Linux内核笔记009 - 中断、异常、陷阱、Bottom half、信号
记得刚学习C语言时,只要找个包含if语句的程序,然后通过理解整个程序执行到这条语句时,发生了什么,自然就明白if语句的作用了。同样,为了理解"中断"的含义,我特别建议站在可以看见整个系统的角度,去看出现中断时,整个系统这个"大程序"是如何执行的。
时钟中断(硬件触发,对于软件是被动的)、异常(软件缺页、除0bug等情况无意触发)、陷阱(软件显式执行int指令触发)出现时,都会穿过一道"门",跳转到内核在"门"中设置的指令地址处执行,所以它们本质上和执行jmp、call、rte等跳转指令一样,都是打断"大程序"的顺序执行,跳转到指定的指令处执行,只不过在跳转前,CPU硬件层还会做一些额外的操作。
中断、异常、陷阱相互之间,只在两点上稍有区别(根据本篇笔记稍后的内容,可以明白为什么需要这些区别):
① 紧接着中断的发生,硬件层是否关闭该类型的中断;
② 穿过"门"的时候,CPL/RPL权限检查的逻辑。

2. 外设通用中断(使用中断门)
- 中断过程分析

BUILD_COMMON_IRQ() // 展开得到:common_interrupt代码块定义(见[code3]) // ③ 展开得到16个代码块的定义:IRQ0x00_interrupt~IRQ0x0f_interrupt(见[code2]) #define BI(x,y) \ BUILD_IRQ(x##y) // ② 展开得到:BUILD_IRQ(0x00)~BUILD_RIQ(0x0f) #define BUILD_16_IRQS(x) \ BI(x,0) BI(x,1) BI(x,2) BI(x,3) \ BI(x,4) BI(x,5) BI(x,6) BI(x,7) \ BI(x,8) BI(x,9) BI(x,a) BI(x,b) \ BI(x,c) BI(x,d) BI(x,e) BI(x,f) // ① 展开得到:BI(0x0,0)~BI(0x,f) /* * ISA PIC or low IO-APIC triggered (INTA-cycle or APIC) interrupts: * (these are usually mapped to vectors 0x20-0x2f) */ BUILD_16_IRQS(0x0)
// 所有的IRQ0xXX_interrupt,都将(xx-256)压入栈中,然后跳转到common_interrupt处执行 #define BUILD_IRQ(nr) \ asmlinkage void IRQ_NAME(nr); \ __asm__( \ "\n"__ALIGN_STR"\n" \ SYMBOL_NAME_STR(IRQ) #nr "_interrupt:\n\t" \ "pushl $"#nr"-256\n\t" \ "jmp common_interrupt");
/* * ① SAVE_ALL:向栈中压入一个struct pt_regs结构数据 * ② pushl $ret_from_intr,向栈中压入ret_from_intr指令地址 * ③ jmp到do_IRQ()函数,注意不是call,所以步骤②压入的指令地址,对于do_IRQ()函数来说,是返回地址 !! * do_IRQ()函数原型:asmlinkage unsigned int do_IRQ(struct pt_regs regs),注意参数类型是一个完整的结构,而不是指针,所以正好是步骤①压入参数 !! */ #define BUILD_COMMON_IRQ() \ asmlinkage void call_do_IRQ(void); \ __asm__( \ "\n" __ALIGN_STR"\n" \ "common_interrupt:\n\t" \ SAVE_ALL \ "pushl $ret_from_intr\n\t" \ SYMBOL_NAME_STR(call_do_IRQ)":\n\t" \ "jmp "SYMBOL_NAME_STR(do_IRQ));
根据[code1]、[code2]、[code3]三处代码,可归纳中断发生时的跳转过程:
IRQ0x00_interrupt // 代码块 |- jmp common_interrupt // 代码块 |- jmp do_IRQ() // 函数

进入do_IRQ()函数后,根据IRQ0xXX_interrupt向栈的ORIG_EAX位置压入的通用中断号,并遍历执行irq_desc[regs.orig_eax].action链表中的函数:
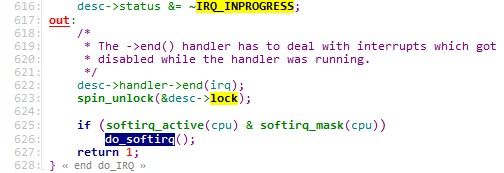
do_IRQ() |- irq = regs.orig_eax & 0xff |- spin_lock(&desc->lock) |- IRQ_INPROGRESS |- for(;;) | |- IRQ_PENDING | |- handle_IRQ_event() |- do_softirq()

