腾讯安全威胁情报中心“明厨亮灶”工程:自动化恶意域名检测揭秘
00
导语
构建恶意域名检测引擎,对海量域名进行自动化检测并识别出恶意域名,让威胁情报的检测和运营变得更智能、更高效,以缓解威胁情报分析师分面对海量威胁数据的分析压力。
01
应用背景
随着互联网体量的急剧增大,基于网络访问的各种网络攻击、木马、蠕虫等威胁潜藏在海量的网络事件中,这让专注情报分析的威胁情报分析师不堪重负,而如果能通过自动化的威胁感知和检测技术,实现从海量数据中自动发现和检测威胁,将能够有效减轻威胁情报分析师运营负担,并极大增强威胁情报检测和运营的效率。
其中,恶意域名情报是威胁情报的重要组成部分,包括恶意域名检测(Malicious Domains Detection)[1]、域名生成算法识别(DGA Recognition)[2]等。相比于一般的文本、图像等算法任务,安全领域的恶意域名检测受困于缺乏可靠的评测数据,当前并没有出现突破性且可复现的学术进展。
得益于腾讯安全在网络安全领域海量数据积累和众多网络安全领域专家,使得恶意域名检测的自动化实现,有了充实的数据和专家知识基础。
本文所述的恶意域名检测引擎 (Malicious Domain Detection Engine, MDDE) ,实现了对恶意域名的自动检测,并为威胁情报智能化检测和运营提高了效率。
02
概述
人工判定域名黑白灰对专家能力和经验要求比较高,如下图是腾讯高级威胁追溯系统-安图,对一个可疑域名的展示结果:

