add、sub、adc等这样的指令操作。
在刚出现的时候,这确实让人非常大开眼界。而且通过vAdd指令可以同时计算与sub等指令一样的标志位的操作,在这里我们也做出了一些指令的说明。而其他的还包括虚拟寄存器的轮转算法、计算器加密等技术。
总结一下,VMP本身的优点毋庸置疑,它通过万用门来增加了代码的歧义性之类的优点。它的缺点,我们总结出来就是代码变形和垃圾干扰代码过于单一,不少handler计算之后的pushfd无法变形,导致它会暴露原始handler的功能。而TMD最大的缺点是handler缺少歧义性,虚拟寄存器更是和x86、x64本身的指令是对应的,这样让还原的难度大大降低了。
一句话总结下就是,VMP是通过编译的复杂性,编码复杂的VmOpcode来增加它的还原难度,而TMD是通过代码变形让VmHandler更加难以识别,来增加难度。
二.Themida/VMProtect产品安全现状分析
在本身的软件还原部分,大家从原来的手工作坊,到逐行地进行直接分析,再到现在半自动化,使用对应的工具来进行代码的还原。现在我们就来展示几款相关的分析工具。
首先是TMD相关的分析工具,由于TMD的Handler基本上都是使用CPU的直接指令,导致只要分析VmOpcode流程规则就可以比较容易地分析出来原始的asm指令。而TMD早期版本的CISC VM和RISC VM目前已经可以比较完美地被OU1.8直接还原。
等到TMD2.0引入了“动物园”模式后,他其实是可以被Themida-Winlicense Ultra Unpacker等脱壳工具搞定的,但目前看来只有Dolphin,Puma,Shark,Eagle这几个版本号基于套娃的方式,虚拟机就会相对安全一些。但恰恰因为他基于套娃的这种方式,它还有一个很突出的缺点就是速度极其缓慢。
下面,我们来分析下VMP工具的现状。VMP最大的问题就是从它2004年发布第一个版本之后,到现在其实本质核心并没有太大的更新,只是增加了一个万用门。目前已经有大量可以直接对它进行逆向分析的自动化工具,比如说像VMP分析插件1.4、FKVMP,甚至已经商业化的xxVMP这种分析工具。
在这样的大背景下,TMD跟VMP遭遇到的这种情况本身也致使软件的安全防护技术需要得到发展。那么接下来,讨论一下现有技术架构上,我们自己团队研究了哪些让其可以前进的发展方向。
三.现有可增强的安全技术方向分析
在这种情况下我们要如何做呢?首先我想到的是要加强Handler的代码变形,让Vm Handler的代码面目全非,只要膨胀代码足够复杂就可以有效阻止Vm Handler直接被逆向分析。目前代码变形能力方面TMD会比VMP强悍得多,当然SE之类的壳会同时吸取双方的优点,让VMProtect的Vm Handler也变得更加复杂,甚至中间加入一些Dummy Jump来误认为这是一个Handler的结束,让分析工具无法直接分析出来。
第二个,VMP自己本身是没有手动调节变异强度的功能的,但它有一个Ultra选项可以让变异后的代码再进行一次VM虚拟化。只不过由于变形程度不高,在VMProtect3x下引入的Nand Handler可以和Nor相互之间进行模拟保护。同时,vAdd刚刚我们也说了,它也可以模拟Sub,再重复模拟,通过牺牲运算速度来加强代码膨胀的效果。
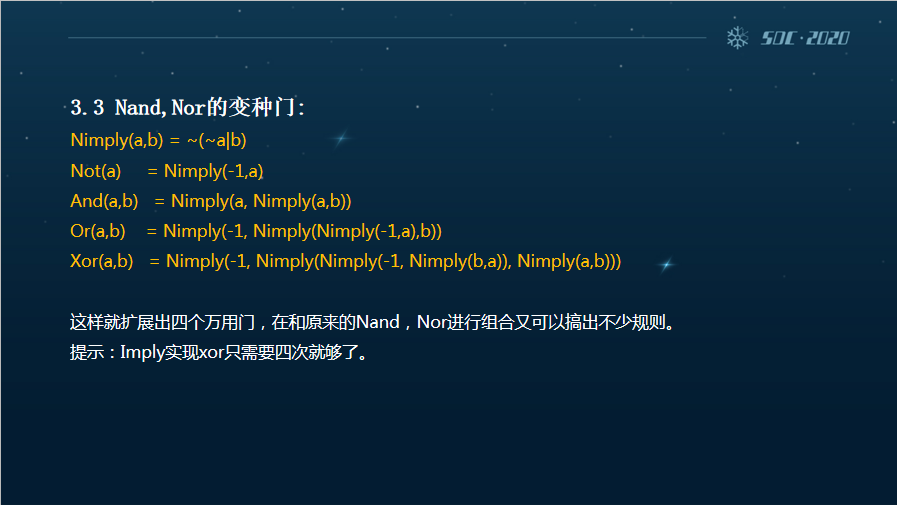
第三个方向的话,我们本身发散出来的思路是说VM Protect采用的是万用门来实现逻辑位,指令运算确实堪称一代经典。但是十几年下来有无数的插件和工具都可以直接去识别这两个门,根据《布尔代数》我们可以推导出一些功能近似的变种门,比如说Imply,Nimply,Andn,Nandn。
本身我们推导的是这样的一个顺序,在Andn其实是在x86跟x64指令当中就已经出现的,它的代码实现直接就像下面的黄色标识部分所示,直接产生了一个新的万用门。