③ handle_IRQ_event()函数开中断执行
EFLAGS寄存器并不能精确控制每道"门"的开关,只能通过一个"I"标志位,整体打开/关闭所有"门",所以从CPU穿过某道中断门到再次将"I"标志位置1期间,任何中断源发送的中断信号,都会丢失,虽然中断源没有收到CPU的响应信号,一般会再次发送,Linux内核还是通过软件层的设计,尽量缓解中断信号的丢失。其实,不同irq_desc[X].action链表中的函数,既然是处理不同的外设中断,所以访问的资源一般是相互独立的,很少会出现竞争的情况,所以Linux内核将是否允许重入handle_IRQ_event()(即正在该函数内部执行时接收到中断信号,又要重新从IRQ0xXX_interrupt开始,执行到该函数),留给action开发者选择。
比如,如果开发者可以保证,irq_desc[0x00].action链表上的函数,与其它action链表上的函数,不存在资源竞争,那么,就可以通过设置actions->flags的SA_INTERRUPT标志,让handle_IRQ_event()函数在入口处执行sti指令,快速恢复当前CPU的中断功能。这样,由于do_IRQ()在调用handle_IRQ_event()前,执行了unlock,所以再次进入do_IRQ(),不会发生死锁;另外,由于没有资源竞争,所以交叉执行也不会有任何问题(irq_desc[0x00].action未执行完 -> 执行irq_desc[0x01].action -> 根据中断时保存的现场,恢复执行irq_desc[0x00].action)。

还有另外一种场景:CPU正在执行0号通用中断的处理函数,这时又产生了0号通用中断。其实,这就跟多CPU同时执行同一中断通道的场景相同, handle_IRQ_event()会被IRQ_INPROGRESS、IRQ_PENDING"串行化"执行,所以也没有问题:

