2020 看雪SDC议题回顾 | DexVmp最新进化:流式编码
发布者:Editor
发布于:2020-10-28 18:31
Dex文件是代码加固的保护核心,也是App安全的核心所在。
然而目前常用的DexVmp虚拟保护技术尚存在不足之处。虚拟化后的字节码通过映射表,和系统原始字节码对应。通过逆向仍然有可能让攻击者找到映射表或者映射关系,从而还原原始指令。
为此,很有必要对现有的Dex加固方案进行革新,摆脱对系统字节码的依赖,用更完善的保护技术稳定地对Dex文件进行高效保护,才能防止App被逆向破解而泄露源码,最大限度地保障App的安全性。
下面就让我们来回顾看雪2020第四届安全开发者峰会上《 DexVmp最新进化:流式编码》的精彩内容。
演讲嘉宾

曹阳, 360加固保团队负责人,毕业于北京邮电大学。从事移动安全十年,深耕移动应用安全领域,主导研发360加固多项核心技术。擅长移动端代码保护、逆向破解和黑灰产对抗等。
目前专注于移动平台新型vmp引擎(dex、so)的研究、自动化合规检测平台搭建和基于加固的黑灰产防御技术演进。
演讲内容
以下为速记全文:
大家好,我是来自于360加固保的曹阳。今天带来我们团队最新的研究,就是流式编码。首先我会介绍一下背景知识,然后会介绍一下目前各代的Dex壳的特点和弱点,接下来是针对它DexVmp的设计和弱点进行介绍,最后会引出我们对DexVmp的改进。
一.背景知识
Dex格式的话就是我们搞安卓的小伙伴非常熟悉的,主流的Dex格式分三部分,Dex头,各种常量索引表,还有data区。从后面的分析指令就可以看到,Dex索引表在指令中主要都是通过这个值来访问它的下标,data区基本上都是通过偏移来指向。我们这次的改进方案主要是解决在指令中如何处理偏移的问题。
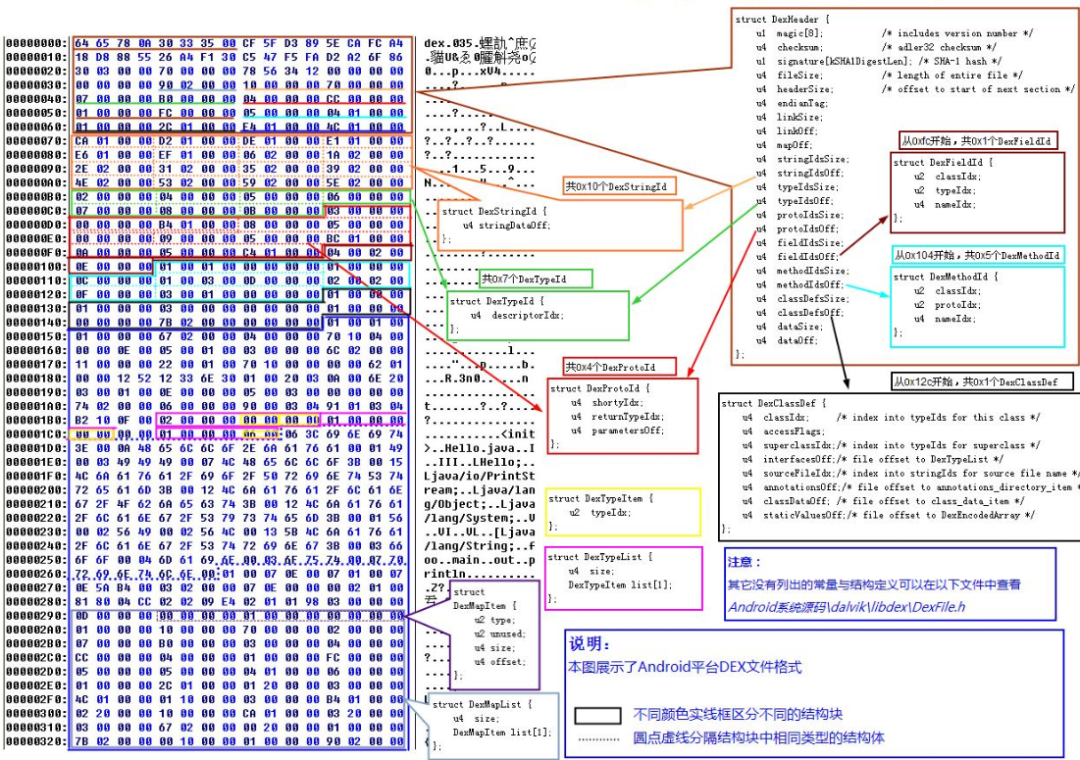
这里的展示是以二进制的形式来展示一下Dex主要的分布。我们可以看到,从中间开始都是以数组形式存在的各种索引表,指令通过检索的话就是检索这些具体的结构体。