与此对应的话,Andn反过来直接就有一个Nandn,它可以产生万用门的变种。同时有Andn,自然也有基于Nor的这样一个变种门,不过它的学名叫Imply,图上可以看到他们的代码实现。
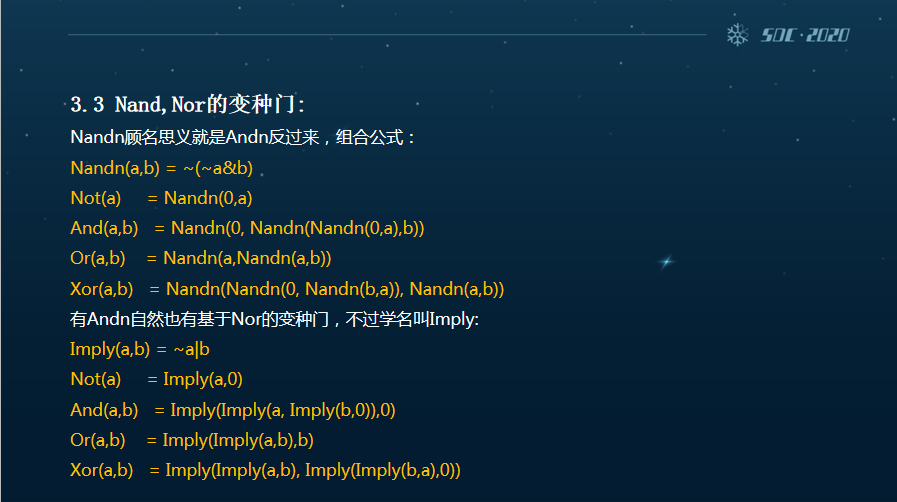
既然有Imply自然就有Nimply。它本身是Imply的一个反向变种,这样我们就扩展出了4个万用门,在和原来的Nand,Nor进行组合的同时又能搞出不少的规则。
第四个我们可以想像出来的技术,就是OISC技术(单一指令计算机)。这是一种非常极端的计算机类型,现实中基本上是不可能看到的,在少量的教科书当中是有被提到过。整个计算过程只有一个指令,根据设定好的地址和参数直接就可以进行“图灵完备”,其中经常被提到的有减法机、加法机等等。因为只有单一指令能完美地直接去模拟其它的指令,所以对于逆向来说确实是一个很具有歧义性的东西,破解难度也会增加,导致这种技术虽然看上去都很“美”,但是它的速度和体积在单一指令计算机来说确实是够呛的。
在减法机实现位操作上,往往需要上百条指令的组合。在我们模拟减法机的时候,在它变化之后其它的这些东西都是需要大量的指令。用在一些非常不在意速度的地方是可以勉强接受的,但是我们日常中在进行软件保护的过程中一般还是不使用的。
总结起来,以上我们能想到的这四个方向,基本上就是目前最流行、最有可行性的技术保护方案。除了第三种方法之外,其他的方案虽然从一定程度上解决了自动化分析工具这样一个问题,但是这仅仅只是在“无限堆甲”,在这种模式下,它的代价也令人头疼,就是慢而且体积超大。
四.“量子逻辑门”的新方向
量子力学是目前比较热门的领域,虽然传统计算机下它是没有办法直接去利用量子去进行计算的,但是在我们研究过程中发现它的一些量子理论的研究还是可以给我们很多提示和启发的。
既然讲到量子门,我简单解释一下什么是量子。经典比特与1位量子比特看上去十分类似,最大的区别就是多了一个Psi和0到1的叠加状态,就像PPT 上所展示的比特,相当于是一个磁极的SN级一样。只不过量子直接多了一个Psi本身的叠加状态作为它的控制位。