MDDE的核心功能是判断一个域名是否为恶意。MDDE的核心组件是基于监督学习得到的三分类机器学习模型MDDE-core,它将一个域名判定为黑白灰三种类型。此外,针对具体的业务和任务(开源情报评估、白名单生产等),引擎提供基于不同策略的接口,MDDE整体架构如下。
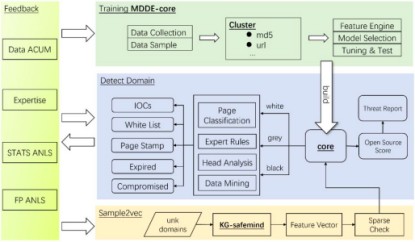
引擎的构建,主要分为四个部分:MDDE-core建模、基于腾讯安全大脑的域名样本实时向量化、域名威胁检测和反馈优化。下面逐一进行介绍。
03
MDDE-core建模
MDDE-core是检测域名黑白灰属性的三分类机器学习模型,本文会对建模过程中,有价值的细节进行详述。
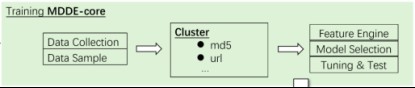
3.1 数据收集与抽样
MDDE-core是一个三分类模型,在标注数据的获取阶段,需要获取黑白灰三类域名标注数据。
白域名数据,是从自有域名白名单情报中抽样获取的。这里简单介绍一下,域名白名单情报的构建。在威胁情报知识体系的构建中,白域名是高广且提供合法正常互联网服务的站点,如 qq.com。现有域名白名单情报的构建是通过在Alexa top1m、Umbrella top1m等数据上经过分析挖掘等得到的,这里很重要的一点就是,如Alexa top1m这样的名单中,依然存在恶意站点,如piz7ohhujogi[.]com[7]。所以,公开的高广域名依然需要进一步挖掘。
黑灰域名标注数据来源于安全分析专家对可疑域名数据的人工鉴定。通过对安全事件、威胁访问等数据进行规则挖掘,得到了大量潜在恶意的域名,安全专家通过对这些恶意域名进行溯源、分析,来判定这些域名是否为恶意域名,在MDDE-core的建模过程中,选取了这些人工鉴定的恶意域名作为黑,非恶意的域名作为灰。
同时,通过对恶意域名的结构进行分析发现,一些属于同一二级域名的子域名往往从事一些相似的威胁活动,为了避免同类型域名数据的冗余导致模型过拟合,在黑域名标注数据的构建中,在同一二级域名上,随机抽取固定量的子域名作为黑域名。
通过以上收集与抽样,构建的黑白灰标注数据,基本覆盖了预测场景中的待测域名类型。
3.2 原始特征数据获取
机器学习任务的上限是特征,特征的基础便是数据类型的丰富度。受益于腾讯海量安全数据的积累,恶意域名的溯源和分析有了充足的背景知识和数据集成平台,这为MDDE-core的构建提供了两个维度的准备,一是丰富的样本特征,如DNS、URL等数据,让威胁鉴定有了充足的上下文,一是充分覆盖了各个领域、各种类型的域名,让威胁难逃检测之网。这里所涉及到的具体数据由训练所用特征决定,通过在数据平台对原始数据进行收集、整合,MDDE-core实际特征构造所涉及的实时数据量,已达数千亿级别。
3.3 特征与建模
MDDE-core实际建模所使用的到的特征,总共有四种类型:域名字符特征、样本关联特征、域名属性特征、网络访问特征。具体建模特征如下表。
域名字符特征
这一类特征源于DGA的识别,目前,由DGA构造的域名一般为恶意域名。此外,根据具体黑域名特点,构造了如子域名是否为数字这样的特征。
每种特征的具体含义如下:
》域名字符熵,域名字符串的字符熵做特征值;
》域名字符长度;
》域名级别,从3级域名起始到6级域名为止,6级以上映射为同一值,并做dummy variable转换;
》域名数字数量,数字字符数量及占比;
》特殊字符数量及占比;
》字符类型变换次数,数字序列、字母蓄力、特殊字符序列转换次数;
》最长非顶级域名长度及占比;
》数字子域名数量及占比,如 f(22.1867.jp)=2;
》成词子域名数量及占比,如f(red.com)=1;
》是否是邮箱前缀,f(mail.qq.com)=1;
》黑灰白顶级域名,统计训练数据 黑:(白+灰)顶级域名的分布,得到纯黑顶级域名集、纯白顶级域名集、偏白顶级域名集、偏黑顶级域名集、相近顶级域名集,判断每个与的顶级域名属于哪个集合,OOV作为相近顶级域名集;
样本关联特征
这里的样本指代软件样本,一个黑域名往往与一个黑样本存在密切通信,详情如下:
》黑白灰样本访问域名,访问域名的黑白灰软件样本的数量及占比;
》传播黑白灰样本,黑白灰样本从域名传播的数量及占比;
》黑白灰样本包含域名,包含域名的黑白灰样本数量及占比;
》互联网访问,互联网访问域名的数据及占比。
域名属性特征:
》黑白URL数量及占比;
》黑白IP,黑白IP数量及占比;
》注册国别,是否为东欧等;
》whois保护,是否开启whois保护;
》备案,是否有备案信息;
》注册邮箱关联,注册邮箱关联域名的数量;
》注册者关联,注册者关联域名数量;
》注册电话关联,注册电话关联域名数量;
》cname,cname数量。
网络访问特征:
构造以天为单位的域名访问量两周序列,计算最大值、最小值、方差。
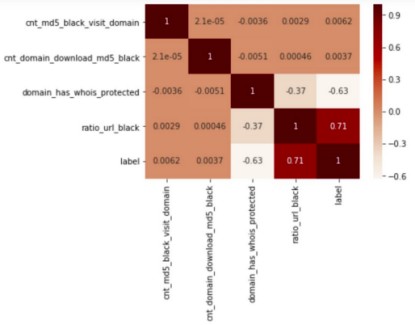
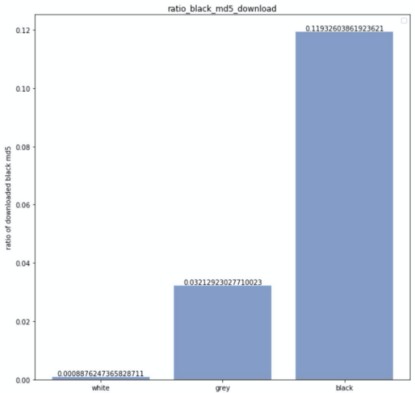
以上便是经过充分的特征分析实验后,实际用于建模的特征。最终特征集的确立,基于特征选择、变换等方式经过了反复的迭代实验而得到。如下图是部分特征与类别的皮尔逊相关系数,从中可以看出,是否开启whois保护和其黑url比例是类别的两个强关联特征。
模型的选择中,考虑到数据倾斜的影响,在对比了多种模型的验证结果后,使用kNN(sklearn)、random forest(sklearn)和gradient boosting(microsoft)进行hard vote的建模策略。最终测试结果中,三类别准确率为0.92933,详细结果如下。