至于Dex指令的话,这两张图是我从谷歌官网上摘抄下来的,它存储格式有16种,编码方式有32种,指令总数有256个。例如mov指令,它的编码方式是12x,对应左边这个编码方式就是B|A|op,它是按字节去倒着排列的。
举一个例子,第一个是最简单的指令move,是把v0的指令移动到v1。第二个,移动v1的内容到v0的寄存器,如果说v3等于v11的话,就跳转到x66的位置。第三条指令也是比较典型的,它会牵涉到一个对象引用,意思就是说我们会检查v1寄存器当中的对象并引用,然后去我们当时说的DexType这个表中找到相应的类型,查看是否可以转化。

二. Dex攻防演进
接下来我会介绍一下每代Dex壳的特点和弱点。先来做一个总结的话就是,加固方案在不断演进的过程中,是原生信息不断消亡的过程。
从文件粒度来看,文件加密、内存加载、格式对抗和文件打散都是不断演进的,一开始就是加密,内存加载更进了一步,就是我们在使用的时候不会生成文件,这两种方式通过内存dump都可以很轻松地绕过。而格式对抗是一些小技巧,就是会加一些无用的索引。这里面比较有效的就是文件打散,Dex在内存中,包括文件加密、加载、破解的核心都有一个前提,就是Dex在内存中一定是连续存放的。但如果说我们把它打散,即使把内存都拿下来,还需要做各种各样的拼接和重组,这种的话难度也比较高。
接下来看函数粒度的保护,函数粒度也分两种。第一种是属性伪造,之前出现过类似这种的函数保护方案,就是把它的属性进行伪装,等运行的时候再还原。第二种方法就是目前更主流的方法体抽空,包括类初始化回填、调用时回填以及永不回填。其中Dexhunter负责主动调用、内存重组;Fupk3解决主调用问题;Fart解决ART等高版本问题,并结合frida达到更精细的效果;Youpk则会深入解释器。
接下来就是指令粒度的保护,分为Dex2C、Java2C以及DexCFG。其中,Java2C的适配性是比较有问题的。Dex的控制流转化,是在控制流的粒度上做转换,其实控制流的整个逻辑是可以千变万化的,这当中也会造成一些信息的缺失,目前也有一些开源的工程,但是BUG是比较多的。