为了让这种模型更加简单,就用我做的这张图向大家直接进行展示。我们可以把量子比特的0和1想象成磁铁的两极,再加上Psi叠加状态控制位的时候,Psi就是这个磁铁的方向标签。由于“叠加”且方向相反的原因,通过组合多个量子比特我们可以得到一个m*n的矩阵,矩阵里面就是不同参数组合的计算值。基于这个原理,量子计算的并发就有了一个理论基础。这里要强调的是,我们只是基于量子的原理进行了一些在传统计算机上的模拟。
首先是可控交换门,它的作者是在1982年提出这个如今量子计算中经常用到的逻辑门的。它的原理是通过c位控制i1,i2两个数值进行比特位交换。图上是我们整理出来的真值表,当c为0的时候i1,i2不变。当c等于1的时候,i1,i2交换比特位,通过O1、O2来输出,通过这样简单的操作就可以实现万用逻辑门基础的构造。
它本身的代码实现如这张PPT所示,使用C语言可以直接构筑出来。相信大家都有一个问题,它到底能有什么用?

这是我们整理出来的它本身可以具有的相对应的算式。通过Fredkin Gate,然后它后面的参数是a,0,b的时候,可以模拟出来它的b输出,o1的输出是andn,o2的输出是andn。同样的,直接Fredkin,它的参数是a,-1,b的时候,它的o1、o2的输出是inply和or,下面以此类推。
也就是说,我们通过单一的Fredkin算法,控制它本身里面的参数,是传值参数还是控制参数的不同,它可以模拟出几乎所有不同的逻辑参数。也就是说在逆向过程中,逆向者只能看到Fredkin和它后面对应的三个参数,这个算式代表的是什么逻辑运算,只有通过上下文找到参数真实的含意才能知道,而这个东西就具备了我们所说的歧义性。
正如之前讲的,磁铁的两极是分不开的,但是我们通过调整输入参数、控制位、参数顺序,都可以去干涉我们的计算,既可以同时得到两个相反的计算结果,又可以通过简单的控制即可以产生10几种的计算结果。在这种复杂的规则作用下,分析VM Handler就不是一个简单的代码识别可以去完成的这么一个简单的事情了。
再展示另外一个Toffoli Gate。这是1980年提出的Toffoli门,也叫做控控反转门。它的原理和Fredkin不同的是,这里不是做ab参数的直接交换了,而是当c,a都为1的时候b反转输出,也就是这里我们真值表直接算出来的,在上面本身输出值c,a都有0存在的时候,后面的输出值是不变的。
但是本身c,a输入值都为1的时候,要对它后面的输出结果进行反转,黄字部分是我们做出的代码的模拟。这样子的话,它就能够实现一个反转的效果,同时我们就可以直接去模拟不同的原始逻辑运算,Xor甚至可以只通过一步运算就能够完成,其他操作的话则可以通过逻辑组合来进行实现。