由上表可以看出,黑白域名的精确和召回偏高,而灰域名的F1为0.86796,呈现出的特点是两头高,中间低的特点,这为MDDE的后处理策略,提供了思路。
04
实时域名向量化
在第3节中,建模用的域名会在数据平台上获取相关特征的原始数据,然后传输到关系数据库,再通过开发机进行试验编码,但在实际的安全分析和运维中,需要对当时遇到的域名进行实时的评估分析,但从集群平台到本地,或者输入域名到集群,在集群上搭建域名检测流程,都会有比较强的滞后。
为了能够对域名进行快速的分析评估,MDDE基于腾讯安全大脑实现了域名样本的实时向量化。
腾讯安全大脑基于S2Graph构建的图数据库,已支持超200亿节点、1600亿边的安全知识图谱。安全大脑提供的图计算和图查询功能,让MDDE实现了对域名的实时检测。

此外,即使拥有海量域名相关的数据,但依然会存在现有部分特征数据没有覆盖到某些待测域名,因为对于一个域名特征向量,会通过以下规则来判定样本是否稀疏:
Not Sparse if md5_visit > 0 & cnt_resolved > 0 & user_visit >0 last week
即当过去一周,该域名被样本访问、被解析且被浏览过时,认为样本特征不稀疏,可以输入MDDE-core进行检测。
05
域名威胁检测
在获得有效的域名特征向量后,MDDE-core会对域名进行威胁检测,并对不同的检测结果,结合相关上下文,通过网页分类、头部分析、专家规则、数据挖掘来进行不同层面和维度的判定。

5.1 IOC检测
域名IOC主要来源于MDDE-core检测为黑的域名。MDDE-core判为黑的域名进一步通过网页分类模型来判定其是否为正常网页、过期域名,若是正常网页,则判定为失陷域名,否则视为有效恶意域名,而过期的域名不会作为有效的情报。
此外,MDDE-core判定为灰的低危域名中,依然存在着有价值的情报,这部分域名IOC主要来源于MDDE-core判灰的头部数据中,这部分头部数据经过了专家规则扫描过滤,再通过人工运营来判定黑白。
5.2 白名单生产
对于检测为白的域名,MDDE会进一步基于规则来判定其是否可以加入白名单情报。首先,会获得该域名的广度,只有域名有足够的广度,才能加入白名单,其次,网页分类模型判定其是否为一个正常网页、或过期域名,只有当具有一定广度的正常网页,才能作为域名白名单情报。
5.3 情报标签
网页分类模型严格来说是基于规则和模型的网页分类器组件,它对网页源码建模,主要识别网页是否为以下两组类型:过期、正常网页和非正常网页;色情、赌博、矿池。两组类别组内互斥。色情、赌博、矿池可用于丰富情报标签。这其中包含网页分类知识库的挖掘构建,如域名注册站点的挖掘。
5.4 开源情报评估
在威胁情报的生产过程中,开源情报的评估入库是非常重要的一项内容。当有大批量的开源恶意域名需要评估时,MDDE可以对情报进行评估报告,评估可疑域名集的威胁指数:高、中、低。通过评估报告,为开源情报的处理提供有效建议。
06
结果反馈与迭代
MDDE的整个开发过程是迭代反复的,通过专家经验、统计分析、误报分析来评估整个MDDE的性能,从而扩充建模特征、优化专家规则、调整处理流程等,在此基础上,积累高质量的标注数据,从而让域名的检测更快更轻更智能。

07
总结
作为目前整个威胁情报检测和运营体系流程中的精小一环,恶意域名检测引擎的实现,极大的简化了威胁情报中恶意域名的发现、检测和评估,提高了情报检测、运营的效率。但需要注意的是,即使现有特征数据的多样性在业界无出其右,但对于恶意域名检测这样一个难度较高的机器学习任务而言,依然需要更全备的数据信息和知识,才有可能实现域名检测的真正智能化、自动化。
致谢
由衷感谢腾讯威胁情报开源项目组对本文的支持。参考
[1] Zhauniarovich Y, Khalil I, Yu T, et al. A survey on malicious domains detection through DNS data analysis[J]. ACM Computing Surveys (CSUR), 2018, 51(4): 1-36.
[2] Woodbridge J, Anderson H S, Ahuja A, et al. Predicting domain generation algorithms with long short-term memory networks[J]. arXiv preprint arXiv:1611.00791, 2016.
[3] Fu Y, Yu L, Hambolu O, et al. Stealthy domain generation algorithms[J]. IEEE Transactions on Information Forensics and Security, 2017, 12(6): 1430-1443.
[4] Manadhata P K, Yadav S, Rao P, et al. Detecting malicious domains via graph inference[C]//European Symposium on Research in Computer Security. Springer, Cham, 2014: 1-18.
[5] https://www.aqniu.com/news-views/28754.html