Dex2C它的核心思想和vmp是一样的,这个其实很简单,相当于我们把整个控制流都转变为更细粒度的概念:跳偏移、查引用、使用寄存器数组,可以更方便地实现指令粒度的保护。得益于此,目前也有一些比较成熟稳定的产品。但Dex2C的缺点我刚才也提过,就是加固的函数越多它的体积就越大,而且它的底层也是要通过env函数来承接的。如果说我们用vmp的话,相当于可以把所有的防御点都集中在vmp解释引擎上,可以加上更多更高级的防护。
三.DexVmp虚拟化设计
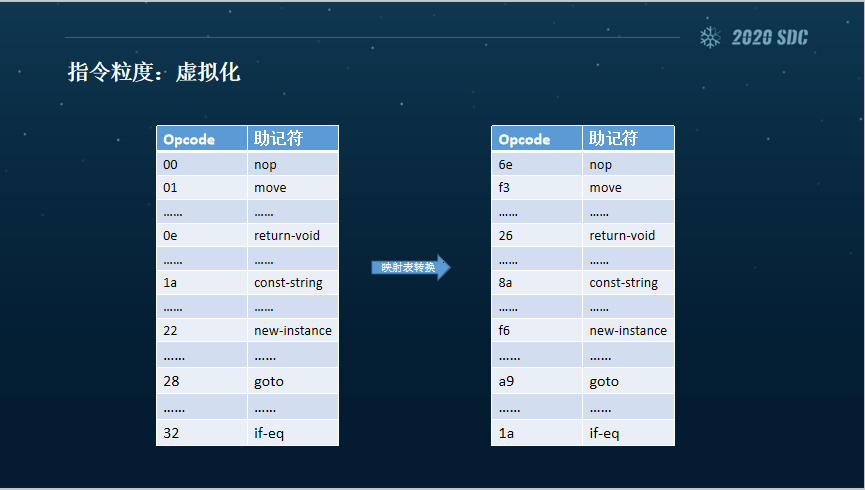
下面来说说虚拟化目前的一个核心概念,左边是系统的一个Opcode和指令,它还是要依赖系统,也不算是一个完全的vmp。核心的步骤也就是三个,取指、译码和执行。
目前的取指也是按照系统的标准,以16位长度为单位,Opcode和指令的映射其实是打散的,现在可以做到每一个版本、每一次加固,它的Opcode和指令都是不一样的。
译码的话也是256个种Opcode,其所对应的指令不同,但相同指令的译码方式和系统是相同的,所以说这里面都有很多可以破解的点。
至于执行的话就是最典型四种:索引寄存器、索引Dex中的Type、Field、String等表、16位为单元的偏移跳转以及调用函数。
接下来我会讲一下DexVmp的虚拟化设计,以及为什么它不太安全。
虽然它能防止很多自动化的破解,但还是有一些弱点的。这是一个整体流程,首先我们会把Java函数转变为Native函数,就是把函数解释所需要的信息提前准备好,并把参数同时抽取出来,分配一个当前函数所需的解释寄存器的数组,还会有一些信息,例如代码、名称等等。如果解释器准备好了,我们就会进入循环的操作,取指、译码、执行。在译码这块,最典型的就是译引用,不管是对Dex这种常量索引表进行解析还是去调用JNI函数,最终它的出口其实都是JNI函数。
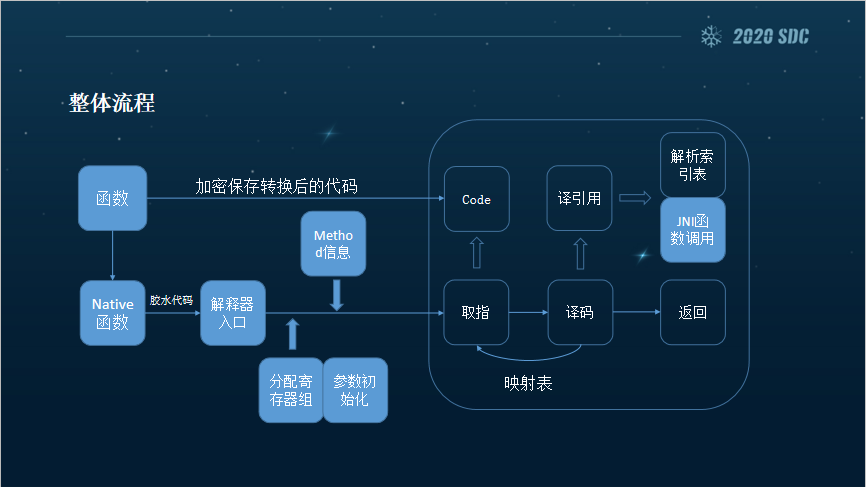