简单总结一下,通过以上的讲解,大家会发现“量子逻辑门”的优势就在于其核心“歧义”。同样的计算下,根据输入参数的顺序不同,在相同的计算公式下,就像我们刚才展示的Fredkin或者是Toffoli的方法,可以直接得到不同的结果,同时这样的特性下也产生了相应的优势。
道成一,一生二,二生三,三生万物。也就是说我们团队在研究过程当中,通过研究Fredkin Gate跟Toffoli Gate之后产生了一个疑问,Fredkin Gate我们刚刚看到了,它可以模拟16种可能的运算,那万一Fredkin Gate也被直接逆向完了怎么办?
五.万物皆可万用门
通过对量子逻辑门本身的研究,我们总结出了两个方法论。第一个,想要增加复杂度,套娃就好了,不是原始的TMD里实现的直接套娃叠加,而是通过增加它的逻辑位和其他相关参数顺序本身的不同来增加它的复杂度,要基于这个思路来进行套娃。第二个就是一切看似无关的计算都能从更宏观的角度观察,它都是有规律的。
由此,我们总结出来的第一个算法是二元三输入的万用门。这是我们自己想出来的两个门,一个叫与或非门,一个叫或与非门。它的简单实现就像第一行这边,AOI(a,b,c) = ~(a|(b&c)) = ~a & ~(b & c)。但我们研究发现,在这种情况下,AOI (0,-1,a)或者AOI (0,a,-1)的情况,它可以模拟Not (a)的运算。而AOI (0,a,b),他可以模拟Nand(a)的直接这样计算,以此类推……
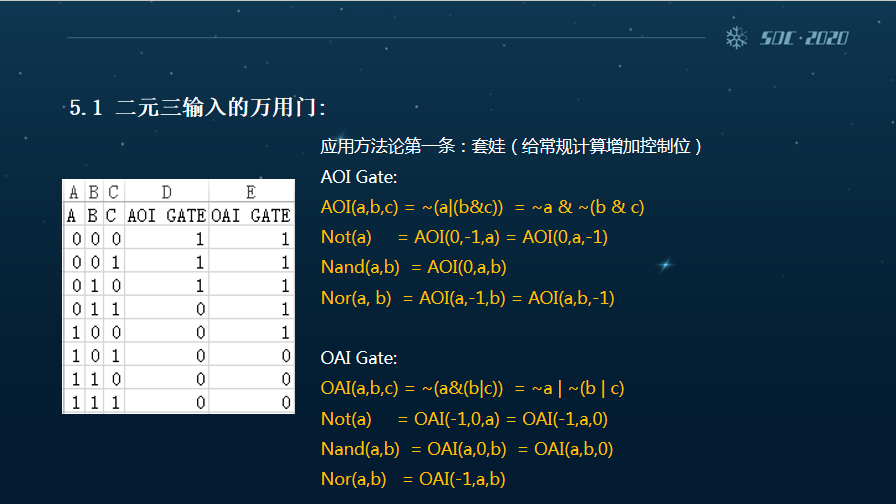
也就是说我们通过一些逻辑位套娃方式的叠加,通过加入一个类似控制位或者说加入它本身参数的不同,从而生成很多种变种的歧义。
第二个,我们受到的启发是常见的计算都可以让它转变为万用门。首先是选择器计算,比如说以我们常用的mux32为例,黄字就是目前我们自己总结出来的,通过Mux32(a,o,b)它可以模拟andn的计算,而Mux 32(a,-1,b)它可以模拟or这样的计算,以此类推……