可以看出,选择中断门和使用"串行化"设计,对外设中断进行管理,大大减小了action开发者的负担,相应也减少了产生bug的根源。
- Bottom Half
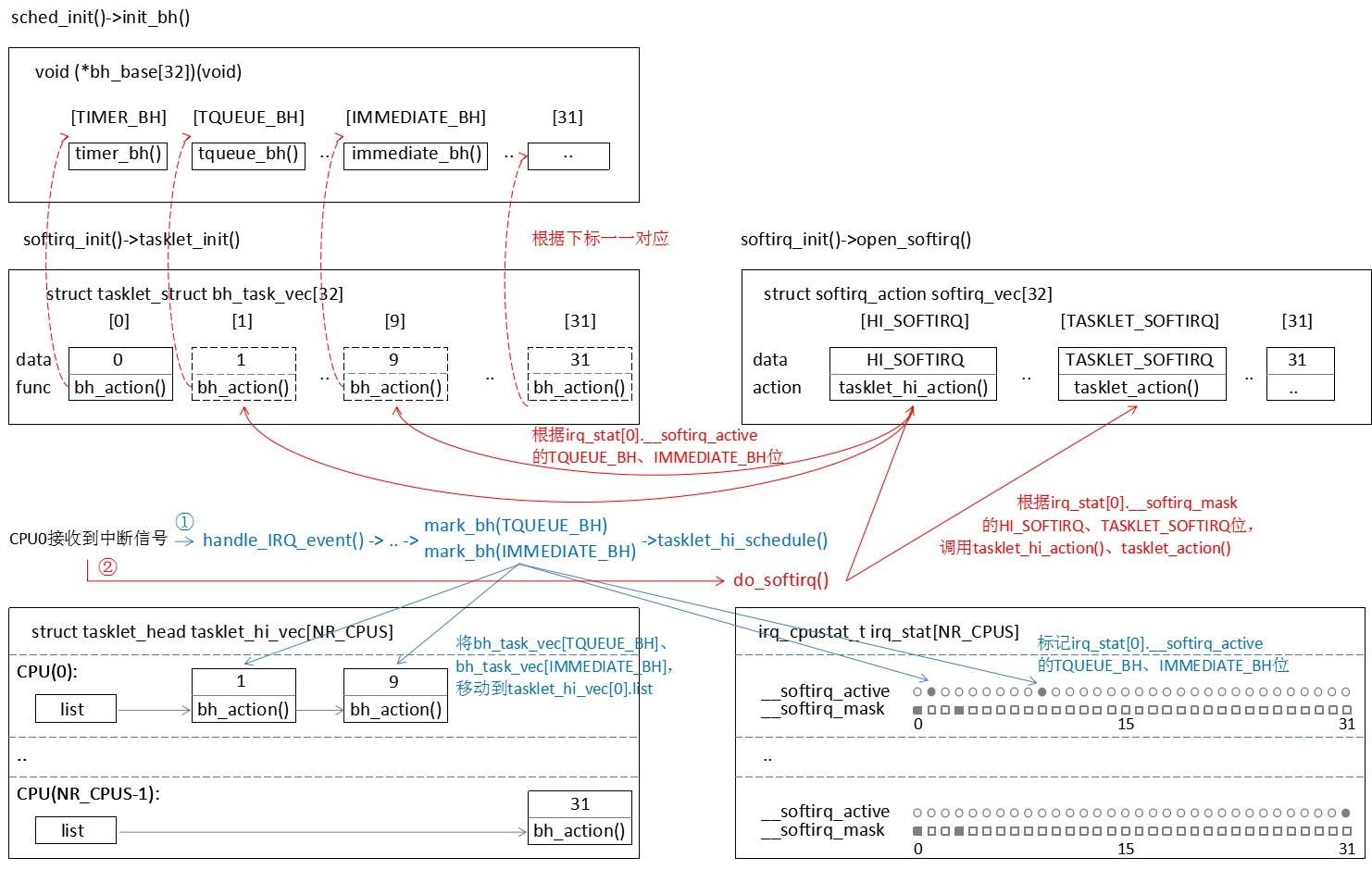
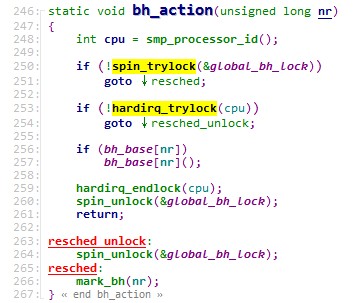
softirq_init() |- tasklet_init() // 初始化bh_task_vec[32],func成员都指向bh_action() |- open_softirq() // 初始化softirq_vec[32] |- softirq_vec[HI_SOFTIRQ].action = tasklet_hi_action() // HI_SOFTIRQ用于兼容老的bottom hafl机制 |- softirq_vec[TASKLET_SOFTIRQ].action = tasklet_action() // TASKLET_SOFTIRQ用于新扩展的bottom hafl机制 |- irq_stat[所有CPU].__softirq_mask的HI_SOFTIRQ、TASKLET_SOFTIRQ位置1,从而每次执行do_softirq()时,就会调用tasklet_hi_action()、tasklet_action() sched_init() // 别的模块也会根据需要注册其它bh函数 |- init_bh(TIMER_BH, timer_bh) |- init_bh(TQUEUE_BH, tqueue_bh) |- init_bh(IMMEDIATE_BH, immediate_bh)
信号
3. 缺页异常(使用陷阱门,DPL为0)
跟IRQ0xXX_interrupt类型,直接看代码。
arch/i386/kernel/entry.S,410~412:
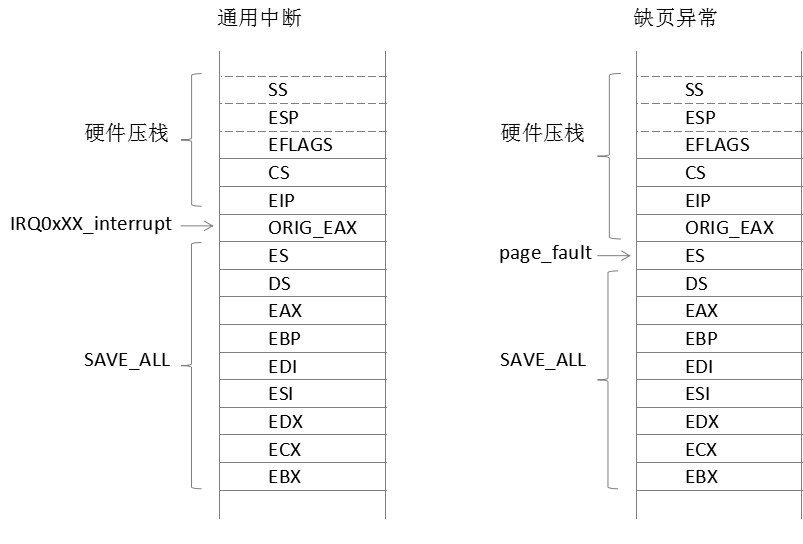
ENTRY(page_fault) pushl $ SYMBOL_NAME(do_page_fault) jmp error_code
error_code: pushl %ds pushl %eax xorl %eax,%eax pushl %ebp pushl %edi pushl %esi pushl %edx decl %eax # eax = -1 pushl %ecx pushl %ebx cld movl %es,%ecx movl ORIG_EAX(%esp), %esi # get the error code(硬件自动压入) movl ES(%esp), %edi # get the function address(执行page_fault时压入) movl %eax, ORIG_EAX(%esp) movl %ecx, ES(%esp) movl %esp,%edx pushl %esi # push the error code(do_page_fault()的error_code参数) pushl %edx # push the pt_regs pointer(do_page_fault()的regs参数) movl $(__KERNEL_DS),%edx movl %edx,%ds movl %edx,%es GET_CURRENT(%ebx) call *%edi # 调用do_page_fault() addl $8,%esp jmp ret_from_exception
ENTRY(coprocessor_error) pushl $0 pushl $ SYMBOL_NAME(do_coprocessor_error) jmp error_code
void do_page_fault(struct pt_regs *regs, unsigned long error_code)
time_init() // arch/i386/kernel/time.c, 626~706
|- setup_irq(0, &irq0) // 向irq_desc[0]注册action
// arch/i386/kernel/time.c, 547
static struct irqaction irq0 = { timer_interrupt, SA_INTERRUPT, 0, "timer", NULL, NULL};5. 系统调用(使用陷阱门,DPL为3)
跟CPU异常一样,系统调用也是用陷阱门实现:
static void __init set_trap_gate(unsigned int n, void *addr)
{
_set_gate(idt_table+n,15,0,addr); // 15: D:1,type:111(陷阱门),DPL: 0
}
static void __init set_system_gate(unsigned int n, void *addr)
{
_set_gate(idt_table+n,15,3,addr); // 15: D:1,type:111(陷阱门),DPL: 3