这里我把译码分成三类,寄存器、引用和偏移。寄存器的话在指令中是以idx值存在的,在寄存器数组中检索。每个函数它的寄存器数组的数量都是提前定好的,个数为registerSize。引用中指令也是以idx值存在的,在IDs数组中去检索,解析Dex结构,找到相应信息,为初始化jclass/jfieldId等做准备。最难的是偏移,在指令中它是以常量存在的,而且是按2字节为基本单位的,在Dex指令中的IF、Switch、Go流程等等中,都会涉及到偏移的操作。
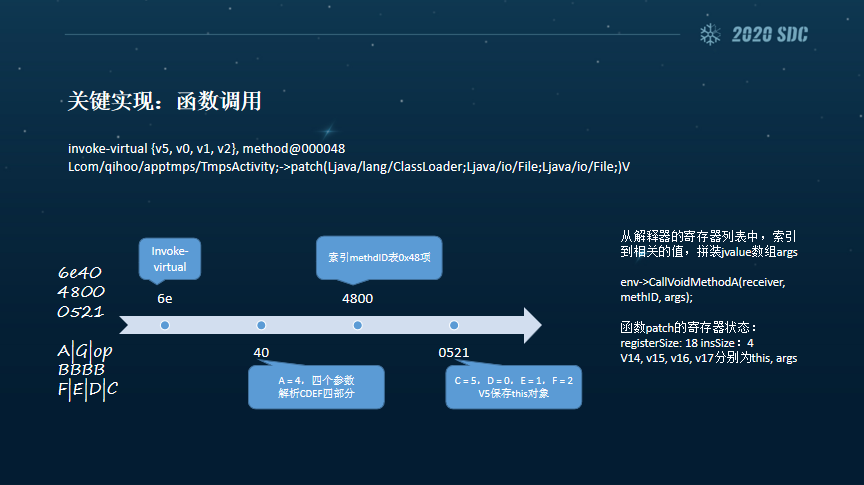
接下来就是一些译码的方式,首先看函数调用,这个函数需要4个参数,0521就是当前的v5、v0、v1、v2,来表示指针和函数所需要调用的值。解释到这块指令的时候,核心的操作就是首先找到相应的表和对应的类,把其读出来,然后通过一些流程对其进行调用。如果我们调用的这个函数也是被虚拟化的呢?同样在解释器的入口也要把一些东西准备好。
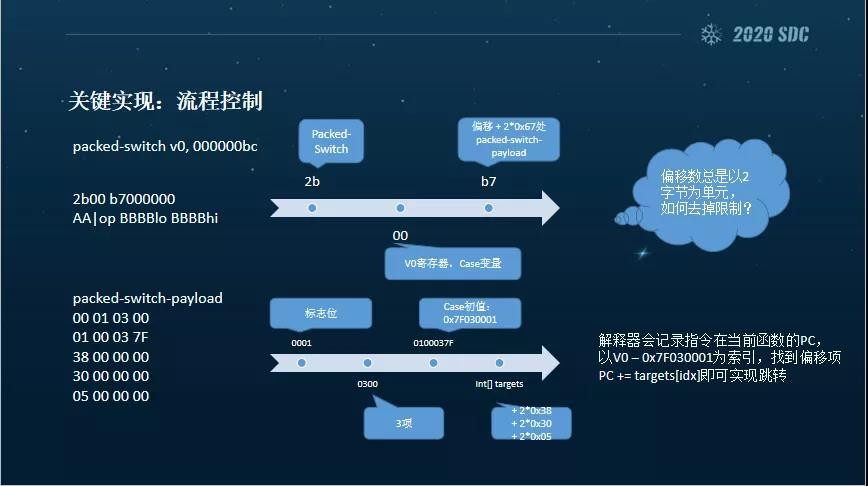
下面我们再来看流程控制。这个是switch指令,这里我主要说说偏移是怎么回事。首先00代表的是V0寄存器,变量值要从V0寄存器当中找,以其为索引,在数组中找到偏移,再用当前的PC加上这个偏移,就会跳转到相应的地方,再继续取指、译码、解释等等。
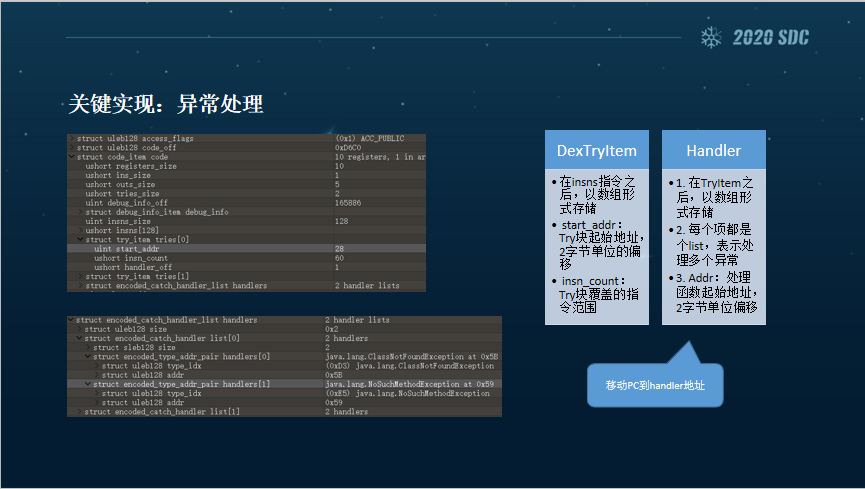
异常处理这块的话,也是比较典型的,首先我们针对大部分指令的话,在解释之后都会检查当前是不是发生了异常。如果发生了异常,我们就会记录当前的PC,然后遍历DexTry数组,找到某一个块的Handler。找到之后会记录,跳过去继续执行流程。如果没有找到的话,就会把这个异常抛出来。
这个是在Dex异常的一个结构,首先DexTry是放在insns指令之后,以数组形式存储的,最重要的是,它Try块对应的Handler发生之后怎么去处理。