这就产生了一个很有意思的现象,当我们用这种思路进行代码加固的时候,逆向者看到Mux 32的时候就存在一个问题,到底是用选择器的指令还是经过处理后的替代的逻辑运算指令?
在这里的话,还有其它可以用的万用门,比如说半加器、半减器、借位计算,甚至大于、小于的计算等等我们平时忽视的计算操作都可以用来实现相关的万用门。而且不同的万用门之间可以相互组合,形成无数种新的万用门,让常规的VM分析插件直接失去作用。这就是我们《孙子兵法》讲的“兵无常势,水无常形”。
六.“数学计算”与“位运算”
第一个是基于“恒等式”的替换,VMP Add中使用Add进行相关的指令替换,刚出现的时候非常让人头疼。然而16年过去了,这套规则仍然在使用。既然我们可以使用Add直接进行替换操作,为什么不可以使用sub,adc,或者是sbb进行替换操作呢?
Adc的替换规则几乎和add一模一样,唯一的区别在于计算前受CF的影响,会在add基础上再加上CF的值。最直接了当的方法是可以使用stc指令来清空CF标志,就可以实现和add一样的操作了。
Sub和Add指令是反过来的,计算规则自然也就是相反的,甚至可以直接用sub来替代cmp,就不需要复杂的合并标志位操作了,谨记下面的规则即可。

第二个我们能够想到的关于数学运算方面直接的复杂变换思路是基于分数和浮点数的计算,除了使用一些加减混合计算还有一些古老的分数技巧,就可以实现其它新的加减乘除的替代,比如说加法,Add(a,b)我们可以用a/b+ 1,然后再乘B,就能实现a+b这样的结果,以此类推。

这些是相对比较简单的替换操作,我们在这里仅仅只是抛砖引玉,甚至是基于fsin、fcos,连分数等替换可以创造一个命题生成器来直接生成非常复杂的替代规则。这种替代规则一旦生成,对于习惯于去调试“整数指令”的破解者,应该还是很有冲击性的。
第三个想到的方案,是基于量子逻辑门的加法器、减法器、乘法器和除法运算器。作为电子电路的基础知识,我们说构筑“加减乘除”运算器几乎是每个人的基本功,但是由于现实思路和代码的千差万别,所以分析起来还是比较痛苦的。这里最简单的加法器,我们直接做出了一个推演,图上左边是我们用C直接写的一个简单的原始思路的加法器,右边是直接使用我们的量子逻辑门来做的一个C方面的代码。

试想一下,这个代码发生膨胀之后会发生什么样的效果,当逆向者看到被膨胀过的代码会看到什么?除了正常的计算之外,我们还可以用到上面讲过的万用门来组合,来实现这个加法器。同理,减法器、乘法器、除法器都是可以通过直接这样的方式来进行直接实现的。之后就是发挥每个人的想象力,我们可以无限地去想象可以构筑怎样一个复杂的运算。
第四个我们能够想到的替换方案,是基于“组合恒等式”的替换方案。在有了以上几种数学计算方式之后,我们就可以通过恒等式把它进行相应的组合,来生成无数的规则。当你没有好的办法的时候,套娃就是最好的办法,像黄色代码部分,在Add(a,b)中我们可以直接把它扩散成后面非常复杂的相关计算。

规则是可以无限嵌套的,而且每一行都没办法轻易优化和删除,这里只是抛砖引玉,大家事后可以自己写一个规则生成器来实现这样的膨胀,看看效果。
前面我们讲了逻辑运算本身的变形和数字计算相关的变形。但在软件本身的加固过程中,我们经常碰到的问题是标志位的问题。不管对于VM还是代码变形,想要模拟结果都不是难事,几乎谁都可以去写几个普通的替换规则,真正直接想让变形后的代码可以百分之百运行正确的时候,我们就不能只是模拟结果,同时还要模拟标志位。
七.代码变形的核心“抗干扰标志位计算”
下面就分享一下标志位的模拟及其相关的优化。在TMD和VMP标志位与逻辑混淆方案中,TMD的处理方法比较简单粗暴,恢复标志位,执行MULC、CL等之类的代码,最后保存标志位Pop。