}// int sethostname(cost char *name, size_t len); 00000000 <sethostname>: 0: 89 da mov %ebx,%edx 2: 8b 4c 24 08 mov 0x8(%esp,1),%ecx # len 参数 6: 8b 5c 24 04 mov 0x4(%esp,1),%ebx # name参数 a: b8 4a 00 00 00 mov $0x4a,%eax # sethostname()函数对应的系统调用号 f: cd 80 int $0x80 11: 89 d3 mov %edx,%ebx 13: 3d 01 f0 ff ff cmp $0xfffff001,%eax # eax寄存器为内核接口的返回值,负数表示出错 18: 0f 83 fc ff ff ff jae 1a <sethostname+0x1a> # 重定位后,为__syscall_error()函数地址(将exa绝对值保存到errno,并将eax修改为-1,表示向上层程序返回-1) 1e: c3 ret
ENTRY(system_call) pushl %eax # save orig_eax,将eax寄存器中的系统调用号,压入系统栈的ORIG_EAX位置(终于看到这个名称的来历,外设中断时保存中断号,异常时保存错误码) SAVE_ALL # SAVE_ALL最后压入栈中的ecx、ebx,正好为long sys_sethostname(char *name, int len)的参数,跟外设中断和异常的处理函数不同,参数不再是struct pt_regs结构 GET_CURRENT(%ebx) # 将当前进程的task_struct管理结构的地址,保存到ebx寄存器(第四章) cmpl $(NR_syscalls),%eax jae badsys testb $0x02,tsk_ptrace(%ebx) # PT_TRACESYS,如果当前进程被strace调试工具跟踪,跳转到tracesys()执行(暂不关心) jne tracesys call *SYMBOL_NAME(sys_call_table)(,%eax,4) # 跳转到系统调用号对应的函数执行,即sys_sethostname() movl %eax,EAX(%esp) # save the return value ENTRY(ret_from_sys_call) #ifdef CONFIG_SMP movl processor(%ebx),%eax shll $CONFIG_X86_L1_CACHE_SHIFT,%eax movl SYMBOL_NAME(irq_stat)(,%eax),%ecx # softirq_active testl SYMBOL_NAME(irq_stat)+4(,%eax),%ecx # softirq_mask #else movl SYMBOL_NAME(irq_stat),%ecx # softirq_active testl SYMBOL_NAME(irq_stat)+4,%ecx # softirq_mask #endif jne handle_softirq ################# 以下部分,暂时了解即可 ################# ret_with_reschedule: cmpl $0,need_resched(%ebx) jne reschedule # 进程调度(第四章) cmpl $0,sigpending(%ebx) jne signal_return # 信号(第六章) restore_all: RESTORE_ALL ALIGN signal_return: sti # we can get here from an interrupt handler testl $(VM_MASK),EFLAGS(%esp) movl %esp,%eax jne v86_signal_return xorl %edx,%edx call SYMBOL_NAME(do_signal) # 执行应用程序中的信号处理函数 jmp restore_all
sys_sethostname() |- copy_from_user() // 将主机名修改到内核空间,从而所有进程可以看到新的主机名 |- .. |- __copy_user_zeroing() // 汇编代码,建议仔细品一品

// do_page_fault()函数片段
no_context:
/* Are we prepared to handle this kernel fault? */
if ((fixup = search_exception_table(regs->eip)) != 0) { // 在"异常表"中,查找导致异常的那条指令的地址(__copy_user_zeroing()的后面部分代码,就是向该表中加入"出错指令地址-修复地址"对应关系)
regs->eip = fixup; // 如果找到了,修改异常进程的eip,让它跳转到修复地址执行(否则回到原指令,又会触发缺页异常)
return;
}
...
do_sigbus:
...
/* Kernel mode? Handle exceptions or die */
if (!(error_code & 4)) // 在内核态发生的缺页异常
goto no_context;
return;