Handler的每一项都是一个数组,可以表示处理多个异常,如果说捕获到相应的异常的话,就会到对应的地址,我们就会把PC移动到这块继续来处理。
上面是几个典型译码的过程,其实通过我们刚才的分析可以看到它主要有以下几个核心缺点。第一个就是它存放缓存代码、引用等很多都要依赖Dex结构,例如解析DexTry等等。第二个就是映射关系,它是要依赖于系统的操纵码来实现整个的运行的。最后就是Opcode、寄存器、引用等等,它的编码长度都是固定的。
这些其实都是很多破解者依赖的信息,所以我们如何能把所有的这些缺点给克服呢?
核心就是我们要能够自己定义操作码,不依赖Dex,不依赖系统,自己定义操纵码之后,Opcode等等这些都是可以自定义的。
四.改进与展望
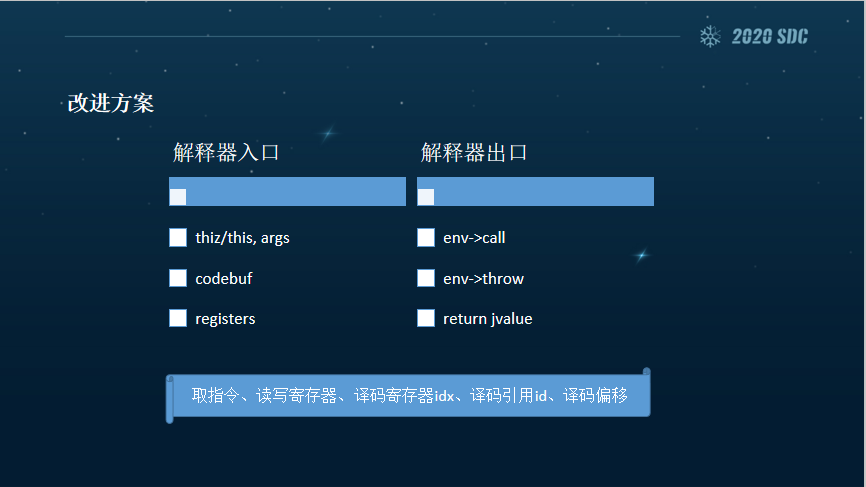
在解释器、入口出口都准备好之后,中间的这部分过程都是我们可以自己控制的,例如取指令、读写寄存器、译码寄存器idx、译码引用id、译码偏移。如果说把指令给改了的话,偏移是最难处理的一块。
首先取指令的话,因为取指令是我们解释器自己控制的,opcode无固定长度,可以自定义变长指令,跟系统指令无映射。
读写寄存器我们也是自己控制,因为寄存器数组都是我们分配的。
译码寄存器idx的话,因为每个函数它的寄存器最多也就是registerSize个数,最高的编码位数16位,基本不需要那么多位数的编码。所以在指令中,idx没必要按照系统编码,只用于内部解释。
译码引用的话涉及到我们会去查找系统当中的String表等等,查找也是我们自己查找的,没必要一定要去Dex这个结构中去查找。我们把要虚拟化的字节数据流已经扣出来了,相关的结构都可以自己去设计,自己查找并按照自己的设计原则,怎么方便怎么来。
但影响最大的是译码偏移这块。我们刚才也看到了,在真正跳转的过程中,它其实是一个硬编码,会跳转到以当前PC为基准的某个偏移,或者直接跳转到相应的地址做一个偏移。

怎么处理偏移呢?左边这块是Dex所有受偏移影响的指令,包括goto还有流程控制、异常处理等等。以goto为例,这里有一个内定前提,偏移必定不会截断指令。如果我们跳转到某一个地址,这个地址不会跳转到指令中间,这个也是正常的。