只有在跳转代码才使用了JCC_INSIDE, JCC_OUTSIDE, JMP_INSIDE等Handler来实现判断就导致了一个问题。TMD的VM Handler只能1:1地实现,而VMP直接在vNor,vNand,vAdd Handler中记录pushfd,然后通过自身的各种位运算重新更新到虚拟寄存器当中。既然可以直接使用vAdd来计算OF,AF,CF这些位,同样也可以设计vSub,vSbb,vAdc这类指令,直接相对应地进行直接的计算。
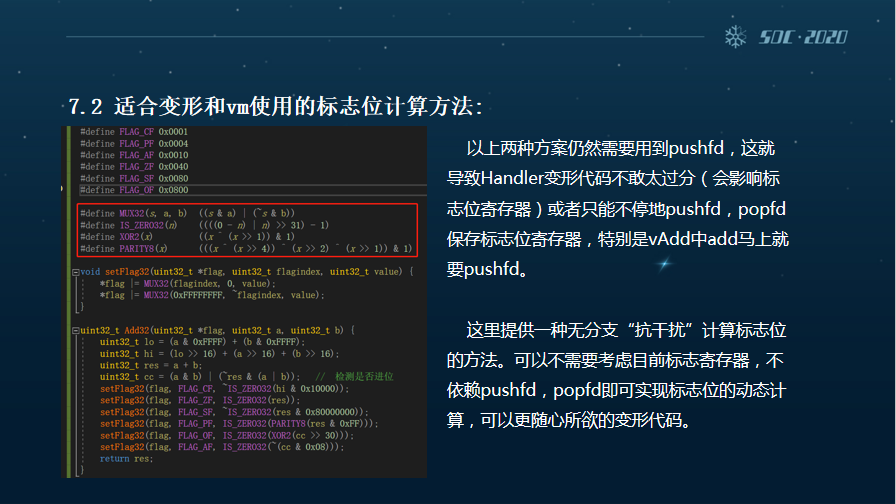
以上两种方案还是需要使用到pushfd,这就导致我们不敢把Handler的代码变形做得太过分(因为会影响标志位寄存器),要不然我们就只能不停地去push fd,popfd来保存标志位的寄存器。特别是vAdd中,add马上就要进行pushfd,这里我们提供一种无分支的“抗干扰”计算标志位的方法。
这张图是我们完整的一个实现,它可以不需要考虑目前标志寄存器,不依赖pushfd,popfd即可实现标志位的动态计算,更可以随心所欲直接去变形我们的代码。
第三个我们能想到的方案就是使用“惰性计算”进行优化和保护。由于x86、x64下标志位计算是强制的,所以即使你不需要标志位运算结果,and、or、add等指令还是计算标志位的。但是在代码的vm或变形的保护中,这就成了暴露指令。于是只针对需要标志位结果的指令才进行计算,就成了我们优化的重点。
通常需要用到标志位的指令不多,cmp,jcc,adc等之类的,也就这些指令需要用到标志位。通过反汇编分析,找到这几条指令上覆盖标志位的指令,比如说cmp+jnz这样的组合,只需要计算cmp标志位的影响就可以了,后面直接就不需要再处理了。VMP跟SE在生成某些垃圾代码的时候也会参考以下几条是不是有影响标志位的计算(and,or,add等)。如果有,VMP和SE在生成垃圾代码的时候就不需要考虑标志位的影响问题,因为它会直接覆盖上去。
八.VM架构的改进与创新
第一,动态流指令集的设计。VmOpcode虚拟指令在设计上要跟着Vm Handler走,那么VmOpcode就面临了几个问题。Vm Handler都是一个一个的case,因为它是一个个case,所以现有的指令集是可以被自动化工具所识别的。既然能被识别出来,那我们就需要对VmOpcode进行更加复杂化的处理。另外,它还存在的问题是过多的JCC(REL指令)会导致缓存刷新,CPU速度降低的问题。
基于这几个问题,我们要如何来进行处理呢?在二八定律下大部分的代码是重复的,我们将重复的代码打包成一个个Block,Block里面多个的Handler就都被合并到同一个Handler里面去了,它的优点有以下四点:第一它减少了原Handler之间频繁JCC导致CPU缓存刷新,CPU运行率降低的问题。第二原Handler的功能单一,容易被分析,现在我们把它组合起来之后,一个Block就包含了多条指令,增大了分析难度。第三点通过在Block中间增加REL指令拆断指令流,干扰自动分析框架。第四点是在指令集参数当中可以插入虚假和解密等微代码来增大分析难度。但同时它也是有缺点的,就是编译器开发难度确实比较大。
第二个我们可以执行的方向就是生成智能垃圾代码。“smart trash code”最早出现在Zombie引擎当中,引擎会随机产生“解密代码和常量”同时“模拟执行”,这些随机的代码得到执行后的结果,最后再补上一个数值,获得完整的常量数值。
图上是我们自己模拟的一个结果,这样做的好处是避免了传统的“垃圾代码生成器”产生没什么耦合性的代码,从而让一些“垃圾代码清除插件”无法被清除。后来在2013年经过pr0mix在XTG2.0多态变形引擎中的改进,增加了调用API进行加强,纯人工处理将是一件非常痛苦的事情,来增强它本身垃圾代码直接对于逆向者的干扰。