所以说在这个大前提下,我们可以把偏移转变为数组项的索引。当我解释的时候,我其实会预先把当前要解释函数的所有指令都读进来,每一个指令都是有它自己的译码方式的,虽然是变长,但是从逻辑上我会把这些指令都放在一个数组中,跳转也就自然而然地转变成我要跳转到哪一条指令。
之前的话可能就是地址,转化之后其实就是我要向后或者向前移动多少条指令。这条解决之后,我们的变长问题就解决了。
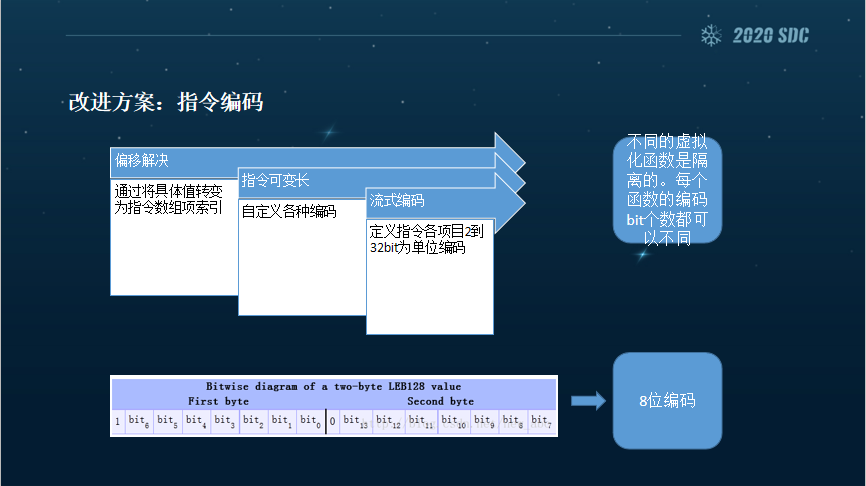
解决变长问题之后,可以自定义各种各样的编码。这块我们实现的就是流式编码,所谓流式编码安卓这边有一个比较典型的8位的流式编码,这块就相当于它会把它要编码的信息分散到七个bit字节当中。
我们设计这种编码主要是因为它比较方便、灵活,可以用多种位数编码。另外,刚才我也提过虚拟函数是有入口和出口的。由于每个虚拟化的函数在逻辑上是隔离的,所以说这样就可以达到每一个虚拟化函数编码的bit个数都是不同的。

总结一下刚才我说的改进方案。首先我们的指令是转化了原先的指令,指令肯定是变长的。其次,指令的编码是不固定的,每个版本不同,不同版本的函数也不同。另外,不会再用Dex容器去存储相关的缓存代码和相关的常量池,也不会再用相关的这类结构,因为这些都是公开的。最后,指令Opcode对应的Handler也是不固定的,如果有感兴趣的小伙伴可以加微信要样本,谢谢大家!
本届峰会议题回顾
2020看雪SDC议题回顾 | 逃逸IE浏览器沙箱:在野0Day漏洞利用复现
2020 看雪SDC议题回顾 | LightSpy:Mobile间谍软件的狩猎和剖析
……
更多议题回顾尽情期待!!
注意:关注看雪学院公众号(ikanxue)回复“SDC”,即可获得本次峰会演讲ppt!
其他议题演讲PPT,经讲师同意后会陆续放出,请大家持续关注看雪论坛及看雪学院公众号!

- End -
声明:该文观点仅代表作者本人,转载请注明来自看雪