第三点我们想到的方式就是执行路径模糊与隐藏。在VMP和TMP当中,代码执行流程都是采用一个大循环或者是一个handler table来进行跳转。到了VMP 3.0时代的话,他采用直接地址寻址来实现VmHandler之间的跳转操作,虽然提高了分析难度,但是由于设计缺陷,一些分析插件还是可以直接被识别出来的。
特别是在现在,“符号执行”,“虚拟执行”等跟踪工具下面,许多内部代码的执行流程都暴露无遗。在这里的话,针对这些问题我们也提出了几种思路,在handler中间直接插入寻址指令,让handler产生割裂的效果,或者使用非正常跳转,比如说异常处理来实现跳转,而不是在原来大循环的jump当中进行跳转。又或者是使用协程切换,使用混淆树来进行寻址的碰撞,来直接进行跳转。
由于篇幅的限制,其它的思路没办法更详细地跟大家分享,在这里简单提一下,也就是说VM当中可否直接加入自校验的功能,在反调试的VmHandler上面能否直接再进行更多的处理。多态编译器算法,例如更高级的随机寄存器的分析算法,多态指令生成系统以及API的直接调用,这都是我们认为未来可以有的发展方向。
九.Iot等跨平台领域与未来的技术发展方向
我们的思考是第一,存不存在现有芯片条件下,无法被“传统逆向”方法分析的保护方案。第二,“混淆电路”,“多方验证”,“同态加密”, “虚拟黑盒安全混淆”是否可以用于代码保护方案中。第三,基于硬件PUF(物理不可复制函数)的保护方案,直接在代码当中我们要如何设计实现。第四,基于GCC和LLVM的通用多语言安全编译器系统是否可以实现。第五,能否开发出基于网络交互“零成本”的代码保护方案。
以上都是我们团队认为我们接下来需要去研究的方向,并且我们也已经有了一定的成果。再次感谢看雪论坛让我有这样的机会为大家展现我们团队研究的一些新思路,谢谢大家!
本届峰会议题回顾
2020看雪SDC议题回顾 | 逃逸IE浏览器沙箱:在野0Day漏洞利用复现
2020 看雪SDC议题回顾 | LightSpy:Mobile间谍软件的狩猎和剖析
2020 看雪SDC议题回顾 | DexVmp最新进化:流式编码
2020 看雪SDC议题回顾 | Android WebView安全攻防指南2020
2020 看雪SDC议题回顾 | 生物探针技术研究与应用
2020 看雪SDC议题回顾 | 世界知名工控厂商密码保护机制突破之旅
2020 看雪SDC议题回顾 | 敲开芯片内存保护的最后一扇“门”
……
更多议题回顾尽情期待!!
注意:关注看雪学院公众号(ikanxue)回复“SDC”,即可获得本次峰会演讲ppt!
其他议题演讲PPT,经讲师同意后会陆续放出,请大家持续关注看雪论坛及看雪学院公众号!
后续会在论坛发布关于本议题更为详细的讲解,敬请关注!

- End -

声明:该文观点仅代表作者本人,转载请注明来自看雪